
RAG作为减少模型幻觉和让模型分析、回答私域相关知识最简单高效的方式,我们除了使用之外可以尝试了解其是如何实现的。在实现RAG的过程中,最重要的是保证召回的知识的准确性,不然会极大影响LLM的能力,而混合检索是一个重要的方法去提高召回RAG的准确性。
拿最常用的关键词检索举例,它通过匹配用户输入的关键词与文档中的关键词来返回相关结果。然而,关键词检索存在以下几个明显的局限性:
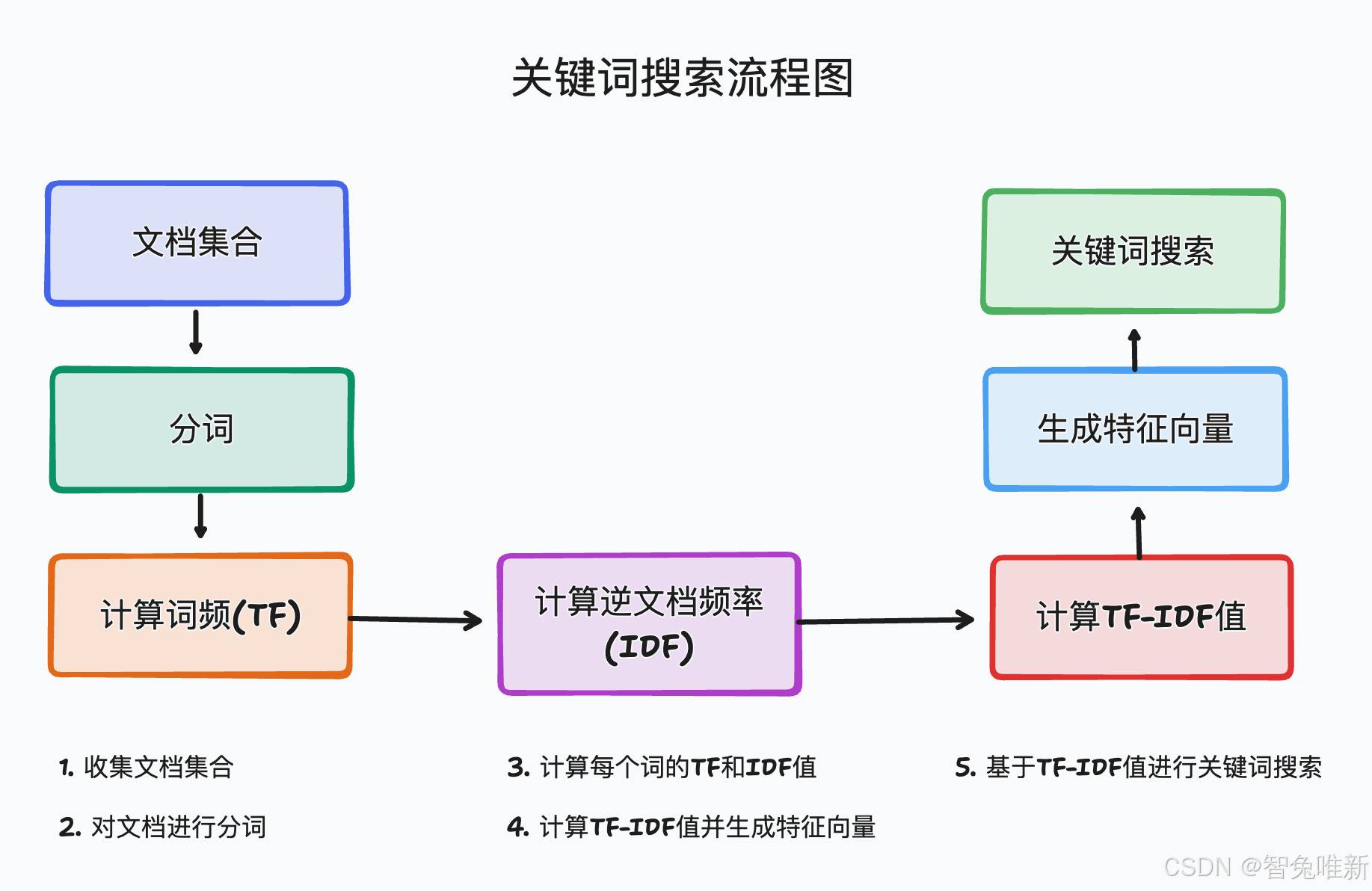
比如下面这段代码,我们使用text1去在text2和text3中匹配最符合的文档:
def main():
"""
主函数,用于测试和演示
"""
text1 = '把商品发到闲鱼'
text2 = '我想将商品挂到闲鱼'
text3 = '我想找闲鱼问下商品'
# calculate_tfidf_similarity: 通过两个文本TF-IDF相似度计算相似度
tfidf_similarities2 = calculate_tfidf_similarity(text1, text2)
tfidf_similarities3 = calculate_tfidf_similarity(text1, text3)
print(f"\n匹配句子1得分:{tfidf_similarities2[0]} \n\n匹配句子2得分: {tfidf_similarities3[0]} \n\n")
获取到的结果:
匹配句子2得分:0.8164965809277259
匹配句子3得分:0.8164965809277259
可以看到我们肉眼可见的text1与text2更匹配,但因为三个句子中都包含商品和闲鱼,所以两个句子都匹配到了0.8164965809277259,我们但从关键词匹配根本无法分辨召回哪个文本更好,但是关键词检索并不是一无是处,对很多文档的检索都有关键功能,而在需要保留关键词检索的同时又能分辨这种句子,我们就需要引入语义检索,让他们两种方法工作达到混合检索的功能。
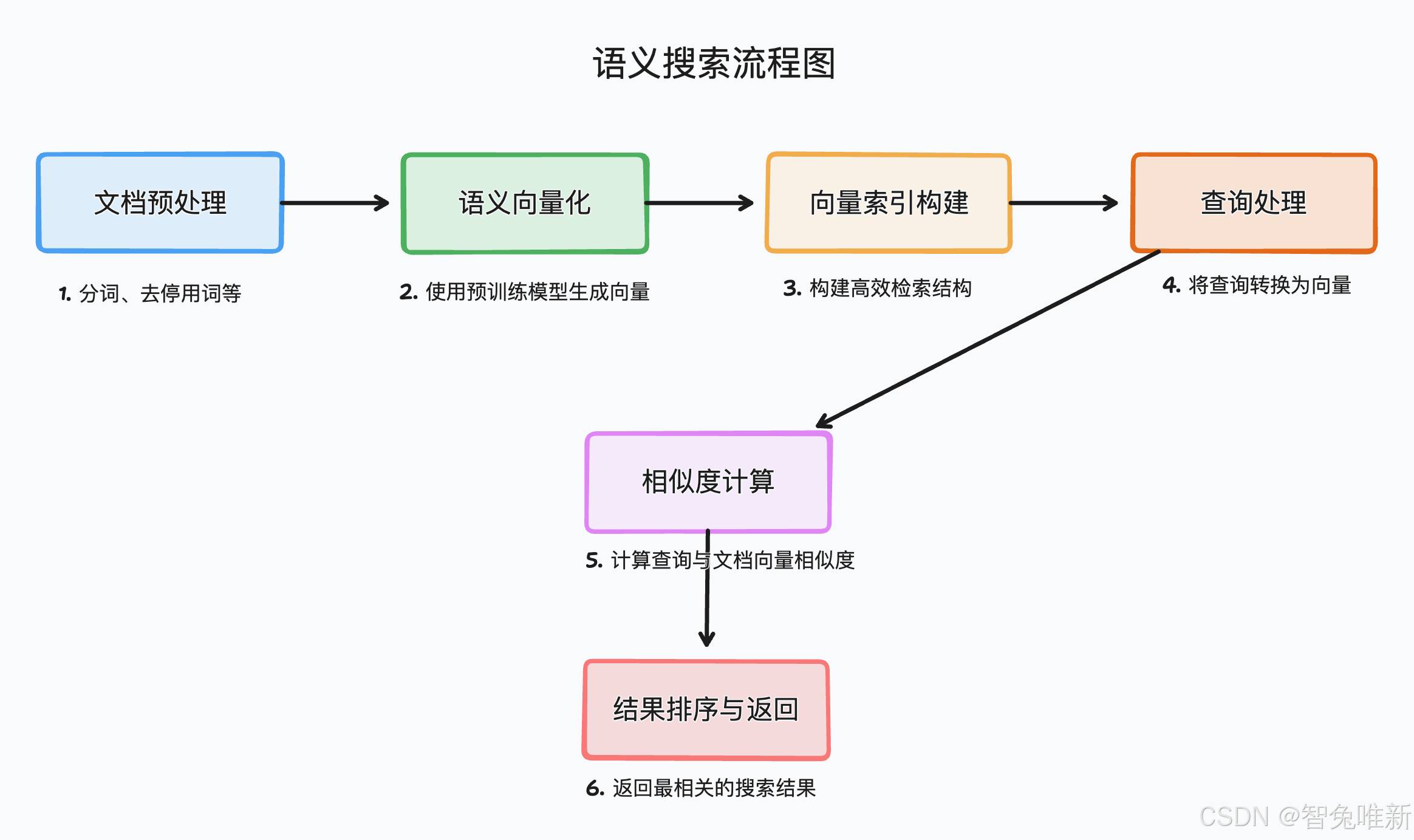
混合检索(Hybrid Retrieval)是一种结合了多种检索方法的策略,旨在提高检索结果的质量和多样性。通过结合不同检索方法的优势,混合检索可以更好地满足用户的需求,并提供更准确、更全面的检索结果。
下面我们来尝试同时引入关键词检索和语义检索。
def main():
"""
主函数,用于测试和演示
"""
text1 = '把商品发到闲鱼'
text2 = '我想将商品挂到闲鱼'
text3 = '我想找闲鱼问下商品'
# 通过两个文本TF-IDF相似度计算相似度
tfidf_similarities2 = calculate_tfidf_similarity(text1, text2)
tfidf_similarities3 = calculate_tfidf_similarity(text1, text3)
# 通过两个文本的嵌入相似度计算相似度
embedding_similarities2 = calculate_similarity(text1, text2)
embedding_similarities3 = calculate_similarity(text1, text3)
print(f"\n\n语义搜索句子1 {embedding_similarities2[0]} \n\n语义搜索句子2: {embedding_similarities3[0]}")
我们先看看语义检索的效果:
语义搜索句子1 ('我想将商品挂到闲鱼', 0.8553742925917707)
语义搜索句子2: ('我想找闲鱼问下商品', 0.6846143988983046)
好的,很明显可以看到在关键词的比较相似的情况下,我们使用语义搜索可以清晰地分出哪个句子更符合我们的需求。接下来我们来将两个搜索结合起来,并进行加权计算得分(让用户可以根据自己需要决定是语义搜索得分更高还是关键词搜索得分更高),从而得到最终的检索结果。
def main():
"""
主函数,用于测试和演示
"""
text1 = '把商品发到闲鱼'
text2 = '我想将商品挂到闲鱼'
text3 = '我想找闲鱼问下商品'
# 通过两个文本TF-IDF相似度计算相似度
tfidf_similarities2 = calculate_tfidf_similarity(text1, text2)
tfidf_similarities3 = calculate_tfidf_similarity(text1, text3)
embedding_similarities2 = calculate_similarity(text1, text2)
embedding_similarities3 = calculate_similarity(text1, text3)
Semantic_Proportio = 0.8
Word_Proportion = 0.2
# 根据传进来的权重计算最终得分
final_score2 = calculate_final_score(embedding_similarities2[0][1], tfidf_similarities2[0], Semantic_Proportio, Word_Proportion)
final_score3 = calculate_final_score(embedding_similarities3[0][1], tfidf_similarities3[0], Semantic_Proportio, Word_Proportion)
print(f"最终语句1得分: {final_score2} \n\n最终语句2得分: {final_score3}")
结果:
最终语句1得分: 0.8475987502589617
最终语句2得分: 0.7109908353041888
ok,可以看到我们通过混合检索的方式,可以更准确地找到与用户输入最相关的文档,从而提高检索结果的质量和准确性。
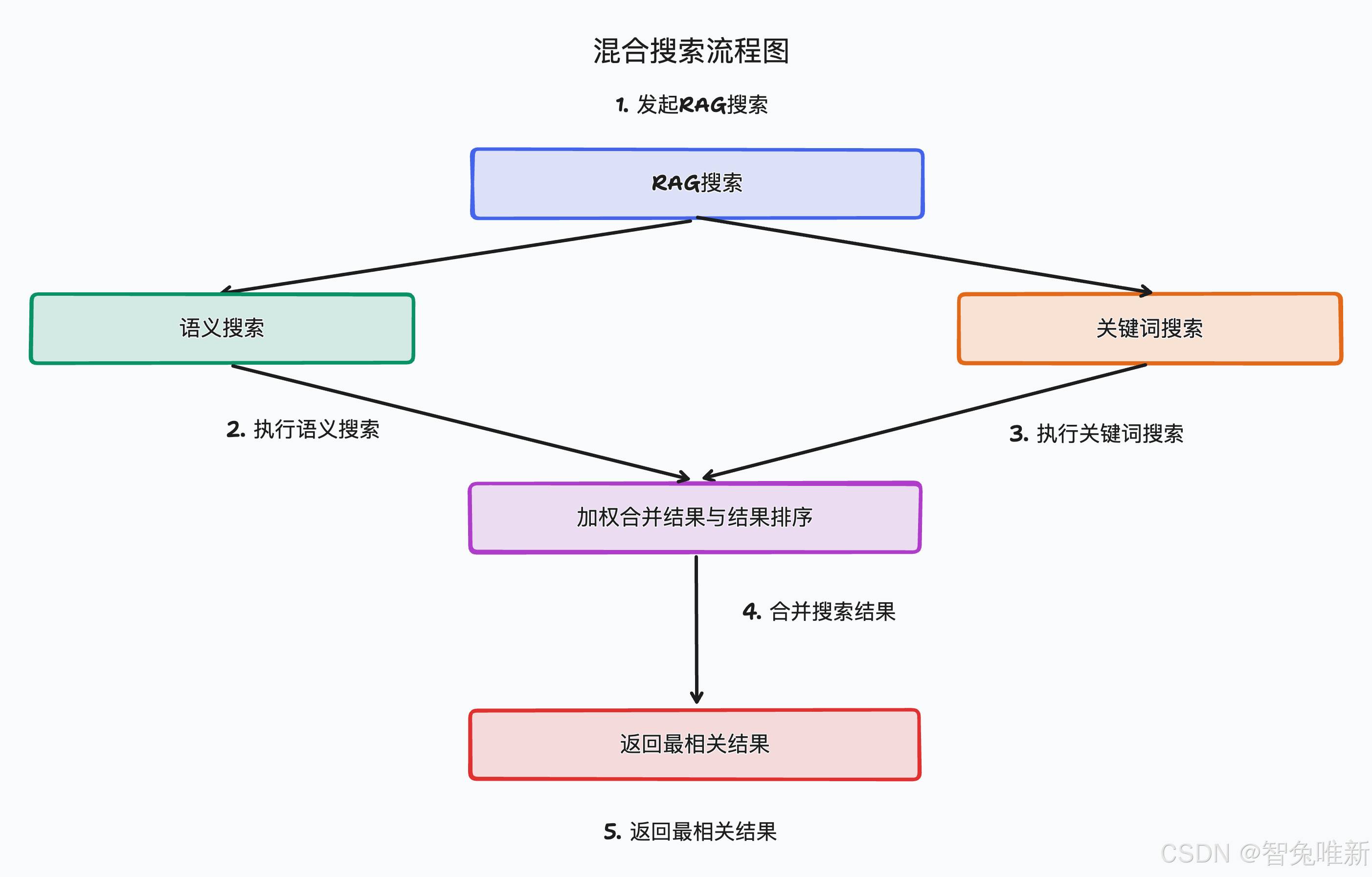
关键词检索和语义检索的详细实现之前我的文章已经提过了,这里不在赘述,直接贴完整代码。注意把key换成qwen中你自己的key
import dashscope
from http import HTTPStatus
import numpy as np
import jieba
from jieba.analyse import extract_tags
import math
# 初始化dashscope,替换qwen的api key
dashscope.api_key = 'sk-xxxx'
def embed_text(text):
"""
使用dashscope API获取文本的嵌入向量
:param text: 输入的文本
:return: 文本的嵌入向量,如果失败则返回None
"""
resp = dashscope.TextEmbedding.call(
model=dashscope.TextEmbedding.Models.text_embedding_v2,
input=text)
if resp.status_code == HTTPStatus.OK:
return resp.output['embeddings'][0]['embedding']
else:
print(f"Failed to get embedding: {resp.status_code}")
return None
def cosine_similarity(vec1, vec2):
"""
计算两个向量之间的余弦相似度
:param vec1: 第一个向量
:param vec2: 第二个向量
:return: 余弦相似度
"""
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2)
def calculate_similarity(text1, text2):
"""
计算两个文本之间的相似度
:param text1: 第一个文本
:param text2: 第二个文本,可以包含多个句子,用逗号分隔
:return: 每个句子的相似度列表,格式为 (句子, 相似度)
"""
embedding1 = embed_text(text1)
if embedding1 is None:
return []
similarities = []
sentences = [sentence.strip() for sentence in text2.split(',') if sentence.strip()]
for sentence in sentences:
embedding2 = embed_text(sentence)
if embedding2 is None:
continue
similarity = cosine_similarity(embedding1, embedding2)
similarities.append((sentence, similarity))
return similarities
def extract_keywords(text):
"""
提取文本中的关键词
:param text: 输入的文本
:return: 关键词列表
"""
return extract_tags(text)
def cosine_similarity_tfidf(vec1, vec2):
"""
计算两个TF-IDF向量之间的余弦相似度
:param vec1: 第一个TF-IDF向量
:param vec2: 第二个TF-IDF向量
:return: 余弦相似度
"""
intersection = set(vec1.keys()) & set(vec2.keys())
numerator = sum(vec1[x] * vec2[x] for x in intersection)
sum1 = sum(vec1[x] ** 2 for x in vec1)
sum2 = sum(vec2[x] ** 2 for x in vec2)
denominator = math.sqrt(sum1) * math.sqrt(sum2)
return numerator / denominator if denominator else 0.0
def calculate_tfidf_similarity(text, text2):
"""
计算两个文本之间的TF-IDF相似度
:param text: 第一个文本
:param text2: 第二个文本,可以包含多个文档,用竖线分隔
:return: 每个文档的TF-IDF相似度列表
"""
documents = [doc for doc in text2.split('|') if doc.strip()]
query_keywords = extract_keywords(text)
documents_keywords = [extract_keywords(doc) for doc in documents]
query_keyword_counts = {kw: query_keywords.count(kw) for kw in set(query_keywords)}
total_documents = len(documents)
all_keywords = set(kw for doc in documents_keywords for kw in doc)
keyword_idf = {kw: math.log((1 + total_documents) / (1 + sum(1 for doc in documents_keywords if kw in doc))) + 1 for kw in all_keywords}
query_tfidf = {kw: count * keyword_idf.get(kw, 0) for kw, count in query_keyword_counts.items()}
documents_tfidf = [{kw: doc.count(kw) * keyword_idf.get(kw, 0) for kw in set(doc)} for doc in documents_keywords]
return [cosine_similarity_tfidf(query_tfidf, doc_tfidf) for doc_tfidf in documents_tfidf]
def calculate_final_score(embedding_similarity, tfidf_similarity, w1=0.5, w2=0.5):
"""
计算最终得分,结合语义相似度和TF-IDF相似度
:param embedding_similarity: 语义相似度
:param tfidf_similarity: TF-IDF相似度
:param w1: 语义相似度的权重
:param w2: TF-IDF相似度的权重
:return: 最终得分
"""
return w1 * embedding_similarity + w2 * tfidf_similarity
def main():
"""
主函数,用于测试和演示
"""
text1 = '把商品发到闲鱼'
text2 = '我想将商品挂到闲鱼'
text3 = '我想找闲鱼问下商品'
tfidf_similarities2 = calculate_tfidf_similarity(text1, text2)
tfidf_similarities3 = calculate_tfidf_similarity(text1, text3)
embedding_similarities2 = calculate_similarity(text1, text2)
embedding_similarities3 = calculate_similarity(text1, text3)
Semantic_Proportio = 0.8
Word_Proportion = 0.2
final_score2 = calculate_final_score(embedding_similarities2[0][1], tfidf_similarities2[0], Semantic_Proportio, Word_Proportion)
final_score3 = calculate_final_score(embedding_similarities3[0][1], tfidf_similarities3[0], Semantic_Proportio, Word_Proportion)
print(f"最终语句1得分: {final_score2} \n\n最终语句2得分: {final_score3}")
if __name__ == '__main__':
main()
混合检索技术通过结合关键词检索和语义检索的优势,实现了多路召回,从而提高了检索的准确性和全面性。掌握上面我们提到的混合检索,不仅你可以根据自己的实际情况去对多种检索方式的权重进行加权,还可以根据自己的实际情况去调整对应的召回策略,对我们自建RAG检索有着极大帮助,希望本文能对你有启示。
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码