生成式 AI 迅速发展的时代,面临着内容安全与系统构建的双重挑战。一方面,基于虚假图片所引发的欺诈事件日益增多,给社会带来了严重的负面影响,因此,我们必须高度关注人工智能的安全性,解决人工智能发展过程中的各种安全挑战,以实现人工智能的持续健康发展。另一方面,训练大模型过程中低质量或不准确的数据会严重影响模型的训练和性能,通过应用性能的智能文档处理,能够自动化数据清洗、格式转换和信息提取,为模型提供高质量的训练数据,推动生成式AI技术的发展。
在本文中,我们将回顾来自合合信息的郭丰俊博士在第七届中国模式识别与计算机视觉大会中关于图像内容安全和智能文档处理推动系统构建加速的思考与探索,并介绍在生成式 AI 时代下文档智能处理技术面临的挑战和研究进展。
近日,第七届中国模式识别与计算机视觉大会 (The 7th Chinese Conference on Pattern Recognition and Computer Vision, PRCV 2024) 在乌鲁木齐成功举办。此次大会由中国自动化学会 (CAA)、中国图象图形学学会 (CSIG)、中国人工智能学会 (CAAI) 和中国计算机学会 (CCF) 共同主办,由新疆大学承办,是国内顶级的模式识别和计算机视觉领域学术盛会。PRCV 2024 汇聚了国内外模式识别和计算机视觉领域的众多科研工作者及工业界同行,交流最新的理论研究成果与技术进展。
此次会议加强了模式识别和计算机视觉领域学术界和企业界进行深入的“产学研”交流与合作,从而进一步推动模式识别与计算机视觉领域的协同创新。

近年来,随着生成式人工智能 (Generative Artificial Intelligence, GAI) 技术的迅猛发展,基于虚假图片所引发的欺诈事件也日益增多,给社会带来了严重的负面影响。这些虚假图像不仅误导了公众的认知,还可能对个人、企业和社会造成经济损失和信任危机。因此,确保图像内容的安全性变得尤为重要。在计算机视觉领域,研究和发展能够识别和防范虚假图像的技术,已成为一个紧迫的课题。随着生成伪造图像问题的日益突出,图像内容安全的研究将为保护信息真实性和维护社会信任提供重要支持。
另一方面,智能文档处理系统基于自然语言处理 (Natuarl Language Processing, NLP) 和机器学习 (Machine Learning, ML) 算法,能够自动理解、生成和转换文档内容,使得系统在处理大量文本信息时,能够实现快速分类、信息提取及内容生成,从而大幅降低人工干预的需求,帮助研发人员加速大模型系统的构建和训练过程,推动生成式AI技术的发展。
合合信息图像算法研发总监郭丰俊博士在 PRCV 2024 上,受邀发表了题为《生成式AI时代的内容安全与系统构建加速》的演讲,分享了图像内容安全和智能文档处理推动系统构建加速方面的最新研究成果和应用实践,助力解决生成式 AI 时代的双重挑战。
生成式人工智能 (Generative Artificial Intelligence, GAI) 是一种人工智能方法,旨在通过学习训练数据的分布模型来生成新的、原创的数据。人工智能生成内容 (Artificial Intelligence Generated Content, AIGC) 是生成式人工智能的一个具体应用和实现方式,是指利用人工智能技术生成各种形式的内容,如文字、图像、音频和视频等。
生成模型 (Generative Model) 是机器学习的一个分支,通过训练模型以生成与给定数据集类似的新数据,换句话说模型通过学习训练数据的分布特征,生成与之类似但又不完全相同的新数据。
假设有一个包含猫图片的数据集,如果在该数据集上训练一个生成模型,以捕捉图像中像素之间的复杂关系。然后,我们可以利用该模型进行采样,生成原始数据集中不存在的逼真(猫)图像,如下图所示。
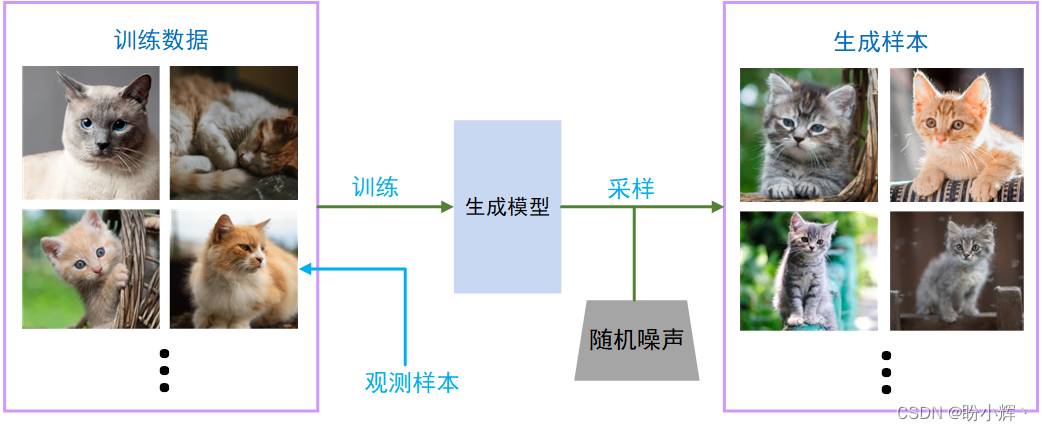
为了构建生成模型,我们需要一个包含许多我们要生成的实例的数据集,这被称为训练数据 (training data),其中每一个数据点称为一个观测值 (observation)。
每个观测值由许多特征 (features) 组成,对于图像生成问题,特征通常是各个像素的像素值;对于文本生成问题,特征通常是单词或字母组合。我们的目标是构建一个模型,可以生成看起来像是使用与原始数据相同规则创建的新特征集。对于图像生成来说,这是一个非常困难的任务,不仅由于生成的图像需要具有真实世界的特征和细节,包括纹理、颜色、形状等,同时图像生成模型通常需要大量的训练数据来学习图像的特征和分布。
生成模型还必须是概率性的 (probabilistic),而不是确定性的 (deterministic),因为我们希望能够采样出具有不同变化的输出,而不是每次得到相同的输出,对于图像数据而言,生成的图像应该具有不同的风格、角度和变化,而不是仅仅复制训练数据中的图像。如果我们的模型仅仅是一个固定的计算,例如在训练数据集中每个像素的平均值,那么它就不是生成模型,生成模型必须包含一个影响模型生成的随机因素。
换句话说,我们假设存在某种未知的概率分布,其可以解释图像在训练数据集中存在(或不存在)的合理性。生成模型的目标是构建一个尽可能精确地模仿这个分布的模型,然后从中进行采样,生成看起来像是原始训练集中可能包含的新的、独特的样本数据。
为了了解生成模型及其重要性,首先需要介绍判别模型。假设我们有一个绘画的数据集,其中包含莫奈与一些其他艺术家的画作。通过使用足够的数据,可以训练一个判别模型,以预测给定的画作是否由莫奈绘制。判别模型能够学到画作中的颜色、形状和纹理特征,以便判断画作是否由莫奈所绘制,对于具有莫奈画作特征的绘画,模型会相应地增加其预测权重。下图展示了判别模型的构建过程:

在构建判别模型时,训练数据中的每个观测值都有一个标签 (label)。对于二分类问题,比如上述画作鉴别器,将莫奈的画作标记为 1,非莫奈的画作标记为 0。然后,判别模型学习如何区分这两组画作,并预测新数据样本属于标签 1 的概率,即样本是由莫奈绘制的概率。
而生成模型不需要数据集带有标签,因为生成模型关注的是生成新图像,而非试图预测给定图像的标签。接下来,使用公式正式定义生成模型和判别模型。
Generative Adversarial Networks, GAN) 或扩散模型等算法来生成新的观测值总结而言,判别模型和生成模型是两种不同的机器学习方法。判别模型通过观测值预测标签,而生成模型通过学习数据分布来生成新的观测值。
生成模型估计
p
(
x
)
p(x)
p(x),即生成观测值
x
x
x 的概率。也就是说,生成模型旨在对观测值
x
x
x 进行建模,从所学分布中进行采样可以生成新的观测值。
数年来,判别模型一直是推动机器学习发展的主要动力。这是因为相对于判别问题,相应的生成问题通常更难解决。例如,训练一个模型预测一幅画是否是莫奈所作比起训练一个模型来生成莫奈风格的画作要容易得多;同样,训练一个模型来预测一篇小说是否是莎士比亚所写比起构建一个模型来生成一篇莎士比亚风格的小说要容易得多。
近来,随着机器学习技术的发展,解决生成问题变得不再遥不可及。通过将机器学习应用于构建生成模型的新颖应用得到了快速发展。下图展示了图像生成模型在面部图像生成方面的研究进展。

除了更容易解决的优势之外,判别模型在实际问题中的应用也比生成模型更广泛。例如,能够预测给定视网膜图像是否隐含青光眼迹象的模型对医疗领域具有重要作用,但能够生成眼部图片的模型可能并无作用。
但随着越来越多的公司开始提供面向特定业务问题的生成服务,生成模型的应用范围正在快速扩展。例如,只需提供特定的主题材料,就可以通过 API 访问生成原创博客文章的服务,还可以生成在不同场景下的产品图像,或者编写与品牌和目标信息相匹配的社交媒体内容和广告文案。同时,生成式 AI 在游戏设计和电影制作等行业也逐渐得到应用。
在 PRCV 2024 上,合合信息主要分享了 AI 图像安全技术方案的重点技术,包括图像篡改检测和人脸伪造检测技术,以应对日益频发的恶意 P 图、生成式造假和等现象。
随着生成式人工智能 (Generative Artificial Intelligence, GAI)技术的迅速发展,伪造数据的数量和可定制性也日益增加,人们对技术革新带来的美好生活倍感期待的同时,也增加了对于人工智能安全问题的担忧,例如,有诈骗分子通过生成篡改内容欺骗受害者,如何有效破解信息安全难题、保障内容安全成为当前的重要议题。
图像作为信息的主要载体之一,图像内容安全在计算机视觉领域的重要性日益突出。例如,在金融行业,银行移动开户、信用卡申办和保险理赔等场景中,身份信息核查是银行、保险等业务场景中的首要项,利用 GAI 技术,攻击者可以快速生成虚假的姓名、地址和电话号码等身份信息,这些篡改身份信息不仅与真实信息相似,还可以根据特定需求进行调整,使得识别变得更加困难,为个人和企业带来巨大的资金损失与潜在风险;同样,在汽车交易、运输等业务中,涉及大量驾驶证、行驶证真实性核查,利用 GAI 技术生成的证件在外观和细节上几乎无法与真实证件区分,这使得不法分子能够轻松利用这些篡改证件进行非法活动,行驶证涉及到车辆买卖合法性,行驶证造假与核查难题给相关企业造成了相当高的经济损失风险;再比如,在财务审批过程中,对网约车订单、付款截图、航空行程单、酒店流水等各类报销佐证单据的真实性检验是一项重要任务,企业在面对这些篡改票据时,往往难以识别,进一步增加了虚假发票和收据生成带来的财务欺诈风险。

由于篡改手段的多样性以及隐蔽性,当前的篡改检测任务面临着诸多复杂的难题。首先,篡改手段多种多样,从简单的像素替换到复杂的图像合成,攻击者可以采用不同的策略来掩盖其篡改行为。这使得检测系统很难建立起有效的识别标准。其次,篡改的隐蔽性使得篡改痕迹往往微弱,甚至在仔细审查的情况下也难以察觉。更为棘手的是,篡改图像与原始图像在内容和形式上可能高度相似,这种相似性进一步增加了识别的难度。
因此,这些因素对检测方法的精度和泛化能力提出了严峻的挑战。检测系统不仅需要在面对明显篡改时保持高精度,还必须具备足够的泛化能力,以适应多变的篡改方式。这要求研究人员不断改进和创新检测技术,力求在不断变化的环境中有效识别出篡改内容,以保护信息的真实性和可靠性。
图像篡改检测是指,给定一张图片,输入到篡改检测模型中,能够判别这张图像是否被篡改,并且定位出篡改图像的篡改区域。
考虑到伪造和篡改的技术也在快速更新,合合信息提出了基于小样本在线增量学习的篡改检测模型,以快速响应客户需求,融合空域与频域关系、知识蒸馏和教师-学生网络等方法提升 CNN Tamper Detector 性能,检测 RGB 域和噪声域存在痕迹的篡改,能够在像素级识别证件、票据等各类重要的商业材料中的 PS 痕迹。
与证照篡改检测相比,截图的背景没有纹路和底色,整个截图没有光照差异,难以通过拍照时产生的成像差异进行篡改痕迹判断,现有的视觉模型通常难以充分发掘原始图像和篡改图像的细粒度差异特征。尽管视觉模型在处理普通图像上表现出色,但当面临具有细粒度差异的原始图像和篡改图像时,它们往往难以有效地进行区分。这是因为篡改操作可能只会对截图进行轻微的修改,这些细节变化对于传统的视觉模型而言很难捕捉到。截图篡改主要分为四种类型:
针对这些问题,在传统卷积神经网络后引入两种不同解码器,包括基于降维的解码器 LightHam 和基于注意力的解码器 EANet,不同形式的解码器的引入令模型可以较好的解决各种场景下的篡改形式,从而捕捉到细粒度的视觉差异,增强模型泛化能力。截图篡改检测可检测包括转账记录、交易记录、聊天记录等多种截图。
应用合合信息的通用篡改检测技术,不仅能够保障信息的真实性,通用篡改检测可防止信息被篡改或伪造,确保信息的真实性和完整性;同时也可以防止欺诈行为,保障用户的合法权益。
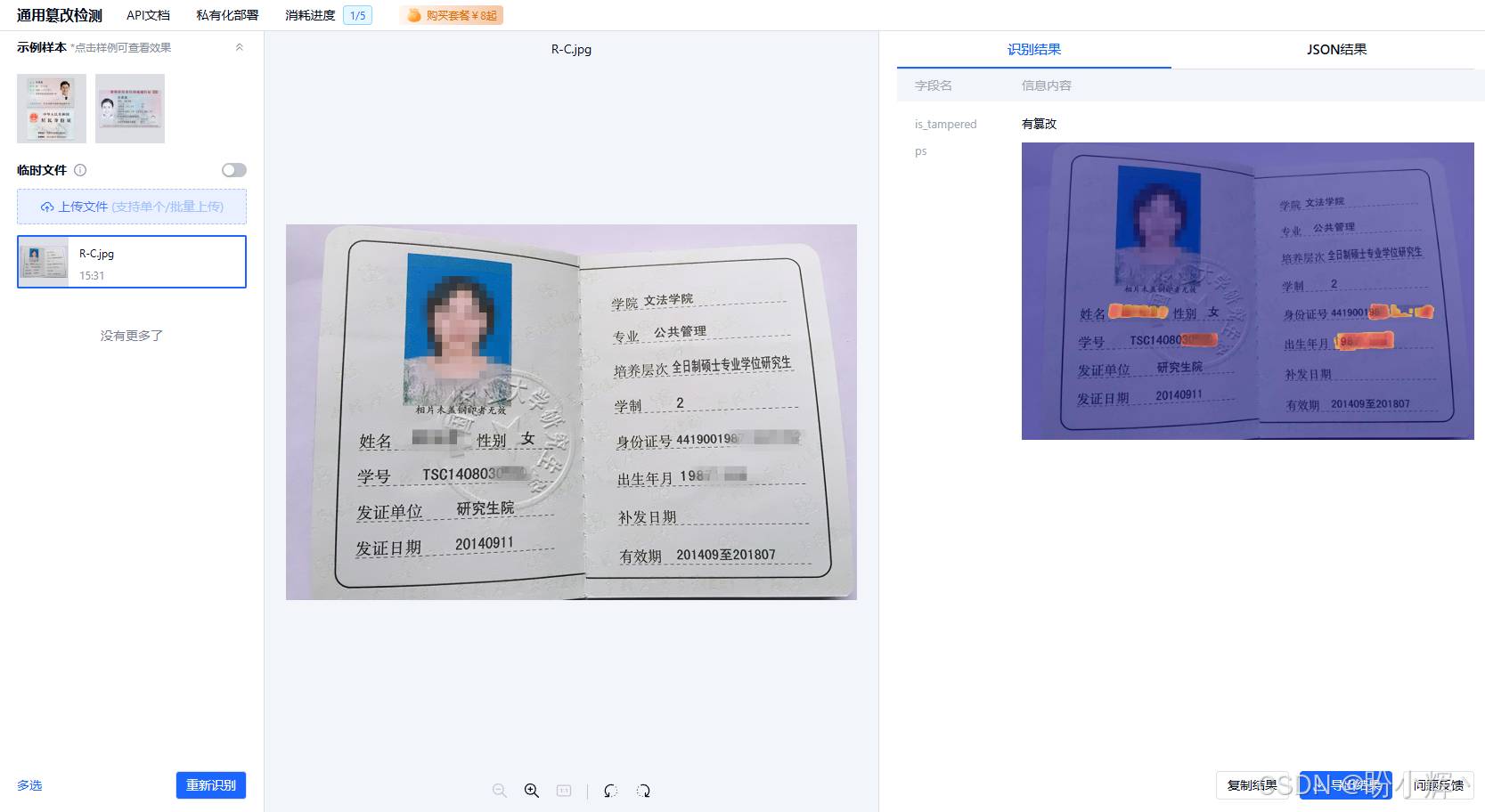
同时,合合信息积极参与学术界交流,在 2023 年文档分析与识别国际会议 (International Conference on Document Analysis and Recognition, ICDAR) 的挑战赛中,获得了文档篡改检测技术竞赛的冠军,同时与中国信通院、中国图象图形学学会等机构联合发布了《文本图像篡改检测系统技术要求》团体标准,能够推动相关技术更好的落地应用。

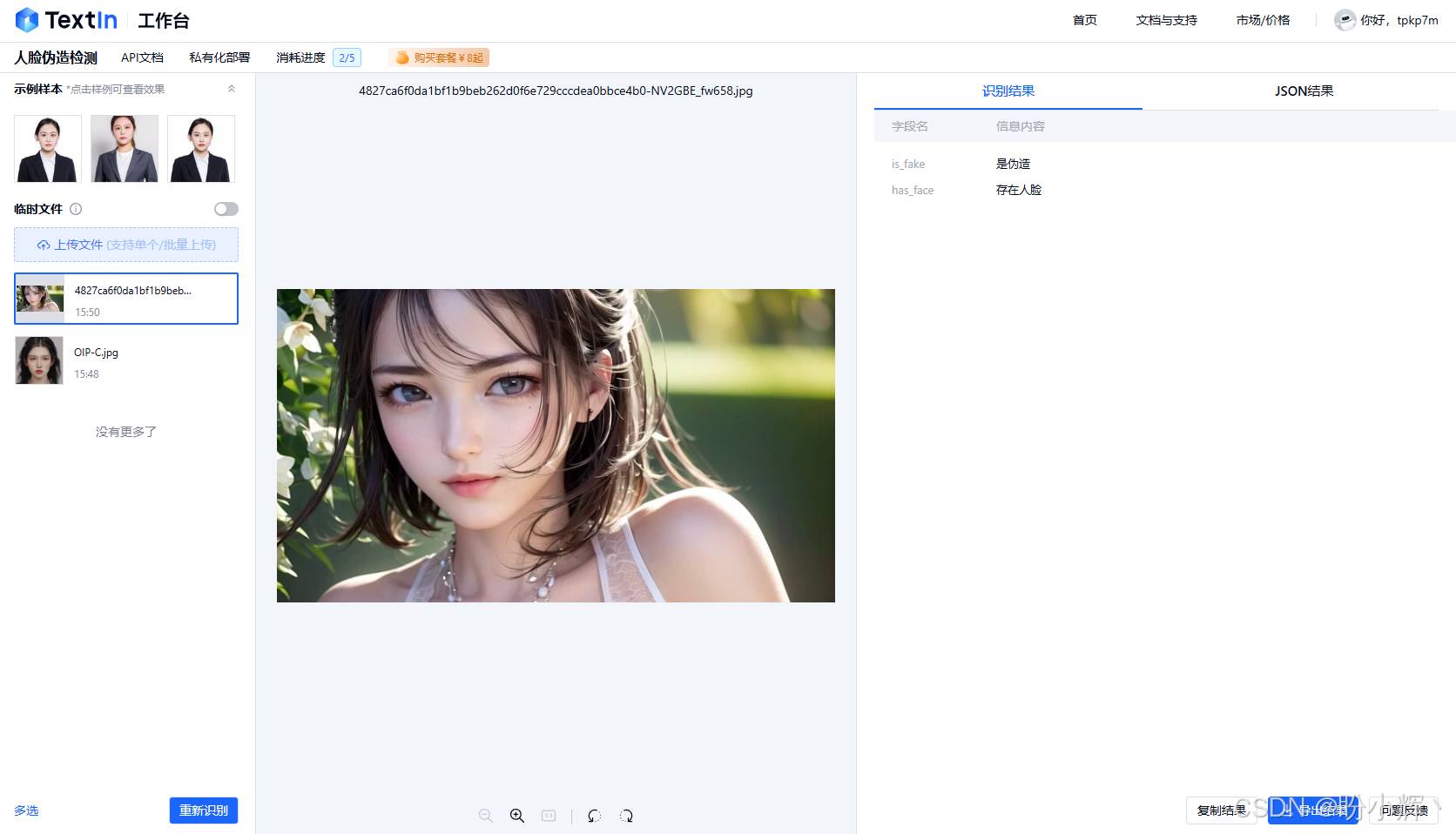
人脸伪造图像检测是一个快速发展的领域,旨在识别和验证人脸图像的真实性,以防止欺诈和虚假信息传播。但随着人脸伪造技术的不断演进,检测模型需适应各种生成方法,如生成对抗网络、Deepfake 和扩散模型等,确保能够识别不同类型的人脸伪造图像。
合合信息构建的人脸伪造图像检测系统利用前沿的深度学习技术,基于大量 Deepfake 实际样图训练,具备优秀的泛化识别表现,能够快速而准确地检测单人图像中的人脸伪造行为。通过深度学习算法的高级特征提取和分析,系统能够识别贴图、面部重演、Deepfake 人脸替换等各种伪造行为,同时具备高效的实时处理能力,能够在短时间内对上传的人脸图像进行检测和分析,及时给出检测结果,满足快速反应和处理的需求。
目前,合合信息提出的伪造人脸检测模型已与一些央企及金融机构展开落地合作,相关产品也可以在线体验,例如,使用伪造人脸检测识别使用 Stable Diffusion 生成人脸图像,模型能够准确给出图像“是伪造”的结论。
在生成式 AI 时代,大模型的构建面临诸多挑战和问题。其中,数据来源和质量的限制成为大模型进一步提高性能的主要障碍。高质量、丰富多样的数据集对于模型的训练至关重要,但在某些领域,合适的数据可能非常稀缺,从而影响模型的性能和公正性。此外,模型的复杂度和训练难度显著增加,往往导致开发和优化的过程变得及其繁琐。以上这些因素共同制约生成式 AI 的进一步发展和应用。
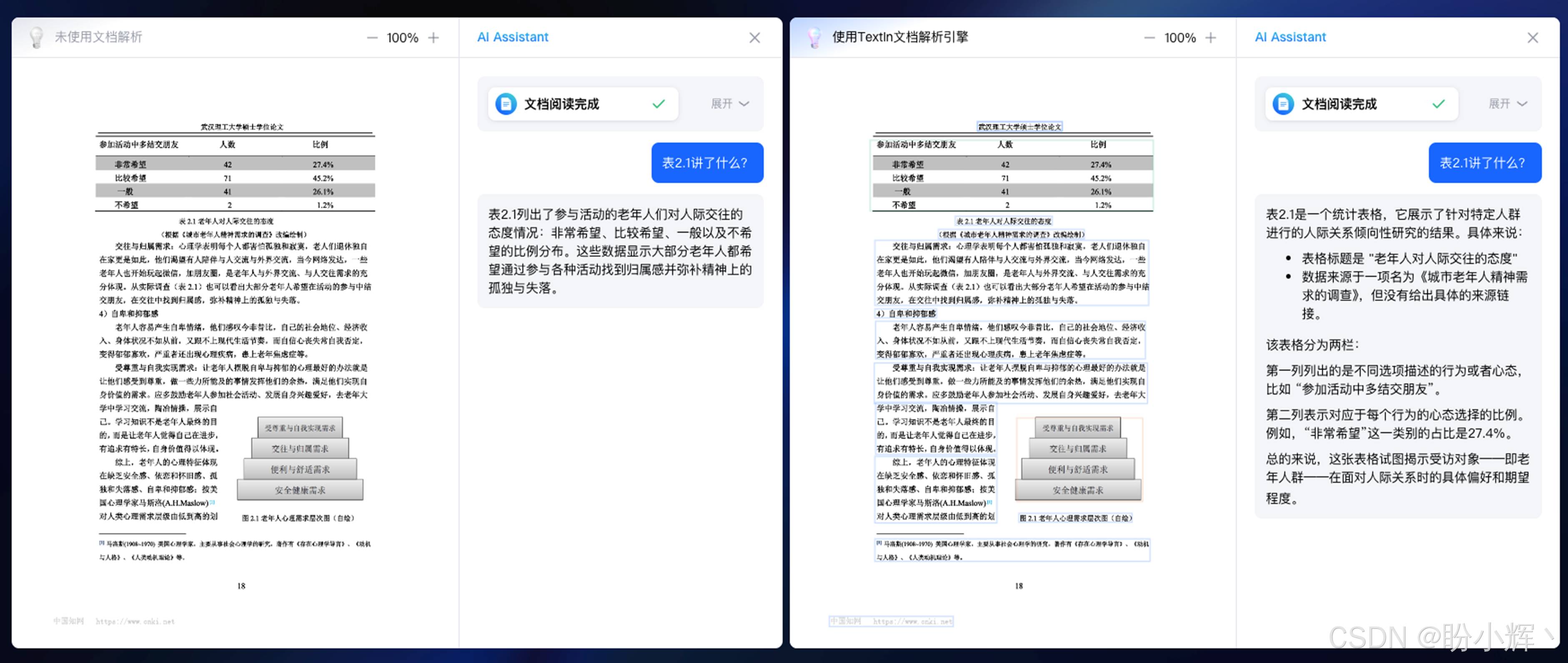
合合信息 TextIn 是一个文档处理服务平台,其中包含了大量具有不同应用场景的产品,同时针对上述大模型构建过程中的问题,新增了通用文档解析和文本向量模型,用于加速大模型的构建与训练。
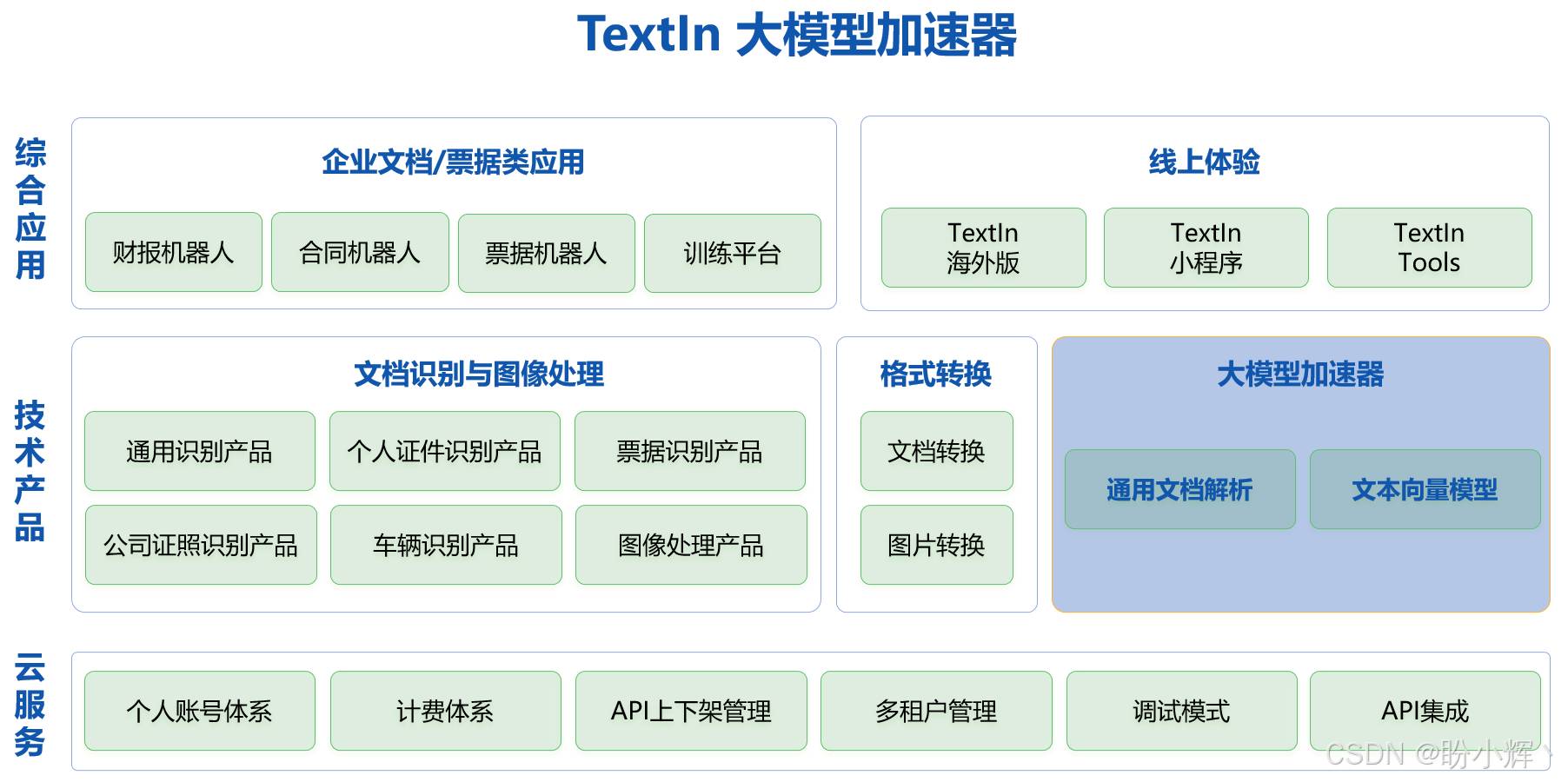
利用强大的文字识别和文档理解能力,通用文档解析能够将任意格式、版式的文档(图片、PDF、Doc/Docx 等)高效、精准解析为大模型能够理解的 Markdown 格式,并按常见的阅读顺序进行还原,赋能大语言模型的数据清洗和文档问答任务,能够帮助研发人员加速大模型系统的构建和训练过程,将文档中的内容更好的结构化为段落、图像、表格和章节等便于后续操作的元素。支持标准的金融报告、论文、企业招投标文件、合同、文书、工程图纸等文档内容,兼容扫描文档和电子 PDF 文件。

合合信息研发的通用文档解析通过应用计算机视觉、自然语言处理等人工智能技术,对文档图像进行自动化处理、分析和识别的过程,可以帮助用户快速高效地对文档图像信息展开深入的分析和理解,实现对文档中的重要信息进行提取。同时,在处理大量文档的情况下,可以显著地减少人力成本和时间成本,提高文档处理的准确度和效果,防止出现错误或遗漏等问题。
具体来说,通用文档解析框架主要包括以下方面:
Optical Character Recognition, OCR) 和表格识别等
将解析后的数据应用于下游问答任务能够显著提高结果的准确性,例如,在检索增强生成 (Retrieval Augmented Generation, RAG) 模型架构中,通过在生成文本之前先检索相关的信息,增强了生成的质量和准确性。RAG 通常分为两个阶段:首先,模型检索相关文档,然后基于这些文档生成答案或文本,使得生成的内容不仅基于模型的训练知识,还结合了特定的信息,从而提高了响应的相关性和信息丰富度。在下图中,可以看到,通用文档解析得到的信息,能够显著提升问答系统和对话生成等任务中大模型的表现。
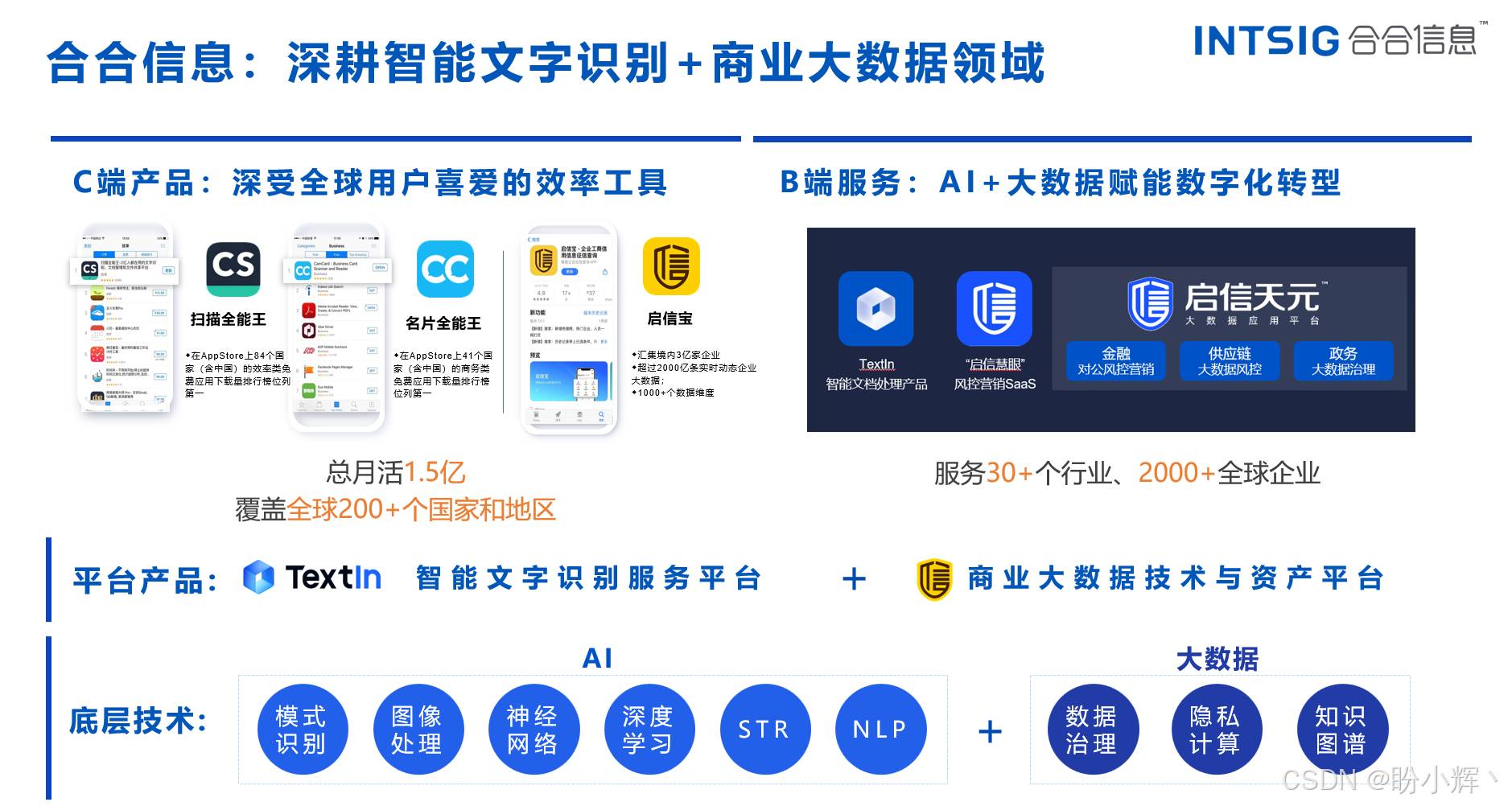
合合信息是一家深耕智能文字识别和商业大数据领域的公司,主要的平台产品包括智能文字识别服务平台和商业大数据技术与资产平台,其中,智能文字识别服务平台 TextIn 提供高精准度的智能文字识别引擎及场景化产品,支持多种部署方式,提升文档处理流程的效率,例如光学字符识别 (Optical Character Recognition, OCR)、图像切边增强、PS 篡改检测以及图像矫正等。
在生成式 AI 时代,模型具备快速响应用户需求的能力,能够实现即时生成与交互。但不准确数据会影响模型的表现,导致生成内容不可靠,同时随着伴随内容生成的便利,也出现了虚假信息、版权问题等安全挑战。本文通过回顾郭博士在郭丰俊博士在第七届中国模式识别与计算机视觉大会中的报告,介绍了合合信息关于文档和证件等数据的伪造检测技术,以及能够用于加速大模型系统的构建和训练过程的文档处理服务平台。
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码