NVIDIA NIM是一套易于使用的推理微服务,旨在加速企业中性能优化的生成式 AI 模型的部署。
NIM 推理微服务可以部署在任何地方,从工作站和本地到云,提供企业控制自己的部署选择并确保数据安全。它还提供行业领先的延迟和吞吐量,实现经济高效的扩展,并为最终用户提供无缝体验。
我们可以访问适用于 Llama 3 8B Instruct 和 Llama 3 70B Instruct 模型的 NIM 推理微服务,以便在任何 NVIDIA 加速的基础设施上进行自托管部署。包含用于训练、自定义、检索增强生成(RAG)、guardrails、toolkits、数据 curation 和模型预训练的工具。

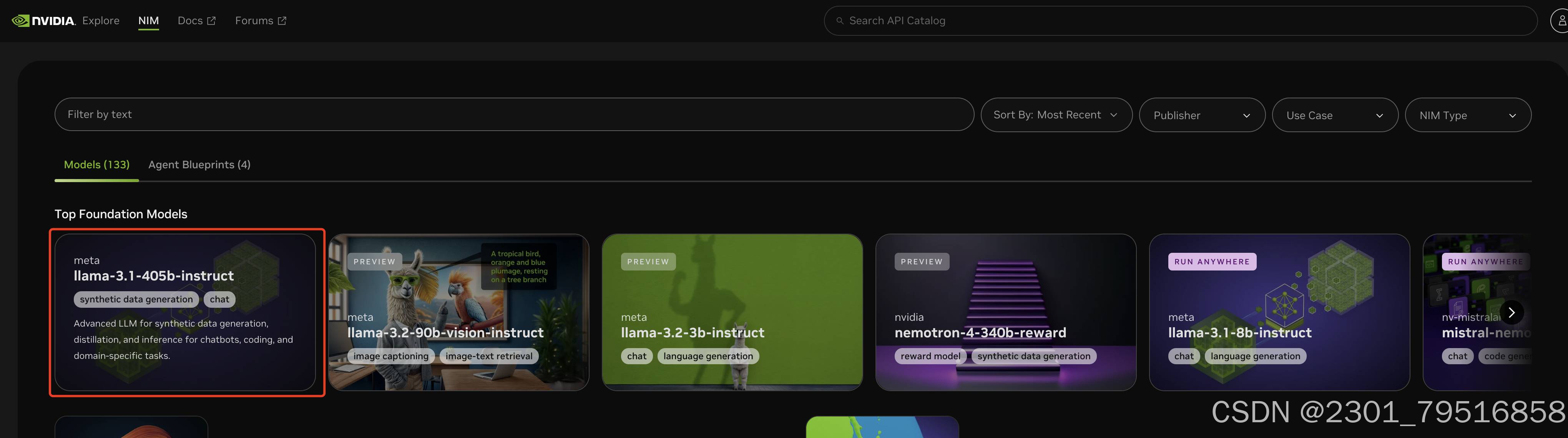
点击“Try Now”即可跳转到一个NIM平台的列表中,可以看到有大概133个Models,非常的多,而且可以自己在分类中搜索想要的分类,可以查看一下每个模型的详情,在这个界面我们能看到多种基于 NIM 平台的AI模型,接下来我们将介绍其中之一的大语言模型,构建我们的知识问答系统。
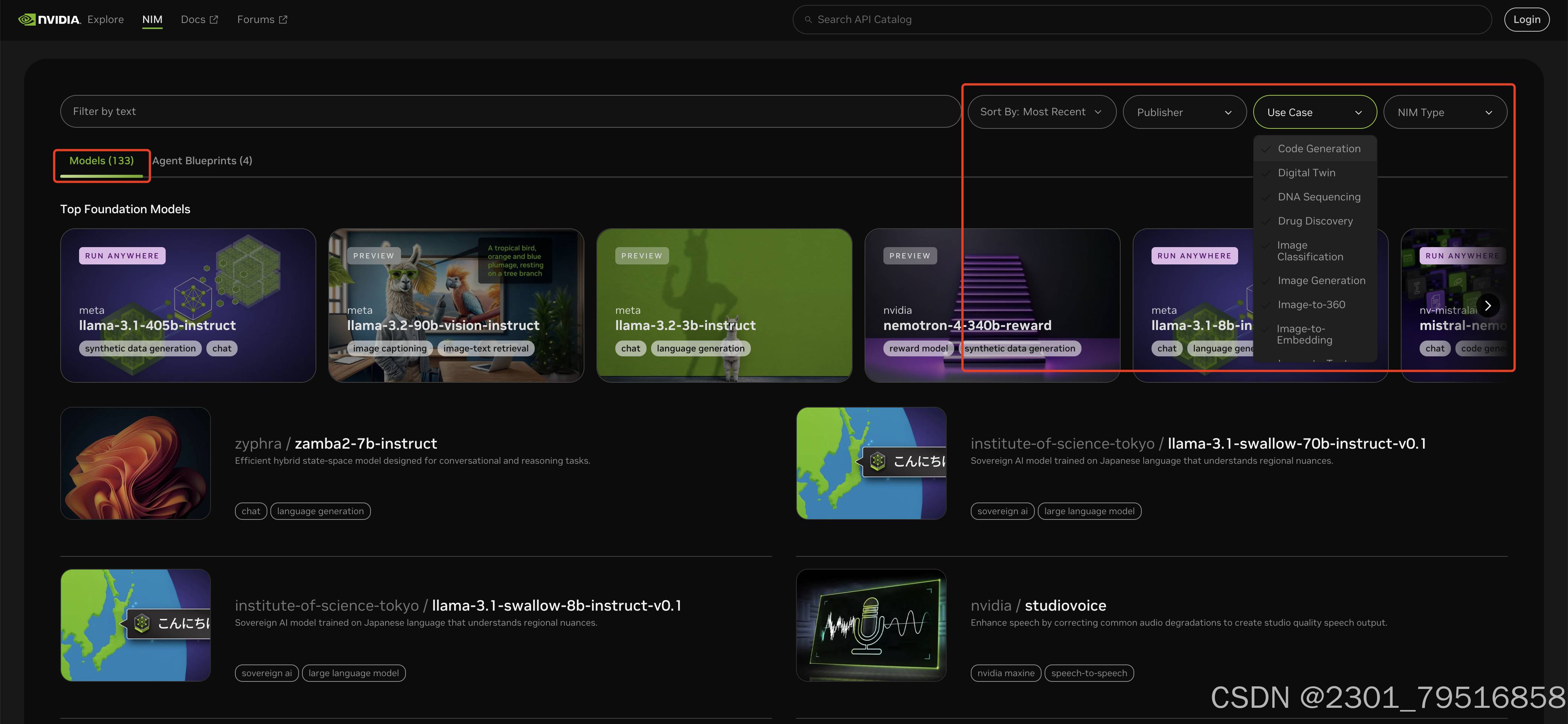
点击Login,通过邮箱注册注意一下邮箱接收一下验证码之后,验证完成之后:
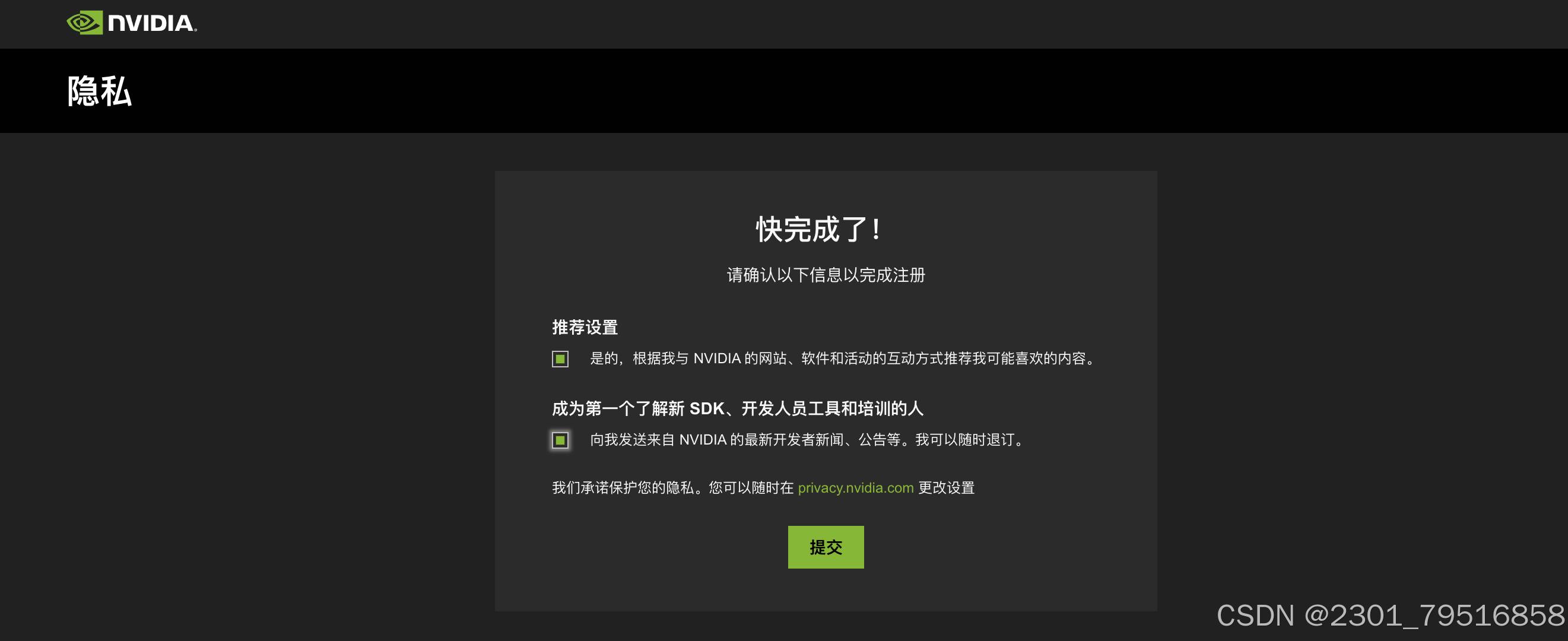
弹框一个界面,需要填写用户名,填写完成用户名后,点击创建新账户即可。
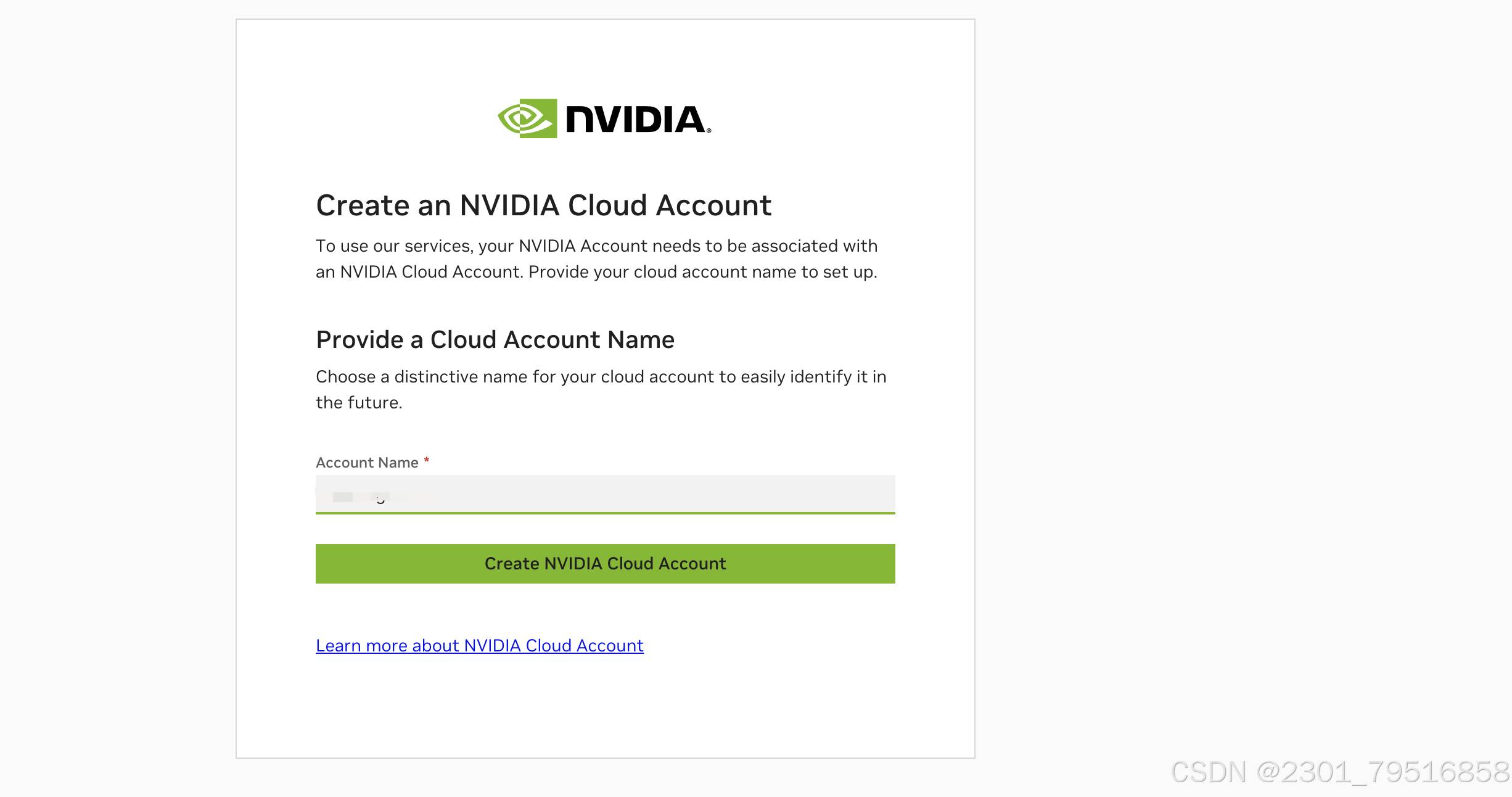
注册成功后,可以在右上角查看我们的免费的次数:
创建成功后,将会返回 NIM 平台的主页面,到这里您就用有了 NVIDIA云账户 。再次点击右上角按钮,可以看到剩余免费额度,点击Request More 可以进行企业用户认证,获取更多使用额度
以上就是账号的注册,可以看到只需要简单的邮箱几步就可以完成注册的功能。
接下来,需要使用到python语言,提前需要具备一下python的知识,这里我们通过pyCharm来进行创建一个python的项目:
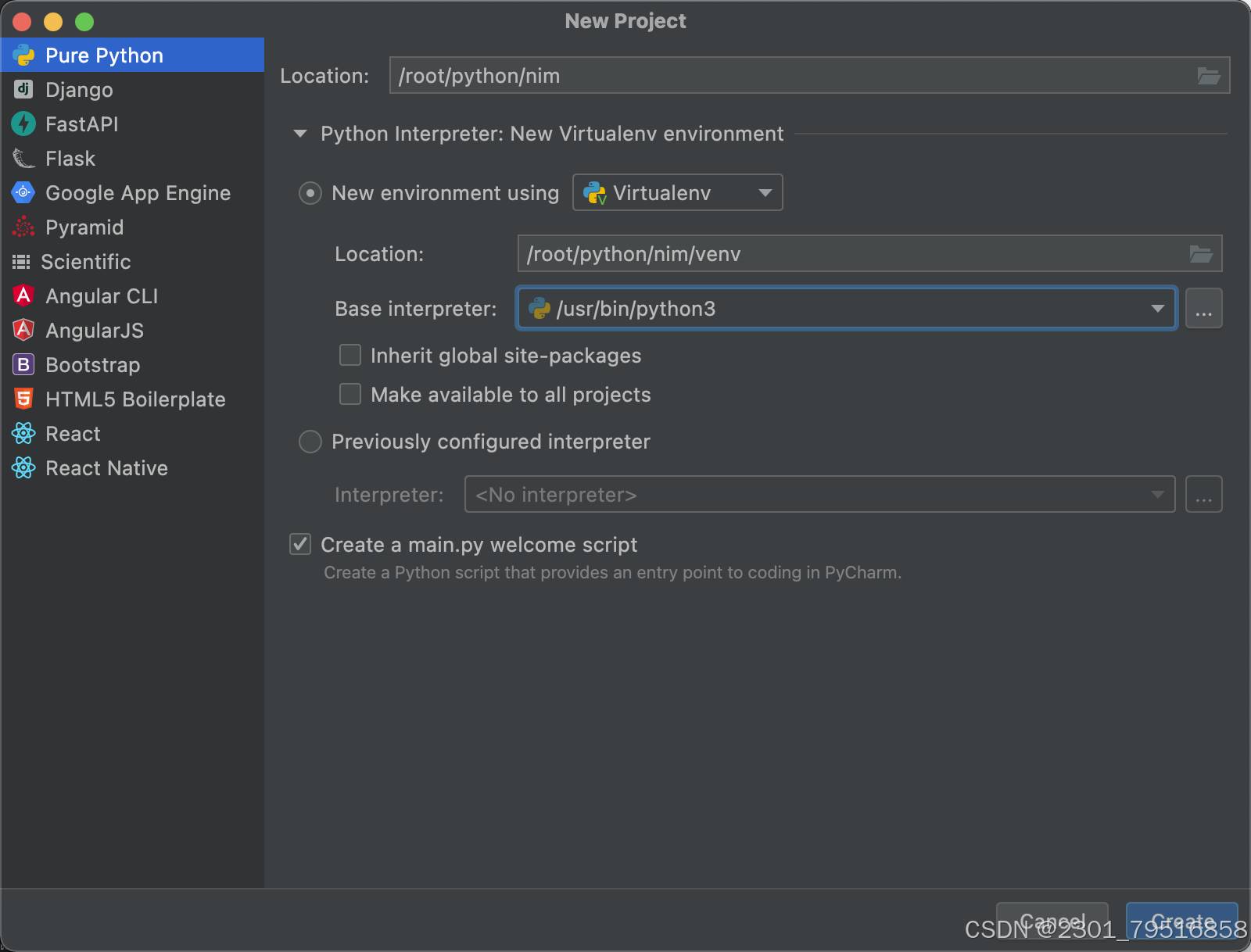
创建成功后,因为运行python代码需要进行安装库与依赖包,需要安装以下库和依赖包:
pip install langchain_nvidia_ai_endpoints langchain-community langchain-text-splitters faiss-cpu gradio==3.50.0 setuptools beautifulsoup4
安装完后成,创建一个python文件,里面的内容:
# -*- coding: utf-8 -*-
# 导入必要的库
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings, ChatNVIDIA
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import chain
import os
import gradio as gr
from datetime import datetime
# Even if you do not know the full answer, generate a one-paragraph hypothetical answer to the below question in Chinese
# 定义假设性回答模板
hyde_template = """Even if you do not know the full answer, generate a one-paragraph hypothetical answer to the below question:
{question}"""
# 定义最终回答模板
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
# 定义函数来处理问题
def process_question(url, api_key, model_name, question):
# 初始化加载器并加载数据
loader = WebBaseLoader(url)
docs = loader.load()
# 设置环境变量
os.environ['NVIDIA_API_KEY'] = api_key
# 初始化嵌入层
embeddings = NVIDIAEmbeddings()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)
retriever = vector.as_retriever()
# 初始化模型
model = ChatNVIDIA(model=model_name)
# 创建提示模板
hyde_prompt = ChatPromptTemplate.from_template(hyde_template)
hyde_query_transformer = hyde_prompt | model | StrOutputParser()
# 定义检索函数
@chain
def hyde_retriever(question):
hypothetical_document = hyde_query_transformer.invoke({"question": question})
return retriever.invoke(hypothetical_document)
# 定义最终回答链
prompt = ChatPromptTemplate.from_template(template)
answer_chain = prompt | model | StrOutputParser()
@chain
def final_chain(question):
documents = hyde_retriever.invoke(question)
response = ""
for s in answer_chain.stream({"question": question, "context": documents}):
response += s
return response
# 调用最终链获取答案
return str(datetime.now())+final_chain.invoke(question)
# 定义可用的模型列表
models = ["mistralai/mistral-7b-instruct-v0.2","meta/llama-3.1-405b-instruct"]
# 启动Gradio应用
iface = gr.Interface(
fn=process_question,
inputs=[
gr.Textbox(label="输入需要学习的网址"),
gr.Textbox(label="NVIDIA API Key"),
gr.Dropdown(models, label="选择语言模型"),
gr.Textbox(label="输入问题")
],
outputs="text",
title="网页知识问答系统"
)
# 启动Gradio界面
iface.launch()
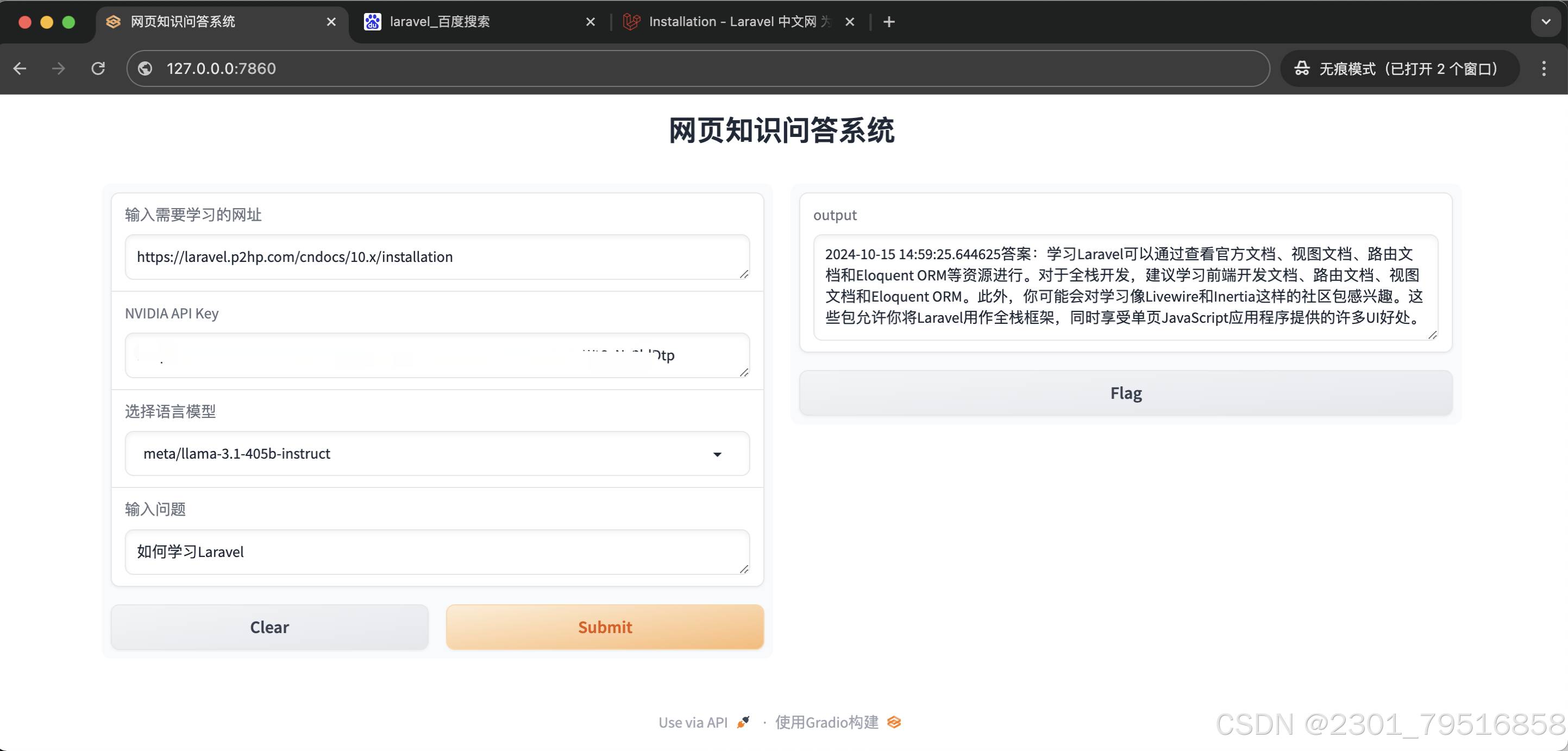
这是一个基于NVIDIA语言模型和网页数据的知识问答系统。用户可以输入需要学习的网址和NVIDIA API密钥,选择适合的语言模型并输入问题,系统将基于提供的网页数据和问题生成假设性的回答,并返回最终的结果。用户可以在界面上直接与系统交互,获取问题的答案。
上面的代码是一个基于Gradio和NVIDIA语言模型的知识问答系统。让我来逐步解释每部分的内容:
整个代码实现了一个用户友好的网页知识问答系统,用户可以通过输入问题,获取基于提供的网页数据和NVIDIA语言模型的答案。Gradio提供了一个直观的界面,使用户能够轻松地与系统交互。
随便找一个模型,例如我这里使用的是meta / llama-3.1-405b-instruct模型,点击这个模型:
详情里面,可以看到提供了不少语言的Demo示例,比如我们这里常用的python代码,点击“Get API Key”即可获取相关的key Code,
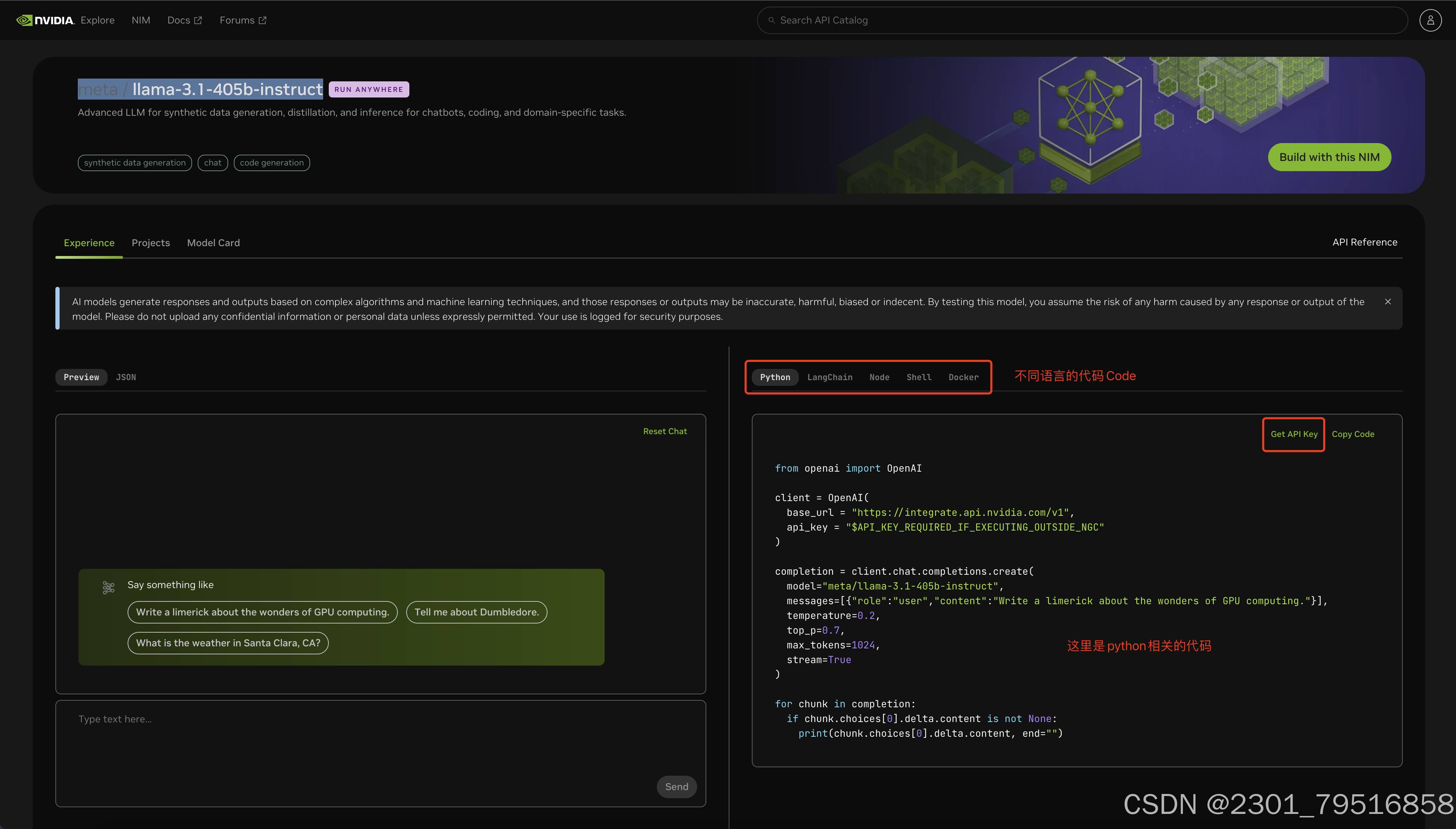
生成的Code点击Copy一下就行:
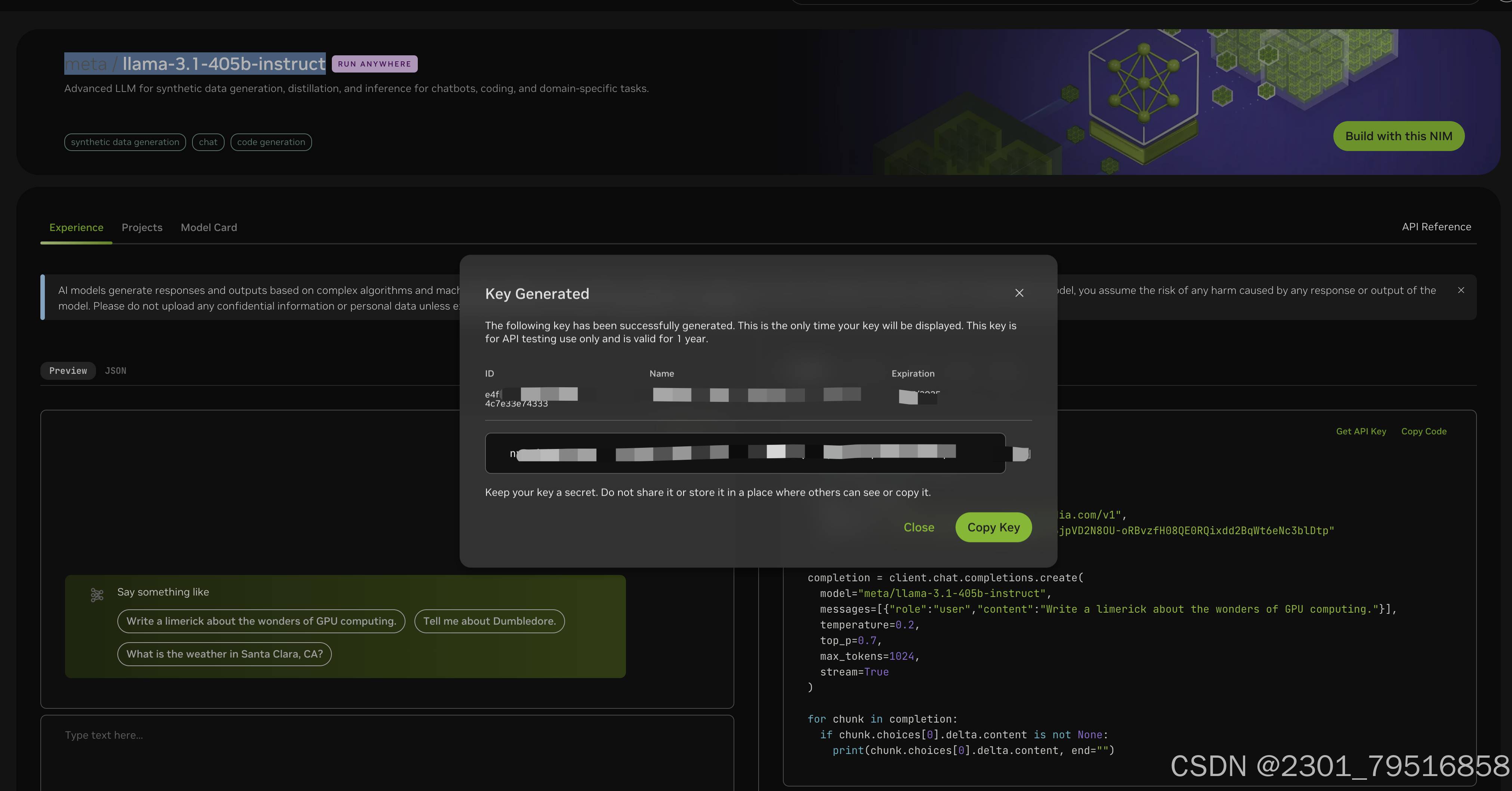
在打开的浏览器中填入上面复制的 API 密钥、需要学习的网页地址、使用的语言模型以及提出的问题后,点击submit,等待一段时间 即可看到回答的信息。
BluePrint
申请地址
https://build.nvidia.com/google/google-deplot?snippet_tab=Python
模型介绍
将统计图表转换为数据结构json格式
# 导入requests库和base64编码库
import requests, base64
# 设置推理URL和流式传输标志
invoke_url = "https://ai.api.nvidia.com/v1/vlm/google/deplot"
stream = True
# 以二进制模式打开图像文件并进行base64编码
with open("economic-assistance-chart.png", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
# 确保编码后的图像大小小于180,000字节,否则需要使用资产API
assert len(image_b64) < 180_000, \
"To upload larger images, use the assets API (see docs)"
# 准备请求头,需要API密钥进行身份验证
headers = {
"Authorization": "Bearer $API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC",
"Accept": "text/event-stream" if stream else "application/json"
}
# 准备请求负载,包含用户消息、最大令牌数、温度等参数
payload = {
"messages": [
{
"role": "user",
"content": f'Generate underlying data table of the figure below: <img src="data:image/png;base64,{image_b64}" />'
}
],
"max_tokens": 1024,
"temperature": 0.20,
"top_p": 0.20,
"stream": stream
}
# 发送POST请求到指定的推理URL
response = requests.post(invoke_url, headers=headers, json=payload)
# 根据是否开启流式传输,处理响应
if stream:
for line in response.iter_lines():
if line:
print(line.decode("utf-8"))
else:
print(response.json())
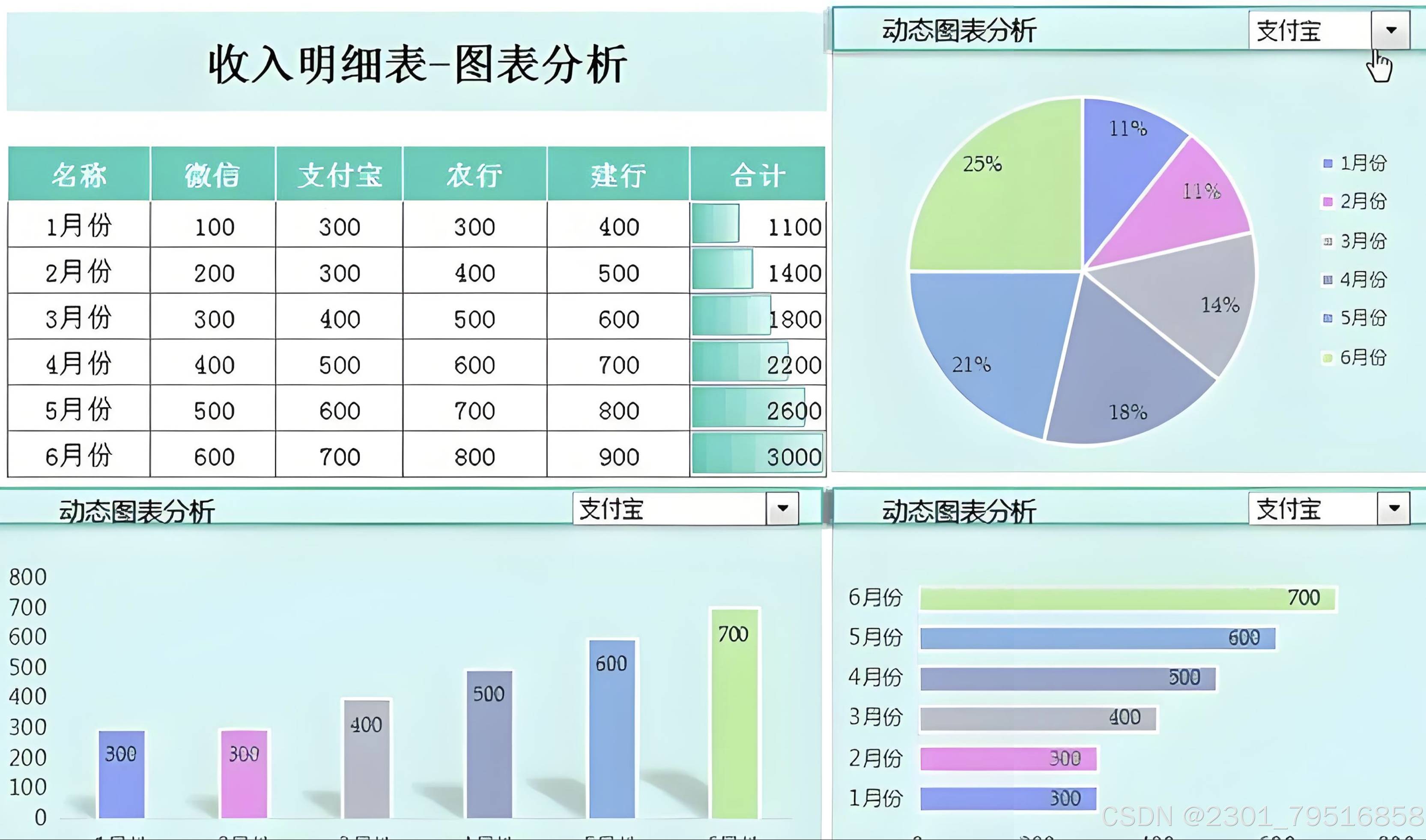
使用一张图表:
在上传大图片时,需要注意一下,有容量限制一下:

Traceback (most recent call last):
File "test1.py", line 13, in <module>
assert len(image_b64) < 180_000, \
AssertionError: To upload larger images, use the assets API (see docs)

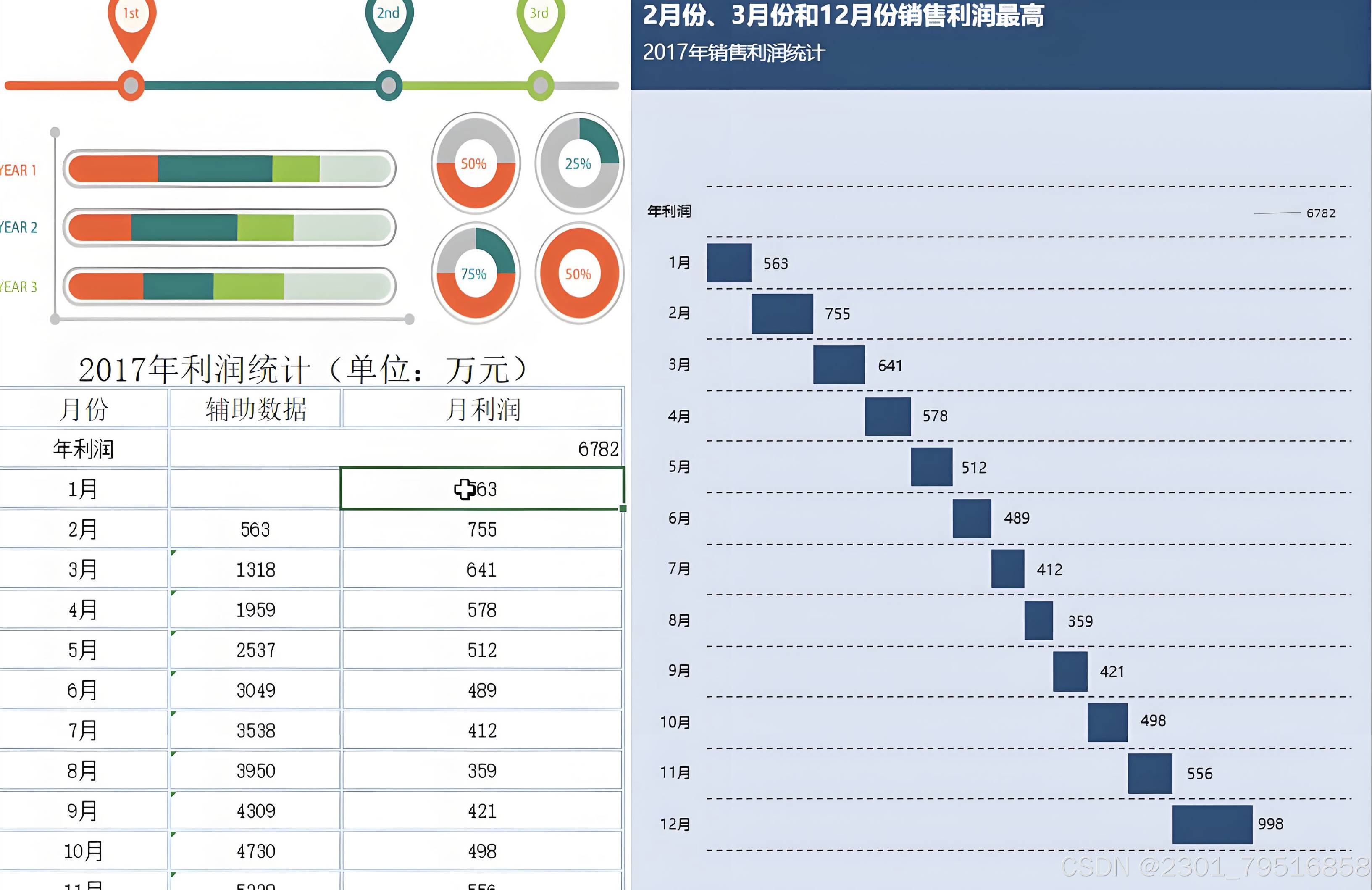
可以看到从文字类的图表excel也是可以识别到的:


版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码