

多模态命名实体识别(MNER)最近引起了广泛关注。 用户在社交媒体上生成大量非结构化内容,主要由图像和文本组成。这些帖子具有与社交媒体相关的固有特征,包括简洁和非正式的写作风格。 这些独特的特征对传统的命名实体识别(NER)方法提出了挑战。
社交媒体上的多模态命名实体识别(MNER)旨在通过结合基于图像的线索来增强文本实体预测。 现有的研究主要集中在最大限度地利用相关图像信息或结合显式知识库中的外部知识。
我的模型主要分为两个阶段。在生成辅助细化知识的阶段,我利用一组有限的预定义人工样本,并采用多模态相似示例感知模块来仔细选择相关实例。然后,将这些选定的示例合并到格式正确的提示中,从而增强为 ChatGPT 提供的启发式指导,以获取精炼的知识。
任务公式化
上下文学习

虽然GPT-4可以接受多模态信息输入,但这一功能仅处于内部测试阶段,尚未公开使用。此外,与ChatGPT相比,GPT-4的成本更高,API请求速度较慢。为了提高可复现性,我们仍然选择ChatGPT作为主要的研究对象,并且提供的这一范式也可以用于GPT-4。
为了使ChatGPT能够完成图文多模态任务,使用了先进的多模态预训练模型将图像转换为图像说明。最后将测试输入x设计为以下模板:

预定义的人工样本
使ChatGPT在MNER任务中表现更好的关键在于选择合适的上下文示例。获取准确标注的上下文示例,这些示例能够精确反映数据集的标注风格并提供扩展辅助知识的途径,是一个显著的挑战。直接从原始数据集中获取这些示例并不可行。为了解决这个问题,我采用了随机抽样的方法,从训练集中选择一小部分样本进行人工标注。具体来说,对于Twitter-2017数据集,从训练集中随机抽取200个样本进行人工标注,而对于Twitter-2015数据集,数量为120。标注过程包括两个主要部分。第一部分是识别句子中的命名实体,第二部分是综合考虑图像和文本内容以及相关知识,提供全面的理由说明。在标注过程中遇到的多种情况中,标注者需要从人类的角度正确判断并解释样本。对于图像和文本相关的样本,我们直接说明图像中强调了文本中的哪些实体。对于图像和文本无关的样本,我们直接声明图像描述与文本无关。通过人工标注过程,强调了句子中的实体及其对应的类别。此外,引入了相关的辅助知识来支持这些判断。这个细致的标注过程为ChatGPT提供了指导,使其能够生成高度相关且有价值的回答。
多模态相似示例感知模块
由于GPT的少样本学习能力在很大程度上取决于上下文示例的选择,我设计了多模态相似示例感知(MSEA)模块来选择合适的上下文示例。作为一个经典的多模态任务,MNER的预测依赖于文本和视觉信息的整合。因此,我们将文本和图像的融合特征作为评估相似示例的基本标准。而这种多模态融合特征可以从之前的多模态命名实体识别(MNER)模型中获得。将MNER数据集D和预定义的人工样本
G
在以往的研究中,经过交叉注意力投射到高维潜在空间的融合特征H会直接输入到解码层,以进行结果预测。我们的模型选择HH作为相似示例的判断依据,因为在高维潜在空间中相近的示例更有可能具有相同的映射方式和实体类型。计算测试输入与每个预定义人工样本的融合特征H的余弦相似度。然后,选择前N个相似的预定义人工样本作为上下文示例,以启发ChatGPT生成辅助的精炼知识:

为了高效实现相似示例的感知,所有的多模态融合特征可以提前计算并存储。
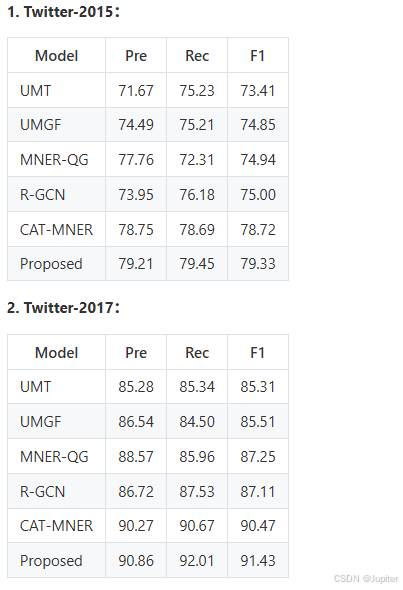
我们在两个公共 MNER 数据集上进行了实验:Twitter-2015和 Twitter-2017。这两个数据集都是从Twitter平台上收集的,包含了文本和图像的配对信息,主要用于研究在社交媒体短文本场景下的多模态命名实体识别和情感分析等任务。、
在下载附件并准备好数据集并调试代码后,进行下面的步骤,附件已经调通并修改,可直接正常运行;
环境要求
python == 3.7
torch == 1.13.1
transformers == 4.30.2
modelscope == 1.7.1
我们的项目基于AdaSeq, AdaSeq项目基于Python版本>= 3.7和PyTorch版本>= 1.8。
下载
git clone https://github.com/modelscope/adaseq.git
cd adaseq
pip install -r requirements.txt -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
python -m scripts.train -c examples/ER/twitter-15.yaml
python -m scripts.train -c examples/ER/twitter-17.yaml

版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码