MediaPipe Pose 中的地标模型预测了 33 个姿势地标的位置
# 安装opencv
pip install opencv-contrib-python
# 安装mediapipe
pip install mediapipe
#pip install -i https://pypi.tuna.tsinghua.edu.cn/simple mediapipe==0.8.8
#有user报错的话试试这个,我也是发现这个库包版本过高并不会提示,而是在编译器乱报错懵了很久。
# 安装之后导入各个包
import cv2 #已经在opencv-python包含了
import mediapipe as mp
import time
从mediapipe中导入检测方法,今天我们使用mediapipe.solutions.pose。
mediapipe.solutions.hands # 手部关键点检测
mediapipe.solutions.pose # 人体姿态检测
mediapipe.solutions.face_mesh # 人脸网状检测
mediapipe.solutions.face_detection # 人脸识别
....................
(1)mediapipe.solutions.pose.Pose() 姿态关键点检测函数
参数:
static_image_mode: 默认为 False,将输入图像视为视频流。它将尝试在第一张图像中检测最突出的人,并在成功检测后进一步定位姿势地标。在随后的图像中,它只是简单地跟踪那些地标,而不会调用另一个检测,直到失去对目标的跟踪,可以减少计算和延迟。若为 True,则会对每张输入图像执行人体检测方法,非常适合处理一批静态的、可能不相关的图像。
model_complexity: 默认为 1,姿势地标模型的复杂度:0、1 、2。地标准确度和推理延迟通常随着模型复杂度的增加而增加。
smooth_landmarks: 默认为 True,平滑图像,过滤不同的输入图像上的姿势地标以减少抖动,但如果static_image_mode也设置为 True 则忽略。
upper_body_only: 默认为 False,是否只检测上半身的地标。人体姿势共有33个地标,上半身的姿势地标有25个。
enable_segmentation: 默认为False。如果设置为 true,除了姿势地标之外,该解决方案还会生成分割掩码。
smooth_segmentation:默认为 True,过滤不同的输入图像上的分割掩码以减少抖动,但如果 enable_segmentation 设置为 False,或者 static_image_mode 设置为 True 则忽略。
min_detection_confidence: 默认为 0.5,来自人员检测模型的最小置信值 (0-1之间),高于该阈值则认为检测视为成功。
min_tracking_confidence:默认为 0.5。来自地标跟踪模型的最小置信值 (0-1之间),用于将被视为成功跟踪的姿势地标,否则将在下一个输入图像上自动调用人物检测。将其设置为更高的值可以提高解决方案的稳健性,但代价是更高的延迟。如果 static_image_mode 为 True,则人员检测将在每帧图像上运行。
返回值:
具有 "pose_landmarks" 字段的 NamedTuple 对象,其中包含检测到的最突出人物的姿势坐标。
(2)mediapipe.solutions.drawing_utils.draw_landmarks() 绘制手部关键点的连线
参数:
image: 需要画图的原始图片
landmark_list: 检测到的手部关键点坐标
connections: 连接线,需要把那些坐标连接起来
landmark_drawing_spec: 坐标的颜色,粗细
connection_drawing_spec: 连接线的粗细,颜色等
以下是一个简单的绘制人体关键点的代码示例:
# 初始化视频捕获
cap = cv2.VideoCapture("video.mp4") # 替换为您的视频路径
mp_pose = mp.solutions.pose
mp_drawing = mp.solutions.drawing_utils
with mp_pose.Pose(model_complexity=1, enable_segmentation=True) as pose:
while cap.isOpened():
success, img = cap.read()
if not success:
break
# 转换图像格式为 RGB
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 检测姿态
results = pose.process(img_rgb)
# 绘制姿态关键点和连线
if results.pose_landmarks:
mp_drawing.draw_landmarks(img, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
# 显示视频
cv2.imshow('Pose Detection', img)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
使用cv2.VideoCapture()读取视频文件时,文件路径最好不要出现中文,防止报错。
变量.read() 每次执行就从视频中提取一帧图片,需要循环来不断提取。用success来接收是否能打开,返回True表示可以打开。img保存返回的的每一帧图像。
由于读入视频图像通道一般为RGB,而opencv中图像通道的格式为BGR,因此需要cv2.cvtColor()函数将opencv读入的视频图像转为RGB格式 cv2.COLOR_BGR2RGB。
在绘制人体关键点时 mpDraw.draw_landmarks();results.pose_landmarks 获取所有关键点信息;如果不传入参数mpPose.POSE_CONNECTIONS,那么就不会绘制关键点之间的连线 。
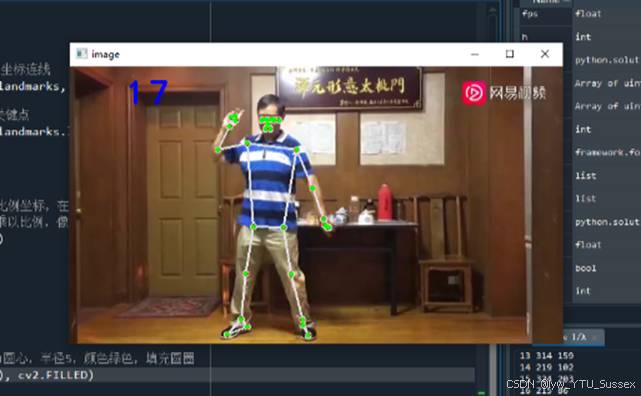
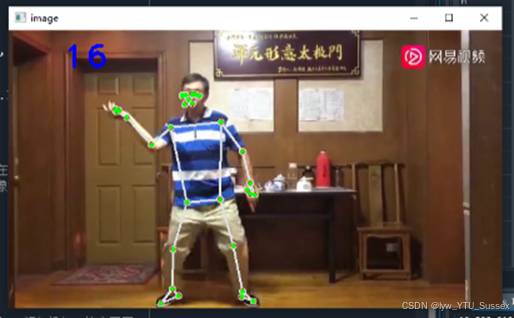
绘制人体33个关键点及连线


接下来,我们将33个关键点的坐标保存下来,并将这些关键点放大一些,使其更加明显。因此我们补充上面的代码。在获取到 pose_landmarks 后,我们可以将其归一化的坐标转换为像素坐标,并将这些点绘制出来。如下代码是一个简单的示例,展示了如何将坐标放大并保存到列表中:
# 获取图像尺寸
img_height, img_width, _ = img.shape
lmlist = []
if results.pose_landmarks:
for id, lm in enumerate(results.pose_landmarks.landmark):
x, y = int(lm.x * img_width), int(lm.y * img_height)
lmlist.append((x, y))
# 绘制放大的关键点
cv2.circle(img, (x, y), 5, (0, 255, 0), cv2.FILLED)
# 打印每帧的关键点坐标
print(lmlist)
由于 results.pose_landmarks.landmark 中保存的xyz坐标是归一化后的比例坐标,即某一像素点在图像的某一比例位置,如[0.5, 0.5]。我们需要将其转为像素坐标,如[200,200],像素坐标一定是整数。通过图像宽高乘以各自比例即可得到像素坐标下的宽高。为了能更明显的显示关键点,把关键点画的大一些,只需以关键点的像素坐标为圆心画圆cv2.circle()即可。将像素坐标保存到lmlist中。
结果如下,右下输出框打印每一帧图像的关键点的xy坐标信息:
大功告成,本次小项目分享就到这里了,喜欢的友友记得点赞+关注+收藏哦~~~
完整代码,拿去选择你的视频路径跑就行,包的老弟
import cv2
import mediapipe as mp
import time
# 导入姿态跟踪方法
mpPose = mp.solutions.pose # 姿态识别方法
pose = mpPose.Pose(static_image_mode=False, # 静态图模式,False代表置信度高时继续跟踪,True代表实时跟踪检测新的结果
#upper_body_only=False, # 是否只检测上半身
smooth_landmarks=True, # 平滑,一般为True
min_detection_confidence=0.5, # 检测置信度
min_tracking_confidence=0.5) # 跟踪置信度
# 检测置信度大于0.5代表检测到了,若此时跟踪置信度大于0.5就继续跟踪,小于就沿用上一次,避免一次又一次重复使用模型
# 导入绘图方法
mpDraw = mp.solutions.drawing_utils
#(1)导入视频
filepath = 'C:\\GameDownload\\Deep Learning\\master.mp4'
cap = cv2.VideoCapture(filepath)
pTime = 0 # 设置第一帧开始处理的起始时间
#(2)处理每一帧图像
lmlist = [] # 存放人体关键点信息
while True:
# 接收图片是否导入成功、帧图像
success, img = cap.read()
# 将导入的BGR格式图像转为RGB格式
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 将图像传给姿态识别模型
results = pose.process(imgRGB)
# 查看体态关键点坐标,返回x,y,z,visibility
# print(results.pose_landmarks)
# 如果检测到体态就执行下面内容,没检测到就不执行
if results.pose_landmarks:
# 绘制姿态坐标点,img为画板,传入姿态点坐标,坐标连线
mpDraw.draw_landmarks(img, results.pose_landmarks, mpPose.POSE_CONNECTIONS)
# 获取32个人体关键点坐标, index记录是第几个关键点
for index, lm in enumerate(results.pose_landmarks.landmark):
# 保存每帧图像的宽、高、通道数
h, w, c = img.shape
# 得到的关键点坐标x/y/z/visibility都是比例坐标,在[0,1]之间
# 转换为像素坐标(cx,cy),图像的实际长宽乘以比例,像素坐标一定是整数
cx, cy = int(lm.x * w), int(lm.y * h)
# 打印坐标信息
print(index, cx, cy)
# 保存坐标信息
lmlist.append((cx, cy))
# 在关键点上画圆圈,img画板,以(cx,cy)为圆心,半径5,颜色绿色,填充圆圈
cv2.circle(img, (cx,cy), 3, (0,255,0), cv2.FILLED)
# 查看FPS
cTime = time.time() #处理完一帧图像的时间
fps = 1/(cTime-pTime)
pTime = cTime #重置起始时间
# 在视频上显示fps信息,先转换成整数再变成字符串形式,文本显示坐标,文本字体,文本大小
cv2.putText(img, str(int(fps)), (70,50), cv2.FONT_HERSHEY_PLAIN, 3, (255,0,0), 3)
# 显示图像,输入窗口名及图像数据
cv2.imshow('image', img)
if cv2.waitKey(10) & 0xFF==27: #每帧滞留15毫秒后消失,ESC键退出
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码