目录
前言
1机器学习概述
1.1机器学习简介
1.1.1机器学习背景
1.1.2机器学习简介
1.1.3机器学习简史
1.1.4机器学习主要流派
1.2机器学习、人工智能和数据挖掘
1.2.1什么是人工智能
1.2.2什么是数据挖掘
1.2.3机器学习、人工智能与数据挖掘的关系
1.3典型机器学习应用领域
1.3.1典型机器学习应用领域---艺术创作
1.3.2典型机器学习应用领域---金融领域
1.3.3典型机器学习应用领域---医疗领域
1.3.4典型机器学习应用领域---自然语言处理
1.3.5网络安全
1.3.6工业领域
1.3.7机器学习在娱乐行业的应用
1.4机器学习算法分类
1.4.1机器学习算法分类---监督学习
1.4.2机器学习算法分类---非监督学习
1.4.3机器学习算法分类---半监督学习
1.4.4机器学习算法选择
1.4.5机器学习算法分类---分类算法
1.4.6分类算法---决策树
1.4.7分类算法---支持向量机
1.4.8分类算法---最近邻算法
1.4.9分类算法---贝叶斯网络
1.4.10分类算法---神经网络
1.4.11机器学习算法分类---聚类算法
1.4.12聚类算法---BIRCH算法
1.4.13聚类算法---CURE算法
1.4.14聚类算法---k-均值算法
1.4.15聚类算法---DBSCAN算法
1.4.16聚类算法---OPTICS算法
1.4.17机器学习算法分类---关联分析
1.4.18关联分析---Apriori算法
1.4.19关联分析---FP-growth算法
1.4.20关联分析---Eclat算法
1.4.20机器学习算法分类---回归分析
1.4.21回归分析---线性回归
1.4.22回归分析---逻辑回归
1.4.23回归分析---多项式回归
1.4.24回归分析---岭回归
1.4.25回归分析---LASSO回归
1.4.26机器学习算法分类---深度学习
1.5机器学习的一般流程
1.5.1定义分析目标
1.5.2收集数据
1.5.3整理预处理
1.5.4数据建模
1.5.5模型训练
1.5.6模型评估
1.5.7模型应用
2机器学习的Python常用库
2.1Numpy简介及基本使用
2.1.1统计学
2.1.2大数据与统计学
2.1.3统计学在机器学习中的应用
2.1.4Numpy
2.1.5Numpy安装
2.1.6Numpy介绍
2.1.7Numpy基本使用
2.2Pandas简介及基本使用
2.2.1Pandas快速入门
2.2.2Pandas基本使用
2.3Matplotlib简介及基本使用
2.3.1Matplotlib
2.3.2Matplotlib安装
2.3.3Matplotlib介绍
2.4Scikit-Learn简介及基本使用
2.5波士顿房价预测实战
2.5.1综合案例
3回归算法与应用
3.1回归算法与应用
3.1.1回归分析
3.1.2常见数据集
3.1.3线性回归
3.1.4实验实现线性回归
3.1.5Python实现最小二乘法拟合直线
3.1.6原理与应用场景——岭回归和LASSO
3.1.7原理与应用场景——逻辑回归
4特征工程、降维与超参数调优
4.1特征工程
4.1.1特征工程概念
4.1.2特征工程的内容
4.1.3缺失值处理
4.1.4数据的特征值化
4.1.5数据特征选择
4.1.6数据转换
4.2降维与超参数调优
4.2.1数据降维
4.2.2超参数调优
5分类算法与应用
5.1分类问题简介
5.1.1分类算法概述
5.2k近邻算法
5.2.1KNN算法
5.2.2基于k近邻算法实现分类任务
5.2.3【案列】使用Python实现KNN
5.3概率模型和贝叶斯算法
5.3.1概率模型
5.3.2贝叶斯算法
5.3.3朴素贝叶斯算法
编辑
5.4向量空间模型和支持向量机
5.4.1向量空间模型
5.4.2支持向量机
5.5集成学习
5.5.1集成模型
5.5.2决策树
5.5.3AdaBoost
6关联规则
6.1关联规则
6.1.1关联规则的概念
6.1.2apriori算法
7聚类算法与应用
7.1聚类算法概述与聚类中的数据机构
7.2划分聚类
7.3层次聚类
7.3.1主要聚类方式
7.3.2引入层次聚类
7.3.3凝聚层次聚类
7.3.4凝聚层次聚类伪代码
7.3.5层次聚类运行过程
7.3.6层次聚类问题
7.3.7簇间相似度
7.3.8单链接聚类
7.3.9簇间相似度
7.3.10全链接的运算过程
7.3.11全链接聚类
7.3.12簇间相似度
7.3.13组平均链接聚类
7.3.14簇间相似度
7.3.15质心距离聚类
7.3.16层次聚类特点
7.3.17代码实现层次聚类
7.3.18实验07-2-使用层次聚类算法聚类
7.4密度聚类
7.4.1主要聚类方式
7.4.2密度聚类
8神经网络
8.1神经网络介绍及神经网络相关概念
8.2神经网络识别MINIS手写数据集
8.2.1导入图片数据集
8.2.2分析MNIST图片特征,并定义训练变量
8.2.3构建模型
8.2.4训练模型并输出中间状态
8.2.5测试模型
8.2.6保存模型
8.2.7读取模型
9文本分析
10图像数据分析
10.1图像数据概论
10.2图像识别案例-人脸识别
11深度学习入门
11.1深度学习概述与卷积神经网络
11.1.1深度学习概述
11.1.2卷积神经网络简介
11.1.3卷积神经网络的整体结构
11.1.4LeNet
11.1.5AlexNet网络
11.1.6VGG网络
11.1.7GoogLeNet
11.1.8深度残差网络
11.2循环神经网络
11.2.1RNN基本原理
11.2.2长短期记忆网络
11.3深度学习流行框架
11.4基于卷积神经网络识别手写数字实战
11.4.1实验目的
11.4.2实验背景
11.4.3实验原理
11.4.4实验环境
11.4.5实验步骤:数据准备
11.4.6实验步骤:网络设计
11.4.7实验步骤:模型训练
11.4.8实验步骤:模型测试
11.4.9实验总结
机器学习是人工智能的重要技术基础,涉及的内容十分广泛。本文章涵盖了机器学习的基础知识,主要包括机器学习的概述、 回归、分类、聚类、神经网络、文本分析、图像分析、深度学习等经典的机器学习基础知识,还包括深度学习入门等拔高内容。
介绍机器学习的基础概念和知识,包括机器学习简史、主要流派、与人工智能、数据挖掘的关系、应用领域、算法、一般流程等。
伴随着计算机计算能力的不断提升以及大数据时代的迅发展人工智能也取得了前所未有的进步。
很多企业均开始使用机器学习的相关技术于大部分行业中,以此获得更为强大的洞察力,也为企业的日常生活和企业运营带来了很大的帮助,从而提高了整个产品的服务质量。
机器学习的典型应用领域有:搜索引擎、自动驾驶、量化投资、计算机视觉、信用卡欺诈检测、游戏、数据挖掘、电子商务、图像识别、自然语言处理、医学诊断、证券金融市场分析以及机器人等相关领域,故在一定程度上,机器学习相关技术的进步也提升了人工智能领域发展的速度。
机器学习(MachineLearning),作为计算机科学的子领域,是人工智能领域的重要分支和实现方式。
机器学习的思想:计算机程序随着经验的积累,能够实现性能的提高。对于某一类任务T及其性能度量P,若一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么就称这个计算机程序在从经验E学习。
主要的基础理论:数理统计,数学分析,概率论,线性代数,优化理论,数值逼近、计算复杂性理论。
机器学习的核心元素:算法、数据以及模型。
作为一门不断发展的学科,机器学习尽管在最近几年才发展成为一门独立的学科。
起源于20世纪50年代以来人工智能的逻辑推理、启发式搜索、专家系统、符号演算、自动机模型、模糊数学以及神经网络的反向传播BP算法等。如今作为机器学习重要的基础理论。
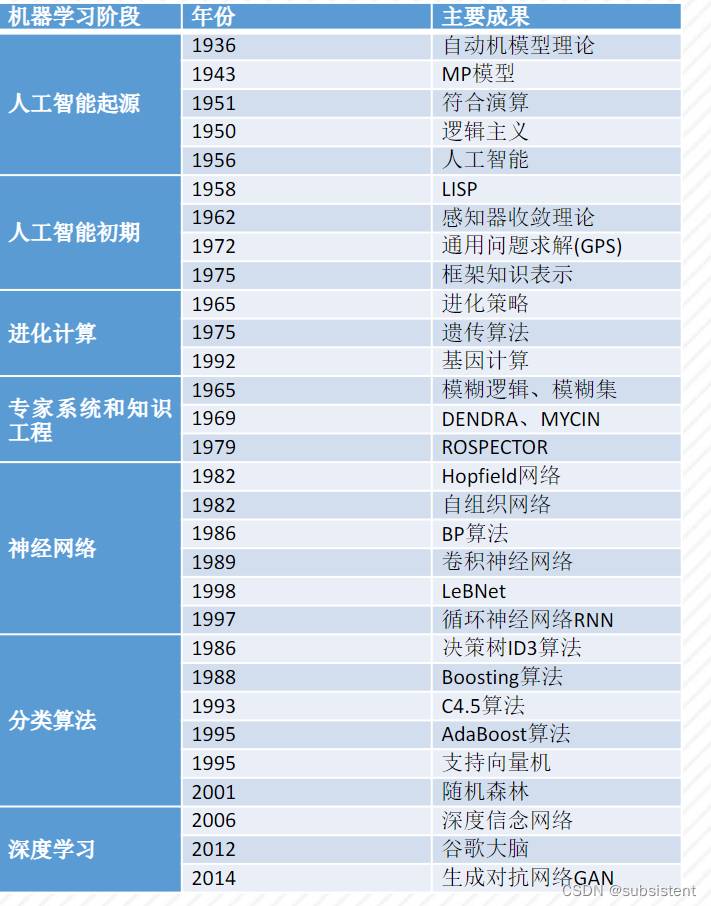
在1950年代,已经有了机器学习的相关研究。代表工作主要是F.Rosenblatt基于神经感觉科学提出的计算机神经网络,即感知器。随后十年,用于浅层学习的神经网络风靡一时,尤其是MarvinMinsky提出了著名的XOR问题和感知器线性度不可分割的问题。
局限:由于计算机的计算能力有限,因此很难训练多层网络。通常使用仅具有一个隐藏层的浅层模型。尽管已经陆续提出了各种浅层机器学习模型,但理论分析和应用方面都已产生。但是,理论分析和训练方法的难度要求大量的经验和技能。而随着最近邻算法和其他算法的相继提出,在模型理解,准确性和模型训练方面已经超越了浅层模型。机器学习的发展几乎停滞不前。
在2006年,希尔顿(Hinton)发表了一篇关于深度信念网络的论文,Bengio等人发表了关于“深度网络的贪婪分层明智训练”的论文,而LeCun团队发表了基于能量模型的“稀疏表示的有效学习”。
这些事件标志着人工智能正式进入深度网络的实践阶段。同时,云计算和GPU并行计算为深度学习的发展提供了基本保证,尤其是近年来,机器学习它在各个领域都实现了快速发展。新的机器学习算法面临的主要问题更加复杂。机器学习的应用领域已从广度发展到深度,这对模型的训练和应用提出了更高的要求。
随着人工智能的发展,冯·诺依曼有限状态机的理论基础变得越来越难以满足当前神经网络中层数的要求。这些都给机器学习带来了挑战。
在人工智能的发展中,随着人们对智能的理解和对实际问题的解决方案的发展,机器学习大致出现了符号主义、贝叶斯、联结主义、进化主义、行为类推主义五大流派。
符号主义起源于逻辑和哲学,其实现方法是利用符号来表达知识并使用规则进行逻辑推理。专家系统和知识工程是该理论的代表。符号主义学派认为,知识是信息符号的表示,是人工智能的基础。这些符号被输入到计算机中进行仿真和推理,以实现人工智能。
贝叶斯定理是概率论中的一个定理,其中P(A|B)是事件B发生时事件A发生的概率(条件概率)。贝叶斯学习已被应用于许多领域。例如,自然语言中的情感分类,自动驾驶和垃圾邮件过滤。
联结主义起源于神经科学,主要算法是神经网络,它由一定结构中的大量神经元组成。神经元是一种看起来像树的细胞,它由细胞主体和细胞突起组成,长轴突被鞘覆盖以形成神经纤维,在其末端的小分支称为神经末梢。每个神经元可以具有一个或多个树突,这些树突可以接受刺激并将兴奋转移到细胞体内。每个神经元只有一个轴突,它可以将兴奋从细胞体传递到另一个神经元或其他组织,神经元相互连接,从而形成一个大型的神经网络,人类所学到的几乎所有知识都存在其中,如下图所示:
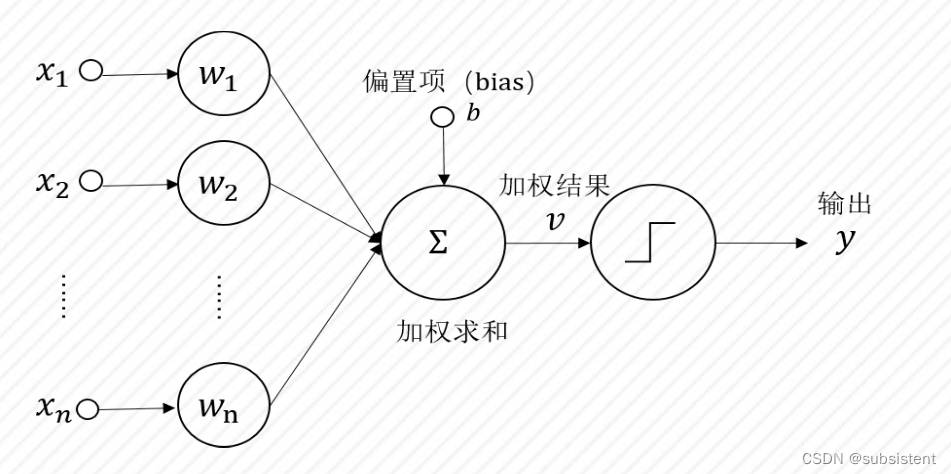
在神经网络中,将n个连接的神经元的输出用作当前神经元的输入,进行加权计算,并添加一个偏置值(Bias)以通过激活函数实现变换,激活功能的功能是在一定范围内输出控制。以Sigmoid函数为例,输入是从负无穷大到正无穷大,并在激活后映射到(0,1)间隔。
人工神经网络是分层(Layer)组织的,每层包含多个神经元,这些层通过某种结构连接,神经网络训练的目的是找到网络中的每个突触连接的权重和偏差值。作为一种监督学习算法,神经网络的训练过程是通过不断反馈当前网络计算结果与训练数据之间的误差来校正网络权重,使得误差足够小,这就是反向传播算法。
1850年,达尔文提出进化论。进化过程是适者生存的过程,个体生物在其中适应环境。智能需要适应不断变化的环境,并通过对进化过程进行建模来生成智能行为。
进化算法(EA)是基于“自然选择,适者生存”和迭代优化的原理,在计算机上模拟进化过程,直到找到最佳结果。进化算法包括基本操作,例如基因编码,群体初始化和交叉变异算子。它是一种相对成熟的全局优化方法,具有广泛的适用性。它具有自组织,自适应和自学习的特征,可以有效地处理传统优化。用算法难以解决的复杂问题(例如NP硬优化问题)。
遗传算法的优化应根据具体情况选择算法,也可以与其他算法结合进行补充。对于动态数据,可能难以使用遗传算法来找到最佳解,并且种群可能会过早收敛。
根据约束条件优化功能,行为类比主义者倾向于通过类比推理获得知识和理论,并在未知情况和已知情况之间建立相应的关系。在实际应用中,是计算它们之间的相似度,然后定义关联关系。
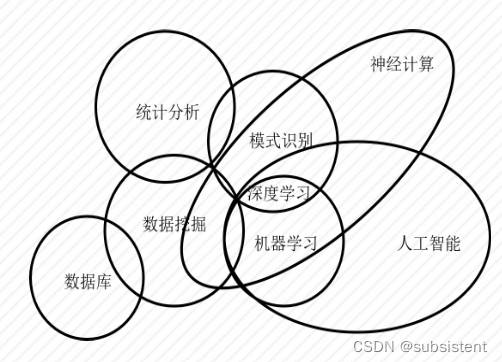
机器学习与其他领域之间的关系如下图所示:
数据挖掘:通过处理各种数据来促进人们的决策
机器学习:使机器模仿人类的学习来获取知识
人工智能:使用机器学习和推理来最终形成特定的智能行为
人工智能是为了使机器的行为看起来像人类所表现出的智能行为。麻省理工学院的约翰·麦卡锡(JohnMcCarthy)于1956年在达特茅斯会议上提出。
人工智能的先驱者希望机器具有与人类相似的功能:感知,语言,思维,学习,动作等。
近年来,人们发现机器在感知(图像识别)和学习方面具有某些功能,所以人工智能在世界范围内开始普及。
人工智能的现阶段仍处于“弱人工智能”(NarrowAI)阶段
人类不需要大量的数据来进行反复的迭代学习以获取知识和进行推理。他们只需要看一下自行车的照片就可以粗略地区分各种自行车。即目前对人脑中信息的存储和处理尚未得到清晰的研究,与当前主流的深度学习理论有很大的基本差异。
因此,人工智能距离“强人工智能”(GeneralAI)阶段还有很长的路要走。
典型的人工智能系统包括以下方面:
(1)博弈游戏(如深蓝、AlphaGo、AlphaZero等)。
(2)机器人相关控制理论(运动规划、控制机器人行走等)。
(3)机器翻译。
(4)语音识别。
(5)计算机视觉系统。
(6)自然语言处理(自动程序)。
数据挖掘使用诸如机器学习,统计和数据库之类的方法来发现相对大量的数据集中的模式和知识,涉及数据预处理,模型和推理,可视化等。
数据挖掘包括以下类型的常见任务。

异常检测(anomalydetection):识别不符合预期模式的样本和事件。异常也称为离群值,偏差和异常。异常检测通常用于入侵检测,银行欺诈,疾病检测,故障检测等。
关联规则学习(Associationrulelearning):发现数据库中变量之间的关系(强规则)。例如,在购物篮分析中,发现规则{面包,牛奶}→{酸奶}表示如果客户同时购买面包和牛奶,他们很有可能也会购买酸奶,这些规则可以用于市场营销。
聚类:一种探索性分析,在数据结构未知的情况下,根据相似度将样本划分为不同的群集或子集,不同聚类的样本有很大的差异,以便发现数据的类别和结构。
分类:根据已知样本的某些特征确定新样本所属的类别。通过特征选择和学习,建立判别函数以对样本进行分类。
回归:一种统计分析方法,用于了解两个或多个变量之间的相关性,回归的目标是找到误差最小的拟合函数作为模型,并使用特定的自变量来预测因变量的值。
随着数据存储(非关系NoSQL数据库),分布式数据计算(Hadoop/Spark等),数据可视化和其他技术的发展,数据挖掘具有越来越多的了解事务的能力,但相对也增加了算法的要求。因此,一方面,数据挖掘必须获取尽可能多,更有价值和更全面的数据,另一方面要从这些数据中提取价值。
数据挖掘在商业智能中有许多应用,特别是在决策辅助、流程优化和精确营销中。例如:
广告公司可以使用用户的浏览历史记录、访问记录、点击记录和购买信息来准确地宣传广告。采用舆论分析,尤其是情感分析,可以提取舆论来驱动市场决策。例如,在电影宣传期间监视社会评论,寻找与目标观众产生共鸣的元素,然后调整媒体宣传策略以迎合观众的口味并吸引更多人。
数据挖掘是从大量业务数据中挖掘隐藏的、有用的以及正确的知识,以促进决策的执行。
数据挖掘的许多算法都来自机器学习和统计。机器学习中的某些算法利用统计理论,并在实际应用中对其进行优化以实现数据挖掘的目标。
近年来,机器学习的演化计算深度学习等方法也逐渐跳出实验室,从实际数据中学习模式并解决实际问题。数据挖掘与机器学习的交集越来越大,机器学习已成为数据挖掘的重要支撑技术。
机器学习是人工智能的一个分支,作为人工智能的核心技术和实现方法,机器学习方法被用来解决人工智能面临的问题。机器学习是使用一些算法,这些算法允许计算机自动“学习”,分析数据并从中获取规则,然后使用这些规则来预测新样本。
机器学习是人工智能的重要支持技术,而深度学习就是其中一个重要分支。深度学习的典型应用是选择数据来训练模型,然后使用该模型进行预测。例如,博弈游戏系统(DeepBlue)专注于探索和优化未来的解决方案空间(SolutionSpace),而深度学习则为开发游戏算法(例如AlphaGo)付出了艰辛的努力,并已享誉全球成就。
机器学习可以显著提高企业的智能水平并增强其竞争力,对各个行业的影响越来越大。
机器学习应用程序的典型领域包括:
网络安全,搜索引擎,产品推荐,自动驾驶,图像识别,语音识别,量化投资,自然语言处理等。
随着海量数据的积累和硬件计算能力的提高,机器学习的应用领域仍在迅速扩展中。
在图像处理中有许多应用,如卷积神经网络(CNN)等在图像处理中具有天然的优势。
机器学习被广泛应用于图像处理领域,除了图像识别,照片分类,图像隐藏等以外,还涉及图像生成,美化,恢复和图像场景描述等。
2015年,脸书(Facebook)公司开发了可描述图片内容的应用程序,通过描述图片中的背景,字符,对象和场景来帮助视障人士理解图片的内容。主要的应用技术是图像识别实现对图片中对象的识别,但是内容的描述以故事的形式返回,还需要自然语言的生成技术,这是人工智能领域当前的难点之一。
艺术画合成
借助深层的神经网络,人们可以通过合成画出充满艺术气息的图画。其原理是使用卷积神经网络提取模板图片中的绘画特征,然后应用马尔可夫随机场(MRF)来处理输入的涂鸦图片,最后合成一张新图片。
下图显示了NeuralDoodle项目的应用效果。(左图是油画模板,中图是用户的涂鸦作品,右图是合成后的新作品)

将对抗性神经网络(GAN)和卷积神经网络相结合,并将MRF理论应用于现有图片修复的缺失部分。
使用经过培训的VGGNet作为纹理生成网络可以删除现有图片中的干扰对象,这种技术具有广泛的应用范围。
谷歌(Google)公司的PlaNet神经网络模型可以识别照片中的地理位置(不使用照片的Extif位置数据)。
该模型的训练使用了约1.26亿张网络图片,将图片的Extif位置信息用作标记,以对除北,南极和海洋以外的地球区域进行网格划分,从而使图片相对应到特定的网格
该部门使用约9100万张图片进行培训,使用约3400万张图片进行验证,以及使用Flickr中约2300万张图片进行测试,大约3.6%的图片可以准确地识别到街道上,28%的照片可以准确地识别出其所在的国家,48%的照片可以准确地识别出其所在的大陆板块。
识别的误差距离约为1131公里,在相同情况下,图片位置的人为定位误差距离为2320公里。
尽管训练样本的数量很大,但最终的神经网络模型的大小仅为377MB。
金融与人们的日常生活息息相关,例如食物,衣服,住房和交通。
与人类相比,机器学习在处理金融行业业务方面更为有效,它可以同时准确地分析成千上万的股票并在短时间内得出结论,它没有人为的缺点,在处理财务问题上更可靠和稳定,通过建立欺诈或异常检测模型,有效地检测出细微的模式差异并提高结果的准确性,来提高财务安全性。
在信用评分方面,评分模型用于评估信用过程中的各种风险并进行监督,根据客户的职业,薪水,行业,历史信用记录等信息确定客户的信用评分,这不仅可以降低风险,而且可以加快贷款流程,减少尽职调查的工作量并提高效率。
在欺诈检测中,基于收集的历史数据训练机器学习模型,以预测欺诈的可能性。与传统检测相比,此方法花费的时间更少,并且可以检测到更复杂的欺诈。在训练过程中,应注意样本类别的不平衡,以防止过度拟合。
在股市趋势预测方面,机器学习算法用于分析上市公司的资产负债表,现金流量表以及其他财务数据和公司运营数据,并提取与股价或指数有关的特征以进行预测。
1.使用与公司相关的第三方信息(例如政策法规,新闻或社交网络中的信息),通过自然语言处理技术来分析舆情观点或情感指向,为股价预测提供支持,从而使预测结果更准确。
2.应用监督学习方法建立两个数据集之间的关系,以便使用一个数据集来预测另一数据集的结果,例如使用回归分析通胀对股票市场的影响等、在股票市场中使用无监督学习方法对影响因素的分析揭示背后的主要规则;深度学习适用于处理非结构化大数据集并提取不容易明确表达的特征;强化学习的目标是找到通过算法探索最大化收益的策略。
3.应用诸如LSTM之类的深度学习方法可以基于股票价格波动的特征和可量化的市场数据进行股票价格的实时预测,可用于股票市场和高频交易等其他领域中。
在客户关系管理(CRM)中:
➢从银行和其他金融机构的现有海量数据中提取信息,并通过机器学习模型对客户进行细分,以支持业务部门的销售,宣传和营销活动。
➢诸如聊天机器人之类的集成人工智能技术的应用可以为客户提供全天候服务,并提供个人财务助手服务,例如个人财务指南和跟踪费用。
➢在长期保存用户历史记录后,我们在处理各种客户要求(例如客户通知,转账,存款,查询,常见问题和客户支持)时,可以为客户提供合适的财务管理解决方案。
机器学习可用于预测患者的诊断结果,制定最佳治疗方案,甚至评估风险水平,还能减少人为错误。
◆在2016年《美国医学会杂志》(JAMAMagazine)上发表的一项研究中,人工智能学习了许多历史病理学图片,并验证了其准确性达到96%。这一事实证明,在对糖尿病视网膜病变进行诊断方面,人工智能已经与医生水平相当。在进行了13万张皮肤癌的临床图片的深度学习之后,机器学习系统在皮肤癌的检测方面超过了皮肤科医生。
◆对于脑外科医师而言,术中病理分析通常是诊断脑肿瘤的最佳方法之一,并且该过程需要很长时间,并且很容易延误正在进行的脑外科手术。
◆科学家开发了一种机器学习系统,可以“染色”未经处理的大脑样本并提供非常准确的信息,效果与病理分析相同,诊断脑肿瘤的准确性和使用常规组织切片的准确性几乎是一样的,这对于接受脑瘤手术的患者来说非常重要,因为它大大减少了诊断时间。
◆在临床试验方面,每个临床试验都需要大量数据,例如患者病史和病历,健康日志,App数据和医学检查数据。
◆机器学习收集并挖掘这些数据以获得有价值的信息。例如,某生物制药公司根据单个患者的生物学特征进行建模,并根据患者的药物反应对测试人群进行分类,并在整个过程中监视患者的生物学体征和反应。
◆英国某公司使用机器学习技术来分析大量图像数据,通过分析建立模型,识别和预测早期癌症,还为患者提供个性化的治疗程序。研究人员从大量心脏病患者的电子病历数据库中检索出患者的医疗信息,比如疾病史,手术史以及个人生活习惯等医学信息,并在机器学习算法下对该信息进行分析和建模以预测患者的心脏病风险因素,在预测是否会患心脏病以及预测心脏病患者人数方面上均优于现在的预测模型。
自然语言处理属于文本挖掘的范畴,它结合了计算机科学,语言学和统计等基本学科。
自然语言处理涉及自然语言理解和自然语言生成。前者包括文本分类,自动摘要,机器翻译,自动问答,阅读理解等,在这些领域已经取得了很大的成就,然而自然语言生成方面成果却不是很多,具备一定智能且能够商用的产品少之又少。在自然语言处理中涉及的内容详细如下。

自然语言处理---分词
分词(WordSegmentation)主要基于字典中单词的识别,最基本的方法是最大匹配方法(MM),其效果取决于字典的覆盖范围。另外常见的基于统计的分词方法是利用语料库中的词频和共现概率等统计信息对文本进行分词。
◆解决切分歧义的方法包括句法统计和基于记忆的模型。前者结合了自动分词和基于马尔可夫链词性,并使用从手动标记语料库中提取的词性的二进制统计定律来解决歧义。而基于记忆的模型,将机器认为歧义的常见交集型歧义进行划分,例如“辛勤劳动”切分为“辛勤”“勤劳”“劳动”,并预先记录它们唯一正确的分割形式在表中,通过直接查找表可实现歧义的消除。
自然语言处理---词性标注
词性标记(Part-of-speechTagging)
◆任务:用于标记句子中的单词,例如动词,名词等。
◆本质:在序列上对每个单词的词性进行分类和判断
◆方法:早期使用了隐马尔可夫模型进行词性标注,后来又出现了最大熵模型,条件随机场模型,支持向量机模型等。随着深度学习技术的发展,出现了许多基于深度神经网络的词性标注方法。
自然语言处理---句法分析
◆在句法分析中,人工定义规则非常耗时,费力且维护成本高。
◆近年来,自动学习规则的方法已成为句法分析的主流方法。目前,数据驱动的方法是主流的分析方法。通过将诸如概率值(例如单词共现概率)之类的统计信息添加到文法规则中,扩展原始的上下文无关文法分析方法,最终实现概率上下文无关文法(ProbabilisticContextFreeGrammar,PCFG)分析方法,在实践中取得了较好的成果。
◆句法分析主要分为依存句法分析,短语结构句法分析,深层文法句法分析和基于深度学习的句法分析等。
自然语言处理---自然语言生成
自然语言生成(NaturalLanguageGeneration,NLG)的难点是需要大量知识库或逻辑形式的基础工作:
◆一方面,人类语言系统中有较多的背景知识,机器表述系统在整合大量的背景知识(信息量太大)有一定的困难
◆另一方面,语言很难在机器中进行合适的表达,因此自然语言生成的相关结果很少。
自然语言生成的方法
◆当前大多数自然语言生成方法都使用模板,模板源自人工(手动)定义,知识库或从语料库中提取,以这种方式生成的文本容易出现较为僵硬的问题。
◆神经网络也可以用于生成序列,例如Seq2Seq,GAN等深度学习模型,但是由于训练语料库的质量不同,容易出现诸如结果随机和结果不可控制等相关问题。
◆自然语言生成的步骤:
内容规划,结构规划,聚集句子,选择字词,指涉语生成和文本生成等。
◆自然语言生成的的应用:主要是通过摘录从一些数据库或一些资料集中生成文章的系统。如某些天气预报的生成,金融新闻或体育新闻的写作,百科全书的写作,诗歌的写作等,这些文章具有一定的范式,类似于八股文一样,具有固定的文章结构,并且语言样式也有较少的变化。这类文章着重于内容,读者对文章的样式和措词的要求较低。
在当前的人工智能领域,自然语言生成的问题尚未真正解决,可以说“得语言者得天下”,毕竟语言也代表着更高水平的人类智能。
自然语言处理---文本分类
◆文本分类(Textcategorization)是将文本内容划分为某一个特定类别的过程。目前深度学习模型在文本分类任务中取得了长足的进步。
◆文本分类算法:
基于规则的分类模型,基于机器学习的分类模型,基于神经网络的方法,卷积神经网络(CNN)和循环神经网络(RNN)。
◆文本分类技术的应用:
1.社交网站每天都会生成大量信息,如果对文本进行手动排序,将很费时费力,并且分类结果的稳定性很差;
2.应用自动化分类技术可以避免以上问题,从而实现文本内容的自动标记,为后续的用户兴趣建模和特征提取提供了基本支持。
3.作为基础组件,文本分类还用于信息检索,情感分析,机器翻译,自动摘要和垃圾邮件检测等领域。自然语言处理---文本分类
自然语言处理---信息检索
◆信息检索(InformationRetrieval)
◆定义:从信息资源集合中提取需求信息的行为,可以基于全文索引或内容索引。
◆技术:向量空间模型,权重计算,TF-IDF(词频-逆向文档频率)词项权重计算,文本相似度计算,文本聚类等,具体应用于搜索引擎,推荐系统,信息过滤等方面。
自然语言处理---信息抽取
◆信息抽取(InformationExtraction)
定义:从非结构化文本中提取指定的信息,并通过信息合并,冗余消除和冲突解决等方法将非结构化文本转换为结构化信息。
◆应用方向:
◆从相关新闻报道中提取事件信息:时间,位置,施事人、受事人、结果等;
◆从体育新闻中提取体育赛事信息:主队,客队,赛场,比分等;
◆从医学文献中提取疾病信息(病因,病原体,症状,药物等)。
◆此外,还广泛应用于舆论监测,网络搜索,智能问答等相关领域,信息提取技术也是中文信息处理和人工智能的基本核心技术。
自然语言处理---文本校对
◆文本校对(Text-proofing):主要应用于修复自然语言生成的内容或检测并修复OCR识别的结果。
主要技术:
◆词典是将常用词以词典的形式对词频进行记录。如果词典中不存在某些词,则需要对其进行修改并选择最相似的单词来替换,这种方法对词典的要求较高,并且在实际操作中,由于语言的变化多端且存在很多的组词方式,导致误判的情况很多,在实际应用中准确性不是很理想。
◆语言模型根据词汇之间搭配的可能性(概率)来判断词汇的正确性。一般情况下,以句子为单位检测整个句子,当前,常见的语言模型有SRILM和RNNLM等几种。
自然语言处理---问答系统
◆自动问答(QuestionAnswering)系统回答用户
步骤:
◆第1步:需要能够正确理解用户所提出自然语言问题,这涉及到分词,命名实体识别,句法分析,语义分析等自然语言理解相关技术。
◆第2步:针对提问类、事实类、交互类等不同形式的提问分别相对应地进行回答,例如用户所提的问题属于提问类的范畴,可以从知识库或问答数据库中进行检索和匹配用户问题,以获得答案。
它还涉及对话上下文处理,逻辑推理以及知识工程和语言生成等多种关键技术。问答系统代表了自然语言处理的智能处理水平。自然语言处理---问答系统
自然语言处理---机器翻译
机器翻译(MachineTranslation)是机器在不同自然语言之间进行的翻译,涉及语言学,机器学习,认知语言学等多个语言交叉学科。
方法:
◆基于规则的机器翻译方法:人工设计和编纂翻译规则,
◆基于统计的机器翻译方法:自动获取翻译规则,近年来流行的端到端的神经网络机器翻译方法可以直接自动地通过编码网络和解码网络学习语言之间的转换算法。自然语言处理---机器翻译
自然语言处理---自动摘要
自动摘要(AutomaticSummarization)主要是解决信息过载的问题,用户可以通过阅读摘要来了解文章的主要思想。
通常使用两种抽象方法:
◆抽取式:抽取式方法是评估句子或段落的权重,根据其重要性选择它们并撰写摘要。
◆生成式:1.使用自然语言理解技术分析文本内容外;2.使用自然语言生成技术(例如句子计划和模板)来生成新句子。
➢传统的自然语言生成技术在不同领域的泛化能力较差,随着深度学习的发展,生成式摘要的应用逐渐增多。
➢目前,主流仍然采用基于抽取式的方法,因为该方法易于实现,可以确保摘要中的每个句子具有良好的可读性,不需要大量的训练语料,并且可以跨领域应用。
网络安全包括反垃圾邮件,反网络钓鱼,Internet内容过滤,反欺诈,攻击防御和活动监视等,随着机器学习算法逐渐应用于企业安全中,各种新型的安全解决方案应运而生,这些模型在网络分析、网络的监控、异常情况的发现等方面扮演着非常重要的角色,可以保护企业免受威胁。
◆密码学-密码破解
通过分析通用符号密码的特性和当前通用密码的各种缺点,使用神经网络算法来破解密码。
近年来,谷歌大脑已将生成对抗网络(GAN)引入了密码的加密和解密中。随着迭代训练的数量不断地增加,加密模型和解密模型的性能已同时得到了改善,并且最终在不提供密码知识的情况下获得了性能很强的加密模型。
◆加强网络安全性
使用机器学习来检测网络安全性的优势和劣势,并提出了一些改进建议。
由于恶意请求通常都是经过了一定的伪装,因此,网络入侵的检测更加困难,并且攻击行为的例子也较少,样本的不平衡问题也需要处理,召回率(Recall)作为模型评估中的性能度量指标。网络安全。
◆垃圾邮件过滤系统
•提高过滤精度一直是一个难题。传统的机器学习算法包括贝叶斯分类器,支持向量机,决策树等分类算法,使用自然语言处理技术从普通和垃圾邮件的文本内容中提取特征,然后训练分类器来判断垃圾邮件。
•实际应用中的挑战:数据收集环节中的困难,样本标注和分类的工作量繁重,数据不平衡以及数据存在噪声等问题。
•机器学习的学习类型:有监督学习和无监督学习。通过在训练数据集中找到模式(规律),当前仍然需要数据分析人员的参与
◆机器学习在工业领域中的应用主要是在质量管理,灾难预测,缺陷预测,工业分类,故障感知等几个方面。
◆通过人工智能技术的使用,实现了智能化和无人化的制造和检测,并且使用深度学习算法进行判断的精确率与手动判断的精确率几乎相同。
◆工业机器人将深度学习算法应用于工业机器人上可以大大提高其操作性能,并实现了自动化和无人化的制造过程。
◆商品或零件的分类采用合适的分类算法对商品进行识别,同时可以使用强化学习(ReinforcementLearning)算法来实现商品的定位和拣起动作。
◆故障检测和预警机器学习用于分析物联网中各种传感器所提取的数据,并结合历史故障记录,硬件状态指示器等相关的信息建立预测模型,以预测机器中的异常情况。
◆故障定位建立决策树等分类模型来判断故障原因,快速定位并提供修复建议,减少故障的平均修复时间(MTTR),以此降低由于停机造成的损失。
机器学习在工业领域的应用中的瓶颈
(1)数据质量
有监督方法训练可以得到很好的效果,但是前提是需要大量的标记数据,并且数据的质量,归一化方法,分布因素等对模型的效果影响很大。例如,如果数据量太多,则需要更高的计算能力和计算成本;反之,如果数据量太少,则模型的预测能力通常较差。
(2)工程师经验
机器学习的相关算法和方法具有一定的阈值,如果对算法的原理理解不透彻的情况下进行实验,将很难获得理想的结果,因此,不仅要求工程师具有实现工程的能力,而且还要求他们具有线性代数,统计分析等相关理论基础,并对数据科学和机器学习中常用算法的数学计算过程有一定的理解。
(3)计算能力
由于需要在深度学习训练的过程中不断地进行参数的调整,甚至重新设计网络结构,因此训练建模的周期通常需要数周甚至数月,随着模型复杂度的增加,对计算资源(GPU)的要求也越来越高,一般情况下,模型越大应用时效率就越低。
(4)机器学习的不可解释性
在机器学习中,深度学习模型在解释模型中的参数方面较差,在工业应用中,如果除了结果之外还需要对学习的过程进行相关的解释的话,则实施起来会更加困难。另外,深度学习对数据质量有很高的要求,如果存在缺失值之类的问题,那么将会有较大的误差出现。
•美国波士顿的PilotMovies公司使用了算法来进行票房的预测,将需要预测的电影与1990年以来的每部电影进行比较,预测的准确率可以超过80%。
•人工智能和大数据还用于分析娱乐行业的其他方面,比如,分析观众愿意为哪些内容付费等问题。
•芬兰的一家公司Valossa开发出一个AI平台,该平台可以实现检测和识别视频中的人物,视频的上下文,视频的主题,视频的命名实体,视频的话题和视频的敏感内容,该系统使用计算机视觉,机器学习和自然语言处理等相关技术为每秒的视频均创建元数据。
•IRIS.TV公司使用一个叫作广告计划管理器(CampaignManager)的工具来使观看者在视频内容上的停留时间更长,并且还可以插入品牌视频广告,并且视频浏览的保留率平均提高了70%。其主要原理是在客户观看视频时收集各种相关数据,并将其输入到机器学习模块中以推荐更多相关的视频。大数据创建的智能视频分发模型可以帮助视频平台实现其视频内容的准确分发,并增加内容演示的次数。
算法定义:自动分析数据并从中获取模式(规律),之后使用模式预测未知数据的方法。
算法分类:监督学习,非监督学习和半监督学习。
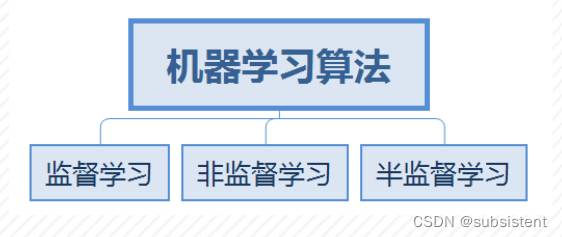
◆监督学习是从标记的训练数据中学习并建立模型,然后基于该模型预测未知的样本。其中,模型的输入是某个样本数据的特征,而函数的输出是与该样本相对应的标签。
◆常见的监督学习算法:回归分析、统计分析和分类。
◆监督学习分类:分类:包括逻辑回归,决策树,KNN,随机森林,支持向量机,朴素贝叶斯等机器学习算法;预测:包括线性回归,KNN,GradientBoosting和AdaBoost等机器学习算法。机器学习算法分类---监督学习
非监督学习也称为无监督学习,该类算法的输入样本不需要标记,而是自动地从样本中学习这种特征以实现预测。
常见的无(非)监督学习算法:聚类和关联分析
在人工神经网络中,自组织映射(SOM)和适应性共振理论(ART)是最常见的无监督学习算法。
◆半监督学习只有少量的标记数据,完全靠这些不完全标记的数据不可能训练好一个模型,依靠大量的无监督数据来提高算法性能。因此,只有选择半监督学习来使数据的价值达到最大化,使机器学习模型能够从庞大的数据集中挖掘出其隐藏规律。
◆经过研究人员的不懈努力和长期坚持,半监督学习的发展取得了一定的成效,提出了不少半监督学习方法,也应用到了不少实际领域当中。
◆半监督学习的研究仍然存在许多待解决的问题,未来的研究大门正等着大家去开启。
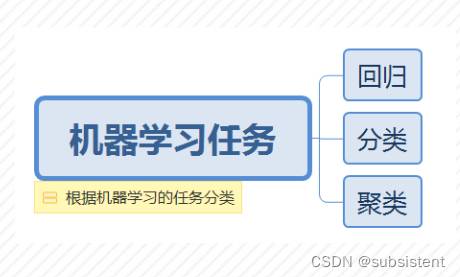
机器学习可以分为三种常见的机器学习任务:回归,分类和聚类。
某些机器学习算法可能同时属于不同的类别,例如,某些深度学习算法可能存在于监督学习中,也可能存在于半监督学习中。在具体的实践过程中,可以根据实际需要进行具体地选择。
◆熟悉各种分析方法的特性是选择分析方法的基础,不仅需要了解如何使用各种分析算法,还需要了解其实现的过程以及原理,以便可以在参数优化和模型改进过程中减少无效的调整
◆在选择模型之前,有必要对数据进行探索性分析,了解数据类型和数据的相关特征,并发现各个变量之间的关系以及自变量和因变量之间的关系
◆当存在多个维度时,特别注意变量的多重共线性问题,可以使用箱形图,直方图和散点图来查找规律性信息
◆在模型选择过程中,首先选择多个可能的模型,然后进行详细分析,然后选择可用于分析的模型。在选择自变量时,在大多数情况下,有必要结合业务手动选择自变量。
◆选择模型完毕后,需要比较不同模型的拟合度,统计显著性参数,R^2,调整R^2,最小信息标准,BIC和误差标准,Mallow'sCp标准等
◆在单个模型中,数据可以划分为训练集以及测试集,作为交叉验证和结果稳定性分析的数据集。反复调整参数可使模型更加稳定以及更加有效
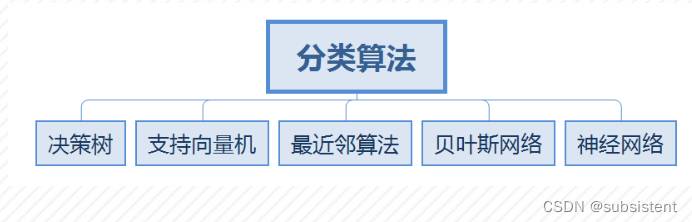
分类算法
◆定义:将分类规则应用于记录的目标映射,将它们划分为不同的分类,并建立具有泛化能力的算法模型,即构建映射规则以预测未知样本的类别
分类算法任务
◆分类:经过训练而建立的预测模型在遇到未知样本时会使用建立好的模型对未知样本进行类别的划分
◆描述:描述性分类主要解释和区分现有数据集中的特征,例如,描述动植物的各项特征,并进行标注分类,通过这些特征来确定它们属于哪个类别
机器学习的分类算法包括:决策树,支持向量机(SupportVectorMachine,SVM),最近邻(K-NearestNeighbor,KNN)算法,贝叶斯网络(BayesNetwork)和神经网络等算法。
◆决策树是用于决策的树,目标类别作为叶子节点,特征属性的验证被视为非叶子节点,每个分支都是特征属性的输出结果。
◆决策树擅长评估人员,位置和事物的不同品质和特征,并且可以应用于基于规则的信用评估和竞争结果的预测等
◆决策树的决策过程:从根节点开始,测试不同的特征属性,根据不同的结果选择分支,最后落入某个叶子节点以获得分类结果
◆主要的决策树算法:ID3,C4.5,C5.0,CART,CHAID,SLIQ,SPRINT等算法。
◆决策树的构建过程:根据属性的优先级或重要性逐渐确定树的层次结构,以使叶子节点尽可能属于同一类别,通常情况下,采用局部最优的贪心(贪婪)策略来进行决策树的构建。
◆支持向量机(SupportVectorMachine,SVM)是由瓦普尼克(Vapnik)等人设计的一款分类器,其主要思想是将低维特征空间中的线性不可分问题进行非线性映射,将其映射到高维空间去,从而转化为线性可分的问题
◆应用结构风险最小理论在特征空间优化分割超平面,找到的分类边界尽可能地宽,以便于该算法更加适用于二分类问题,例如,二维平面图中的某些点无序排列,仅仅使用一条直线无法将其准确地划分为两个类别,但是如果将其映射到三维空间中,可能存在一个平面可以实现将这些杂乱无序的点划分为两个类别分类算法---支持向量机
◆为了避免从低维空间到高维空间的转换过程中存在的计算复杂性的增加和“维数灾难”等问题的出现,支持向量机使用了核函数,故不用担心非线性映射的显式表达式问题,直接构建它们在高维空间中的线性分类器,降低了整个过程中的计算复杂度。
◆常见的支持向量核函数包括线性核函数,多项式核函数,径向基函数和二层神经网络核函数等
◆支持向量机是典型的二分类算法,可以用于多个类别的划分问题,但是实现的效果不佳
◆支持向量机在小样本数据集中有很好的分类效果
◆最近邻算法将向量空间模型应用于样本,将高度相似的样本划分为一个类别,之后计算与新样本最接近(最相似)的样本的类别,则新样本就属于这些样本中类别最多的那一类。
◆影响分类结果的因素:距离计算方法,近邻样本的数量等等
◆最近邻算法支持多种相似度距离计算方法:欧氏距离(EuclideanDistance)、切比雪夫距离(ChebyshewDistance)、标准化欧氏距离(StandardizedEuclideandistance)、巴氏距离(BhattacharyyaDistance)、夹角余弦(Cosine)、皮尔逊系数(PearsonCorrelationCoefficient)、曼哈顿距离(ManhattanDistance)、闵可夫斯基距离(MinkowskiDistance)、马氏距离(MahalanobisDistance)、汉明距离(Hammingdistance)、杰卡德相似系数(Jaccardsimilaritycoefficient)
最近邻算法的主要缺点是:
①当每一个分类样本的数量不平衡时,误差较大
②由于每一次比较都需要遍历整个训练样本集来计算其相似度,因此分类的效率较低,时间复杂度和空间复杂度较高
③选择近邻的数量如果不当,可能会导致结果误差较大④原始的最近邻算法中没有权重的概念,所有的特征均使用相同的权重系数,因此计算出的相似度容易出现误差。
◆贝叶斯网络,也称为置信网络(BeliefNetwork),是基于贝叶斯定理绘制的具有概率分布的有向弧段图形化网络,它的理论基础是贝叶斯定理,网络中的每个点都代表变量,有向弧段表示两者之间的概率关系
◆优点:与神经网络相比,贝叶斯网络中的节点更加具有实际的意义,节点之间的关系相对较为清晰,可以直观地从贝叶斯网络中看到变量之间的条件独立性和依存关系,并且可以进行结果和原因的双向推理
◆在贝叶斯网络中,随着网络中节点数量的增加,概率求解的过程非常复杂且难以计算,因此,当节点数量较大时,为了减少推理过程并降低复杂度,通常选择朴素贝叶斯算法或推理的方法实现以降低模型的复杂度
◆神经网络包括输入层,隐藏层和输出层,每个节点代表一个神经元,节点与节点之间的连接对应于权重值,当输入变量通过神经元时,它将运行激活函数以赋予输入值权重并增加偏置,输出结果将被传递到下一层的神经元中,并且在神经网络训练过程中会不断修改权重值和偏置
◆神经网络的训练过程:前向传输和逆向反馈。即将输入变量逐层向前传递,最后获得输出的结果,之后与实际结果相比较,并逐层逆向反馈错误,同时,校正神经元中的权重值以及偏置,然后再次执行前向传输,并依次重复进行迭代,直到最终预测结果与实际结果一致或在允许的误差范围内为止
神经网络的基本概念包括:感知器,反向传播算法,Hopfield神经网络,自组织映射(SOM),学习矢量量化(LVQ)等
➢BP神经网络结果的准确性与训练集的样本数量以及样本的质量有关,如果样本数量太少,则可能会出现过度拟合的情况,因此无法泛化新样本
➢BP神经网络对训练集中的异常点相对敏感,因此数据分析人员有必要对数据进行一定的数据预处理,比如数据标准化,删除重复数据和删除异常数据等操作,以提高BP神经网络的性能
➢由于神经网络是基于历史数据训练并构建的数学模型,因此随着新数据的不断生成,需要对其进行动态地优化,比如,随着时间的变化,使用新数据重新进行模型的训练,并调整网络的结构以及参数值
聚类
定义属于无监督学习,不需要标记原始数据,根据数据的固有的结构特征进行聚集。从而形成簇群,并实现数据的分离。
◆聚类和分类的主要区别
聚类不关心数据属于哪种类别,而是把具有相类似特征的数据聚集起来形成某一类别的簇。
◆聚类过程
首先选择有效的特征来构成特征向量,然后根据欧氏距离或其他距离函数来计算其相似度,从而实现对类别的划分,通过对聚类结果进行评估,逐步迭代并生成新的聚类。机器学习算法分类---聚类算法
聚类的应用领域
◆可用于发现不同公司客户群体的特征,消费者行为分析,市场细分,交易数据分析,动植物种群分类,医疗领域的疾病诊断,环境质量检测等领域,也可以用于Internet领域和电子商务领域中客户分析以及行为特征分类分析等
◆在数据分析的过程中,可以首先使用聚类来探索数据并发现其中包含的类别特征,然后使用分类等算法对每个类别的特征进行分析
聚类方法分类
基于层次的聚类(HierarchicalMethod),基于划分的聚类(PartitioningMethod,PAM),基于密度的聚类,基于约束的聚类,基于网络的聚类等。
◆基于层次的聚类:将数据集划分为不同的层次,并使用合并或者分解的操作进行聚类,主要包括BIRCH(BalancedIterativeReducingandClusteringusingHierarchies)、CURE(ClusteringUsingRepresentatives)等。
◆基于划分的聚类:将数据集划分为k个簇,然后计算其中的样本距离以获得假设簇的中心点,之后使用簇的中心点重新迭代计算新的中心点,直到k个簇的中心点收敛为止。基于划分的聚类有k-均值(k-means)等
◆基于密度的聚类
根据样本的密度不断增长聚类,最终形成一组“密集连接”的点集。
➢核心思想:只要数据的密度大于阈值,就可以将数据合并到一个簇当中,可以对噪声进行过滤,聚类的结果可以是任何形状的,不一定是凸形。
➢主要方法:DBSCAN(Density-BasedSpatialClusteringofApplicationwithNoise)、OPTICS(OrderingPointsToIdentifytheClusteringStructure)等。
BIRCH算法
使用层次方法来平衡迭代规则和聚类,它只需要扫描一次数据集即可实现聚类,它使用了类似于B+树的结构来划分样本数据集,叶节节点之间使用双向链表连接起来,逐步优化树的结构以获得聚类。
◆主要优点:空间复杂度低,内存占用量少,效率高以及具有滤除噪声点的能力。其缺点是树中节点的聚类特征树的数量是有限的,这可能会出现与实际类别数量不一致的情况。
◆BIRCH算法对样本有一定的限制,要求数据集的样本为超球体,否则聚类的效果不是很好。
◆传统的基于划分聚类的方法会得到凸形的聚类,该凸形的聚类对异常数据较为敏感;
◆CURE算法使用多个代表点来代替聚类中的单个点,算法相对更为健壮。在处理大数据时使用随机采样和分区,这使得在处理大数据样本集时更加具有时效性,而且对聚类质量没有影响
◆传统的k-均值算法的聚类过程
在样本集中随机选取k个聚类中心点,计算每个样本的候选中心的距离并且根据距离的大小将其分组,获得分组后,将重新计算聚类的中心,循环迭代,反复地进行计算,直到聚类的中心不再改变或者收敛
◆改进的k-means算法
初始化优化k-means算法,距离优化Elkank-Means算法,k-Prototype算法等。聚类算法---k-均值算法
k-means算法
◆优点:可以简单地、快速地处理大型数据集,并且具有可伸缩性,当在类别之间明确区分数据集(凸形分布)时,聚类效果最佳。
◆缺点:
➢用户需要自己确定并给出k的值,即簇的数量(聚类的数目),而对于簇的数量,事先难以确定出一个较为合理的值;
➢k均值算法对k的值较为敏感,如果k的值取得不合理,则最终的结果可能只是局部最优的。
DBSCAN算法基于样本之间的密度实现空间聚类,基于边界点,核心点以及噪声点等因素对空间中任何形状的样本数据进行聚类。
特点
◆与传统的k-均值相比,DBSCAN通过邻域半径和密度阈值自动生成聚类,无需指定聚类的数量,并支持噪声点的过滤
◆当数据量增加时,算法的空间复杂度将升高,因此,DBSCAN不适合样本之间的密度不均匀的情况,否则聚类的质量将不会很好
◆对于高维度的数据,一方面,密度的定义较为困难,另一方面,也将出现大量的计算,从而很大程度地降低了聚类的效率
背景
◆在DBSCAN算法中,用户需要指定两个初始参数,分别是ε(邻域半径)和minPts(ε邻域中的最小点数)
◆用户通过手动设置这两个参数将对聚类的结果产生较为关键的影响
OPTICS算法很好地解决了上述问题,并生成了用于聚类分析的增广的簇排序,该簇排序表示了每个样本点基于密度的聚类结构
◆关联分析(AssociativeAnalysis)是通过对数据集当中同时发生的事件的概率进行分析,从而挖掘它们之间是否存在一定的关联关系
◆关联分析的典型应用——购物篮分析,通过分析购物篮中不同商品之间的关联来分析消费者的消费行为,根据消费者的消费习惯制定个性化的营销策略,以支持产品促销,产品定价,产品地理位置的摆放等因素,除此之外,还可以用来划分不同的消费者群体。
◆关联分析主要包括的算法有:Apriori算法、FP-growth算法以及Eclat算法。
➢主要实现过程:首先生成所有的频繁项集,之后采用频繁项集构造出满足最小置信度的规则。
➢特点:由于Apriori算法需要对样本集进行多次扫描,因此需要从候选的频繁项集中生成频繁项集,故在处理大量数据时,其效率较低。
Apriori算法是一种经典的关联分析算法,用于挖掘数据集中的频繁项集和关联规则。其基本思想是通过扫描数据集多次来发现频繁项集的出现频率,并利用频繁项集生成关联规则。
下面是Apriori算法的详细步骤:
通过以上步骤,Apriori算法可以找到数据集中的频繁项集和关联规则,从而发现事物之间的关联性和依赖关系。
需要注意的是,Apriori算法的效率随着数据集大小和项集数量的增加而下降。为了提高算法效率,可以采用优化技巧,如使用哈希表来快速计算支持度、使用剪枝策略等。
基于FP树生成频繁项集的FP-growth算法
➢该算法仅扫描数据集两次,不使用候选项目集,而是根据支持程度直接构建频繁模式树,并使用该树生成关联规则,当处理相对较大的数据集时,其效率比Apriori算法大约快一个数量级
➢对于海量数据,可以通过数据分区和样本采样之类的方法再次对其进行改进和优化。
FP-growth是一种高效的关联规则挖掘算法,用于发现数据集中的频繁项集和关联规则。相比于Apriori算法,FP-growth算法通过构建FP树(Frequent Pattern Tree)来减少候选项集的生成和扫描次数,从而提高了算法的效率。
下面是FP-growth算法的详细步骤:
通过以上步骤,FP-growth算法可以高效地挖掘数据集中的频繁项集和关联规则。相比于Apriori算法,FP-growth算法在构建FP树时避免了候选项集的生成和扫描,大大提高了算法的效率。
需要注意的是,FP-growth算法的实现依赖于数据结构FP树和条件模式基的构建,在处理大规模数据时可能需要消耗较多的内存。针对大规模数据集,可以采用压缩技术和分布式计算等方法进行改进。
◆Eclat算法:一种深度优先算法,该算法使用垂直数据表示,并基于前缀的等价关系将搜索空间划分为较小的子空间,从而可以快速进行频繁项集的挖掘。
◆Eclat算法的核心思想:倒排,转换事务数据中的事务主键与项目(item),采用项目作为主键的方式。
◆好处:能够很明显地看到每个项目有哪些对应的事务ID,以方便项目频次的计算,从而迅速地获取频繁项集
特点:
➢在Eclat算法中,可以通过计算项集的交集并切割结果来快速地获得候选集的支持率。
➢由于计算交集需要很长的时间,因此在该过程中,时间复杂度高并且效率很低。
➢该算法的空间复杂度同样较高,消耗了大量的存储空间。
FP-growth(Frequent Pattern growth)算法是一种高效的关联规则挖掘算法,用于发现数据集中的频繁项集和关联规则。相比于传统的Apriori算法,FP-growth算法通过构建FP树(Frequent Pattern tree)来避免产生候选项集,从而提高了算法的效率。
下面是FP-growth算法的详细步骤:
通过以上步骤,FP-growth算法可以高效地挖掘数据集中的频繁项集和关联规则。相比于Apriori算法,FP-growth算法避免了产生候选项集的过程,减少了计算量和存储空间的消耗,因此在大规模数据集上具有更好的性能。
需要注意的是,FP-growth算法的实现依赖于FP树的构建和条件模式基的生成,在处理大规模数据时可能需要消耗较多的内存。针对大规模数据集,可以采用压缩技术、分布式计算等方法进行改进。
◆回归分析是一种预测模型,用于研究自变量和因变量之间的关系
◆核心思想:当自变量发生变化时,分析因变量的变化值,并且对自变量的要求是彼此独立。
回归分析是一种基于统计学的机器学习算法,用于建立自变量(或预测因子)和因变量之间的关系模型。回归分析可以用于预测连续型变量的值,例如房价、股票价格等。
回归分析分为单变量回归和多变量回归两种类型。
单变量线性回归:针对只有一个自变量的情况,通过最小二乘法求解最佳拟合直线,使得预测值与真实值的误差平方和最小。
多变量线性回归:针对多个自变量的情况,通过最小二乘法求解最佳拟合平面或超平面,使得预测值与真实值的误差平方和最小。
在实际应用中,除了线性回归之外还有非线性回归和泊松回归等方法。
非线性回归:当自变量和因变量之间的关系不是线性的时,采用非线性回归模型,例如指数回归、幂函数回归等。
泊松回归:适用于因变量是计数数据,且服从泊松分布的情况。泊松回归以自变量为因素,建立因变量的期望与自变量的关系,并用极大似然估计法来估计参数。
回归分析主要用于探究因变量与自变量之间的关系,并通过预测模型进行预测。同时,可以通过对模型的评估和优化来提高预测的准确性和稳定性。
常用的回归评价指标有均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)等。同时,可以采用交叉验证和正则化等方法来对模型进行优化和泛化。
在使用线性回归进行数据分析时,要求自变量是连续的,换句话说,线性回归是使用直线(也称之为回归线)来建立因变量与一个或者多个自变量之间的联系。
•主要特征:
①自变量和因变量之间的关系是线性的。
②多重共线性,自相关和异方差对多元线性回归的影响均较大。
③线性回归对异常值非常地敏感,异常值的存在会影响预测的结果。
④当同时处理的自变量较多时,需要使用逐步回归的方式来逐步确定显著性变量,而无需人工干预
核心思想:
逐个引入自变量至模型中,并执行F检验,t检验等来对变量进行筛选,当新的变量被引入且模型的结果不能得到优化时,对该变量的操作即是消除,直至模型的结果相对稳定为止。
逐步回归的目的:
选择重要的自变量,使用最少的变量来实现具有最大化预测能力的模型。
在选择变量的同时,逐步回归也是降维技术的一种,其主要方法包括前进法和后退法
◆前进法:首先选择最显著的变量,之后逐渐增加次显著变量;
◆后退法:首先选择所有的变量,并且逐渐剔除不显著的变量,即无关紧要的变量。
逻辑(Logistic)回归是数据分析当中较为常用的机器学习算法
◆算法输出是概率估算值,使用Sigmoid函数将该概率估算值映射到[0,1]区间内,便可以完成样本的类别划分。
◆逻辑回归算法对样本的数据量有一定的要求。当样本数据量较小时,概率估计存在的误差较大。
逻辑回归(Logistic Regression)是一种用于解决分类问题的线性回归算法。尽管它名为"回归",但实质上是一种分类算法,用于预测二元或多元离散的类别标签。
逻辑回归的主要思想是通过一个逻辑函数(也称为sigmoid函数)将线性回归模型的输出映射到一个概率值,该概率值表示样本属于某个类别的概率。逻辑函数的数学形式为:
P(y=1|x) = 1 / (1 + exp(-z))
其中,P(y=1|x) 表示给定输入特征 x 条件下样本属于类别 y=1 的概率,z 是线性回归模型的输出。
逻辑回归模型通过最大似然估计方法来估计模型参数。在训练过程中,通过最小化损失函数来优化模型,常用的损失函数是对数损失函数(logarithmic loss)。针对二元分类问题,对数损失函数的形式为:
L(w) = -[y*log(P(y=1|x)) + (1-y)*log(1-P(y=1|x))]
其中,w 是模型参数,y 是真实的类别标签。
逻辑回归可以通过梯度下降等优化方法进行模型参数的求解。在预测阶段,通过将输入特征带入到训练好的模型中,利用逻辑函数得到样本属于不同类别的概率值,并根据设定的阈值进行分类。
逻辑回归具有以下特点:
1. 简单而高效:逻辑回归计算成本低,并且易于实现。
2. 可解释性强:逻辑回归能够提供模型参数的解释和各个特征对结果的影响程度。
3. 鲁棒性好:逻辑回归对于异常值和噪声的影响较小。
4. 可扩展性强:逻辑回归可以通过引入正则化项等方法来处理过拟合问题。
需要注意的是,逻辑回归假设数据服从伯努利分布或二项分布,因此适用于二元分类问题。对于多元分类问题,可以借助一对多(One-vs-All)或一对一(One-vs-One)的策略进行拓展。
逻辑回归在实际应用中广泛使用,如广告点击率预测、欺诈检测等。然而,逻辑回归对于特征工程的依赖较大,需要对数据进行适当的预处理和特征选择,以提升模型性能。
在回归分析中,有时会遇到线性回归的较差的直线拟合效果,如果发现散点图中的数据点是多项式曲线,则可以考虑使用多项式回归进行分析。
◆多项式回归的使用可以减少模型的误差,但是如果处理不当,很容易导致模型过拟合,回归分析完成后,需要对结果进行分析,并对结果进行可视化以查看拟合程度。
多项式回归(Polynomial Regression)是一种通过拟合多项式函数来解决回归问题的机器学习算法。与线性回归不同,多项式回归可以拟合出更复杂的曲线关系,从而更好地适应非线性的数据分布。
在多项式回归中,我们通过将输入特征的多项式项添加到线性模型中,来扩展线性模型的表达能力。其数学形式为:
y = w0 + w1*x + w2*x^2 + ... + wn*x^n
其中,y 是待预测的因变量,x 是自变量,w0、w1、...、wn 是模型的参数,n 是多项式的阶数。
多项式回归的关键在于选择适当的多项式阶数。当阶数为1时,多项式回归等价于线性回归;当阶数大于1时,多项式回归能够拟合出曲线关系,并更好地描述数据间的非线性关系。
多项式回归的步骤如下:
1. 准备数据:收集并准备包含自变量和因变量的数据集。
2. 特征转换:将自变量进行特征转换,添加多项式项,并进行标准化处理。
3. 模型训练:使用训练数据拟合多项式回归模型,估计模型参数。
4. 模型评估:使用测试数据评估模型的性能,可以借助均方误差(Mean Squared Error)等指标进行评估。
5. 模型预测:利用训练好的多项式回归模型进行预测。
需要注意的是,多项式回归容易在阶数较高时导致过拟合问题,即模型过度拟合训练数据,而在新的未见数据上表现不佳。因此,在选择多项式的阶数时需要权衡模型的复杂度和泛化能力,可以通过交叉验证等方法选择合适的阶数。
多项式回归在实际应用中常用于描述非线性关系,如物理学中的运动规律、经济学中的消费行为等。然而,多项式回归也存在一些问题,如对噪声敏感、计算复杂度高等,因此在实践中需要结合具体问题进行选择和优化。
◆岭回归广泛用于共线性数据分析,岭回归也称为岭回归,它是有偏估计的回归方法,在最小二乘估计方法的基础上进行了改进,通过舍弃最小二乘法的无偏性,使回归系数更加稳定和稳健。
岭回归(Ridge Regression)是一种用于解决线性回归中的过拟合问题的技术,其主要思想为通过引入正则化项来限制模型参数的大小,从而降低模型的复杂度。
在线性回归中,我们可以使用最小二乘法估计模型参数。然而,当自变量之间存在多重共线性(Multicollinearity)时,即自变量之间存在高度相关性时,最小二乘法的估计会变得不稳定,容易受到噪声的干扰,导致过拟合问题。
岭回归通过在损失函数中引入L2正则化项,对模型参数进行惩罚,使得模型参数更加平滑、稳定,从而降低过拟合风险。其数学形式为:
min ||y - Xw||^2 + alpha * ||w||^2
其中,y 是因变量,X 是自变量的设计矩阵,w 是待求解的模型参数,alpha 是正则化系数,||w||^2 表示 w 的平方和。
需要注意的是,正则化系数 alpha 控制了正则化项对模型参数的影响程度,因此需要根据实际情况进行选择和调整。当 alpha=0 时,岭回归退化成普通的最小二乘法;当 alpha 值较大时,对模型参数的惩罚力度增大,会导致模型更加趋向于简单、稳定。
岭回归的主要优点包括:
1. 能够有效处理自变量之间存在多重共线性的情况,减少过拟合问题。
2. 可以通过交叉验证等方法来确定正则化系数的最佳取值。
3. 能够保留所有自变量,不需要进行特征选择。
岭回归在实际应用中广泛使用,如金融行业中的股票价格预测、生物学中的基因表达分析等。然而,岭回归也存在一些缺点,如不易处理非线性关系、对异常值敏感等,因此需要针对具体问题进行选择和优化。
LASSO回归的特征与岭回归的特征相似,在拟合模型的同时进行变量筛选和复杂性调整。
◆变量筛选:将变量逐步放入模型中,以获得自变量的更好组合。
◆复杂度调整:通过参数调整来控制模型的复杂度,例如减少自变量的数量,以避免过拟合。
LASSO回归还擅长处理多重共线性以及具有一定噪声和冗余的数据,并且可以支持对连续因变量,二元、多元离散变量的数据分析。
LASSO回归(Least Absolute Shrinkage and Selection Operator Regression)是一种用于线性回归的正则化方法,与岭回归类似。LASSO回归通过在损失函数中引入L1正则化项,对模型参数进行惩罚,从而实现特征选择和模型稀疏性。
与岭回归相比,LASSO回归的优势之一在于它能够将某些模型参数压缩到零,从而实现自动的特征选择。这是因为L1正则化项具有稀疏化的特性,它倾向于使得一部分模型参数为零,从而将相关特征排除在模型之外。
LASSO回归的数学形式为:
min (1/2n) * ||y - Xw||^2 + alpha * ||w||
其中,y 是因变量,X 是自变量的设计矩阵,w 是待求解的模型参数,alpha 是正则化系数,||w|| 表示 w 的L1范数。
与岭回归类似,LASSO回归也可以通过调整正则化系数 alpha 的取值来控制特征选择的程度。当 alpha=0 时,LASSO回归退化成普通的最小二乘法;当 alpha 值较大时,对模型参数的惩罚力度增加,会导致更多的模型参数被压缩到零,从而实现了特征选择。
LASSO回归的主要优点包括:
1. 能够自动进行特征选择,剔除对目标变量影响较小的特征,提高模型的解释能力和泛化能力。
2. 可以通过交叉验证等方法来确定正则化系数的最佳取值。
3. 产生稀疏模型,减少模型复杂度,避免过拟合问题。
LASSO回归在实际应用中广泛使用,如基因表达分析、图像处理、金融数据分析等。然而,LASSO回归也存在一些缺点,如对相关特征的选择有时不稳定、不易处理相关特征等,因此需要根据具体问题进行选择和优化。
◆深度学习方法:使用多个隐藏层和大量数据来学习特征,以提高分类或预测的准确性,与传统的神经网络相比,它不仅具有更多的层次,而且还采用了逐层的训练机制来对整个网络进行训练,以防止梯度扩散
◆深度学习:受限玻尔兹曼机(RBM),卷积神经网络(CNN),深度神经网络(DNN),对抗性神经网络(GAN),深度信念网络(DBN),层叠自动编码器(SAE),循环神经网络(RNN),以及各种变体的网络结构
◆这些深度神经网络可以对训练集数据进行特征提取以及模式识别,然后应用
◆受限玻尔兹曼机(RBM)主要解决概率分布问题,该算法是玻尔兹曼机的一种变体,是基于物理学中的能量函数进行建模,“受限”指的是层与层之间存在着连接,层内的单元之间并没有连接
◆RBM使用随机神经网络来对概率图模型(ProbabilisticGraphicalModel)进行解释,所谓“随机”是指网络中的神经元是随机神经元
◆输出的状态仅有两种:即未激活状态与激活状态,具体处于哪一个状态是由概率统计而定的。
◆卷积神经网络(ConvolutionalNeuralNetwork)中,卷积指的是源数据和滤波矩阵之间的内积运算,以实现特征权重的融合,并且可以通过设置不同的滤波矩阵来对不同的特征进行提取。
◆优点:将大量复杂的特征进行抽象和提取,并且极大程度地减少模型的计算量
◆应用:图像识别,文本分类等领域
◆深度信念网络(DBN)由杰弗里·欣顿(GeoffreyHinton)提出,作为早期深度生成式模型的代表,初衷是在样本的数据与标签之间建立联合分布。
◆DBN是由多个RBM层组成的,RBM层中的神经元分为两个类别:分别是可见神经元以及隐性神经元。可见神经元是接收输入的神经元,而提取特征的神经元称之为隐藏神经元
◆通过对神经元之间的权重进行训练,训练生成的模型既可以用于特征的识别,也可以使整个神经网络根据最大概率生成训练数据
◆长短期记忆(LongShort-termMemory,LSTM)神经网络,是一种循环神经网络,它具有长期和短期记忆,具有更好的控制记忆的能力,避免了梯度衰减,以及经过层层传递的值,最终出现退化的现象。
◆在LSTM的结构中,采用一个称为“门(gate)”的结构或者记忆单元来进行内存的控制,该门实现在正确的时间传输或重置其值
◆优点:LSTM除了具有其他循环神经网络的优点之外,还具备更好的记忆能力
◆应用:自然语言处理,语言翻译以及智能问答等
◆深度学习方法在图像,视频识别,模式检测,音频以及分类等多个领域均已经非常成熟。
◆在将深度学习的相关方法应用于实际的数据分析时,请注意训练集:验证集:测试集之间的样本分配通常为6:2:2比例分布。
◆使用深度学习的相关方法进行数据分析时,对数据量也有一定要求,如果数据量很少,只有几千条数据甚至几百条数据,那么过拟合的问题就很容易发生,其训练的效果可能还不如采用支持向量机等分类算法进行数据分析。
明确目标任务是第一个需求,也是选择合适的机器学习算法的关键所在。通过阐明业务需求以及要解决的实际问题,才能根据现有的数据进行模型的设计以及算法的选择。
在监督学习中,分类算法用于定性问题,而回归方法用于定量分析。
在无监督学习中,如果存在样本分割,则可以应用聚类算法。如果需要找出各种数据项之间的内部联系,则可以应用关联分析。
1.数据应具有代表性,并尽可能地覆盖区域,不然的话,可能出现过拟合和欠拟合的情况。
2.样本数据应平衡。在分类问题的范畴中,如果存在不同类别之间的样本比例较大的情况或者样本数据不平衡的现象,均会影响最终模型的性能。
3.评估数据的量级,包括特征的数量以及样本的数量。根据这些指标估计数据和分析对内存的消耗,并判断在训练过程中内存是否过大,如果内存过大则需要对算法进行优化、改进,或者通过对某些降维技术的使用实现内存消耗合理化,必要的话甚至还会采用一些分布式机器学习的技术。
1.数据探索
首先通过对数据进行一定的探索,了解数据的基本结构,数据的统计信息,数据噪声和数据分布等相关信息。
为了更好地对数据的状况进行查看以及数据模式的获取,可以采用数据质量评估以及数据可视化等相关方法来评估数据的质量。
2.数据处理
经过步骤1,可能会发现很多数据质量的问题,例如缺失值,不规则的数据,数据的分布不平衡,数据异常和数据冗余等问题。这些问题的存在将严重降低数据的质量。
数据预处理的操作也是非常重要,在生产环境中的机器学习中,数据通常是原始的,未经过加工以及处理的,而数据预处理的工作通常占据着整个机器学习过程中的绝大部分时间。
常见的数据预处理的方法:缺失值处理,离散化,归一化,去除共线性等方法是机器学习算法。整理预处理
采用特征选择的方法,可以实现从大量的数据中提取适当的特征,并将选择好的特征应用于模型的训练中,以获得更高精度的模型。
筛选出显著特征需要对业务有非常充分的了解并分析数据。特征选择是否合适通常会对模型的精度有非常直接的影响。选择好的特征,即使采用较为简单的算法,也可以获得较为稳定且良好的模型。
特征有效性分析的技术:相关系数、平均互信息、后验概率、卡方检验、条件熵、逻辑回归权重等方法。
在训练模型之前,通常将数据集分为训练集与测试集,有的时候,会将训练集继续细分为训练集和验证集,以评估模型的泛化能力。
模型本身不存在好坏之分。在进行模型的选择时,通常,没有哪一种算法在任何情况下都能够表现良好,在实际进行算法的选择时,通常,采用几种不同的算法同时进行模型的训练,之后再比较它们之间的性能,并选择其中表现最佳的算法。
不同的模型采用不同的性能指标。
在模型训练的过程中,需要调整模型的超参数。
在训练的过程中,对机器学习算法的原理以及其推导的过程的要求越高,对机器学习算法的了解越深,就越容易找到问题出现的原因,从而进行合理的模型调整。
利用测试集数据对模型的精度进行评估与测验,以便评估训练模型对新数据的泛化能力。
假如评估的效果不是很理想,那么就需要分析模型效果不理想的原因并对训练模型进行一定的优化与改进,例如手动调整参数等改进方法。
评估不理想,需要首先诊断模型以确定模型调整的正确思路与方向。过度拟合和欠拟合问题的判断是模型诊断中的重要步骤。
典型方法:绘制学习曲线和交叉验证。
如何解决:
出现过度拟合问题时,其模型的基本调整策略是在增加数据量的同时能够降低模型的复杂度,也可以采用正则化的方法来提高训练模型的泛化能力。
对于模型欠拟合的问题,其模型的基本调整策略是在增加特征数量和质量的同时也增加模型的复杂度。
误差分析是通过对产生误差的样本进行观察并且分析误差的原因。
误差分析的过程:由数据质量的验证,算法选择的验证,特征选择的验证,参数设置的验证等几部分。对数据质量的验证非常重要,通常对参数进行反复地调整,在调整了很长时间之后,才发现数据预处理效果不佳,数据的质量存在一定的问题。
调整模型后,需要对其进行重新训练以及模型评估。
建立机器学习模型的过程也是不断尝试的过程,直至最后模型达到最佳且最稳定的状态。
在工程实施方面,主要通过预处理、特征清理以及模型集成等方式来提高算法的精确度以及泛化能力。
通常,直接对参数进行调整的工作不是太多。因为当数据的量级达到一定的程度时,其训练的速度非常地缓慢,并且不能保证效果。
模型的应用主要和工程的实施有很大的关系。
工程以结果为导向的,模型在线执行的效果与模型的质量有着非常直接的关系,不仅简单地包括其准确性,误差等方面的信息,还包括其资源消耗的程度(空间复杂度)、运行速度(时间复杂度)以及稳定性是否可以接受等方面的问题。
在机器学习和人工智能领域,Python是最受欢迎的编程语言之一。Python的设计哲学是‘优雅’、‘明确’、’简单‘,属于通用型的编程语言。本章介绍机器学习常用的几个python库及其基础使用。
统计学是关于认识客观现象总体数量特征和数量关系的科学
Numpy是一个Python库,提供了多维数组对象(ndarray)以及用于处理这些数组的函数。它是数据科学和机器学习领域最常用的库之一。Numpy提供了高效的数组操作和数学函数,使得在Python中进行数值计算更加简单和高效。
Numpy提供了丰富的函数和方法,可以进行数组的操作、数学运算、统计分析等。以上仅是Numpy的基本使用和一些统计学中常用的功能示例,你可以进一步了解Numpy文档和官方教程以深入学习和应用。
Numpy是一个Python库,用于处理多维数组和执行数值计算。在大数据分析和统计学中,Numpy提供了许多功能和工具,可用于处理大规模的数据集、执行矩阵操作和实现统计分析。以下是Numpy在大数据和统计学中的一些常见用法:
处理大规模数据集: Numpy的核心数据结构是ndarray(n-dimensional array),它可以存储大规模的数据集。使用Numpy,你可以高效地加载、存储和处理大型数据集,执行各种数据操作,如筛选、排序和变换。
矩阵操作: Numpy提供了丰富的函数和方法来执行矩阵操作,例如矩阵乘法、转置、逆矩阵等。这些功能对于处理大规模数据集和执行线性代数运算非常有用。
统计分析: Numpy提供了许多统计学中常用的函数和方法,可以对数据进行统计分析。一些常见的统计函数包括计算平均值(mean)、方差(variance)、标准差(standard deviation)、协方差(covariance)等。通过这些函数,你可以分析数据的分布、测量变量之间的相关性,并从数据中获取有关整体趋势和特征的信息。
随机数生成: 在大数据和统计学中,随机数生成是一个常见的需求。Numpy提供了多种生成随机数的函数,如正态分布(numpy.random.normal)、均匀分布(numpy.random.uniform)等。可以利用这些函数生成大量的随机样本,用于模拟、实验和统计推断。
数值计算优化: 当处理大型数据集时,效率是一个重要的考虑因素。Numpy通过底层的C语言实现和优化的算法,提供了高效的数值计算能力。它可以直接操作多维数组,避免了Python中循环的开销,因此非常适合处理大数据集和高维数据。
总结来说,Numpy在大数据和统计学中是一个强大的工具,它提供了高效的数据结构和函数,用于处理大规模数据集、执行矩阵运算和进行统计分析。掌握Numpy的使用对于在机器学习和统计学领域进行数据处理和分析是非常有帮助的。
统计学在机器学习中起着重要的作用,它提供了数据分析和模型评估的基础。Numpy作为一个强大的数值计算库,为统计学在机器学习中的应用提供了许多有用的函数和工具。以下是统计学在机器学习中的一些常见应用以及Numpy的基本使用:
1. 数据探索和预处理:
在机器学习中,我们通常需要对数据进行探索和预处理,以了解数据的分布、特征和异常值。Numpy提供了各种统计函数,如平均值、方差、百分位数等,可以帮助我们计算这些统计量并获取有关数据集的信息。
2. 特征工程:
特征工程是机器学习中至关重要的一步,它涉及到从原始数据中提取有用的特征来训练模型。Numpy提供了丰富的函数和方法,可以对特征进行变换、缩放和归一化等操作。例如,通过使用Numpy的函数,我们可以对特征进行标准化,将其转化为具有零均值和单位方差的分布。
3. 概率分布和随机变量:
在机器学习中,概率分布和随机变量是一些重要的概念。Numpy提供了许多常见的概率分布函数,如正态分布、均匀分布、泊松分布等。我们可以使用这些函数生成服从特定分布的随机数样本,并用于模拟、生成人工数据或执行统计推断。
4. 模型评估和验证:
统计学在机器学习中也被广泛用于模型的评估和验证。Numpy提供了诸如误差计算、交叉验证、混淆矩阵等用于模型评估的函数和方法。我们可以使用这些函数来计算模型的性能指标,如准确率、精确率、召回率等,并对模型进行有效的验证和比较。
5. 统计推断:
统计推断是机器学习中的重要环节,它涉及通过已知数据来做出关于总体的推断。Numpy提供了一些统计学的函数和方法,例如假设检验、置信区间估计等。我们可以使用这些函数来进行统计推断,并基于推断结果做出决策。
总结来说,统计学在机器学习中有广泛的应用,而Numpy作为一个强大的数值计算库,为这些应用提供了丰富的功能和工具。通过使用Numpy,我们可以对数据集进行探索和预处理,进行特征工程,处理概率分布和随机变量,进行模型评估和验证,以及进行统计推断。深入理解和熟练运用Numpy中的统计学函数,对于在机器学习中进行数据分析和建模是非常重要的。
Numpy的全称是Numerical Python,作 为 高 性 能 的 数 据 分 析 以 及 科 学 计 算 的 基 础 包,Numpy提供了矩阵科学计算的相关功能。Numpy提供的功能主要分为以下几个:
1.提供了数组数据快速进行标准科学计算的相关功能。
2.提供了有用的线性代数,傅里叶变换和随机数的相关功能。
3.ndarray—一个具有向量算术运算和复杂广播能力的多维数组对象。
4.用于读写磁盘数据的工具以及用于操作内存映射文件的工具。
5.提供了集成Fortran以及C/C++代码的工具。
【注】上述所提及“广播”的意思可以理解为:当存在两个不同维度数组(array)进行科学运算时,由于Numpy运算时需要相同的结构,可以用低维的数组复制成高维数组参与运算。
Python官网上的发行版是不包含NumPy模块的,即如果使用Numpy需要自行安装,安装的方式有以下几种:
(1)使用pip安装
使用pip工具进行NumPy的安装是最简单且快速的方法,使用如下命令即可完成安装:
pip install --user numpy
--user选项的功能是可以设置numpy只安装在当前用户下,而不是写入到系统目录中。该命令在默认情况下使用的是国外线路,速度很慢,故推荐使用清华镜像进行下载并安装:
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
(2)使用已有的发行版本
对于大多数用户,尤其是在Windows操作系统上,其实最简单的方法是下载Anaconda Python发行版,因为anaconda集成了许多数据科学计算的关键包(包括NumPy,SciPy,matplotlib,IPython,SymPy以及Python核心自带的其它包)。
Anaconda:是开源且免费Python发行版,适用于大规模数据处理、预测分析,和科学计算,实现包的简化管理和部署,并且支持Linux,Windows和Mac等系统。
通过该实验的实践,要求大家可以掌握不同维度数组的表示形式,熟悉ndarray的属性和基本操作,能够使用Numpy进行数组的运算、统计和数据存取等操作。
ndarray的属性和基本操作
创建一个numpy.ndarray对象:
>>>import numpyas np
>>>a= np.array([[1,2,3],[4,5,6]])
>>>a
运行结果如下:
array([[1, 2, 3],[4, 5, 6]])
ndarray对象的别名是array:
>>>type(a)
运行结果如下:
numpy.ndarray
确定各个维度的元素个数:
>>>a.shape
运行结果如下:
(2, 3)
元素个数:
>>>a.size
运行结果如下:
6
数据的维度:
>>>a.ndim
运行结果如下:
2
数据类型:
>>>a.dtype
运行结果如下:
dtype('int32')
每个元素的大小,以字节为单位:
>>>a.itemsize
运行结果如下:
2
访问数组的元素:
>>>a[0][0]
运行结果如下:
1
从列表创建:
>>>import numpyas np
>>>np.array([[1,2,3],[4,5,6]],dtype=np.float32)
运行结果如下:
array([[1., 2., 3.],[4., 5., 6.]], dtype=float32)
从元组创建
>>>np.array([(1,2),(2,3)])
运行结果如下:
array([[1, 2],[2, 3]])
从列表和元组创建
>>>np.array([[1,2,3,4],(4,5,6,7)])
运行结果如下:
array([[1, 2, 3, 4],[4, 5, 6, 7]])
类似range()函数,返回ndarray类型,元素从0到n‐1
>>>np.arange(5)
运行结果如下:
array([0, 1, 2, 3, 4])
(1)切片
Numpy支持切片操作,以下为相关例子说明:
import numpyas np
matrix=np.array([[10,20,30],[40,50,60],[70,80,90]])
print(matrix[:,1])print(matrix[:,0:2])
print(matrix[1:3,:])
print(matrix[1:3,0:2])运行结果:
[20 50 80][[10 20][40 50][70 80]][[40 50 60][70 80 90]][[40 50][70 80]]
(2)数组比较
Numpy也提供了较为强大的矩阵和数组比较功能,对于数据的比较,最终输出的结果为boolean值。为了方便理解,举以下例子来说明:
import numpyas np
matrix=np.array([[10,20,30],[40,50,60],[70,80,90]])
m=(matrix==50)
print(m)运行结果:
[[False False False][False True False][False False False]]
我们再来看一个比较复杂的例子:
import numpyas np
matrix=np.array([[10,20,30],[40,50,60],[70,80,90]])
second_column_50=(matrix[:,1]==50)
print(second_column_50)
print(matrix[second_column_50,:])
运行结果:
[False True False][[40 50 60]]
(3)替代值
NumPy可以运用布尔值来替换值。
在数组中:
import numpy
vector =numpy.array([10,20,30,40])
equal_to_ten_or_five=(vector==20)|(vector==20)
vector[equal_to_ten_or_five]=200
print(vector)运行结果:
[10 200 30 40]
在矩阵中:
import numpy
matrix=numpy.array([[10,20,30],[40,50,60],[70,80,90]])
second_column_50=matrix[:,1]==50
matrix[second_column_50,1]=20
print(matrix)运行结果:
[[10 20 30][40 20 60][70 80 90]]
这里,我们演示把空值替换为“0”的操作。
import numpyas np
matrix=np.array([['10','20','30'],['40','50','60'],['70','80','']])
second_column_50=(matrix[:,2]=='')
matrix[second_column_50,2]='0'
print(matrix)运行结果:
[['10' '20' '30']['40' '50' '60']['70' '80' '0']]
(4)数据类型转换
在Numpy当中,ndaray数组的数据类型可以使用dtype参 数 进 行 设 置,还可以通过astype方法进行数据类型的转换,该方法在进行文件的相关处理时很方便、实用,值得注意的是,使用astype()方法对数据类型进行转换时,其结果是一个新的数组,可以理解为对原始数据的一份复制,但不同的是数据的数据类型。
比如,把String转换成float。如下:
import numpy
vector=numpy.array(["22","33","44"])
vector=vector.astype(float)
print(vector)
运行结果:
[22. 33. 44.]
(5)Numpy的统计计算方法
Numpy基本使用除了以上介绍的相关功能,Numpy还内置了更多地科学计算的方法,尤其是最为重要的统计方法,如下:
1.max():用于统计计算出数组元素当中的最大值;对于矩阵计算结果为一个一维数组,需要指定行或者列。
2.mean():用于统计计算数组元素当中的平均值;对于矩阵计算结果为一个一维数组,需要指定行或者列。
3.sum():用于统计计算数组元素当中的和;对于矩阵计算结果为一个一维数组,需要指定行或者列。
值得注意的是,用于这些统计方法计算的数值类型必须是int或者float。
数组例子:
import numpy
vector=numpy.array([10,20,30,40])
print(vector.sum())运行结果:
100
矩阵例子:
import numpyas np
matrix=np.array([[10,20,30],[40,50,60],[70,80,90]])
print(matrix.sum(axis=1))
print(np.array([5,10,20]))
print(matrix.sum(axis=0))
print(np.array([10,10,15]))运行结果:
[ 60 150 240][ 5 10 20][120 150 180][10 10 15]
Pandas简介
官网链接:http://pandas.pydata.org/
简介:Pandas是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。
强大的Pandas
基本功能
开发pandas时提出的需求
具备按轴自动或显式数据对齐功能的数据结构
集成时间序列功能
既能处理时间序列数据也能处理非时间序列数据的数据结构
数学运算和约简(比如对某个轴求和)可以根据不同的元数据(轴编号)执行
灵活处理缺失数据
合并及其他出现在常见数据库(例如基于SQL的)中的关系型运算
数据结构
Series(一维)
DataFrame(二维)
Panel(三维)
数据结构Series
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成
Series的字符串表现形式为:索引在左边,值在右边
三方面来了解Series
创建
读写
运算
数据结构Series的创建
>>>ser1= Series(range(4))
>>>ser2 = Series(range(4),index = ["a","b","c","d"])
>>>sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
>>>ser3 = Series(sdata)
注:传递的data是一个dict字典类型对象,并且传递了index参数,那么对应的值将从字典中取出。否则,index的值将由字典对象里的key值进行构造
Series的index和values
>>>ser2.index
Index(['a', 'b', 'c', 'd'], dtype='object')
>>>ser2.values
array([0, 1, 2, 3])
>>>ser2[["a","c"]]
a 0
c 2
数据结构Series的读写
>>>a = pd.Series([11, 22, 33, 44, 55])
>>>a[1:3]
1 22
2 33
>>>a[1]=2
>>>a[1:3]
1 2
2 33
数据结构Series的运算
Series间的计算
>>>a = pd.Series([1, 2, 3, 4])
>>>b = pd.Series([1, 2, 1, 2])
>>>print(a + b)
>>>print(a *2)
>>>print(a >= 3)
>>>print(a[a >= 3])
Series函数的使用
>>>a = pd.Series([1, 2, 3, 4, 5])
平均值
>>>print(a.mean())
数据结构DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)
几方面来了解DataFrame
创建
索引
apply方法
算术运算
缺失值处理
数据结构DataFrame的创建
二维的ndarray
>>>import pandas as pd
>>>df1=pd.DataFrame(np.arange(9).reshape(3,3),columns=list('bcd'),index=['b','s','g'])
外部导入
>>>import pandas as pd
>>>df = pd.read_csv('./data/titanic.csv')
字典导入
>>>import pandas as pd
>>>data = {'country':['aaa','bbb','ccc'], 'population':[10,12,14]}
>>>df_data = pd.DataFrame(data)
使用Series导入
>>>d = {'one' : pd.Series([1., 2., 3.], index=['a', 'b', 'c']), 'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
>>>df = pd.DataFrame(d)
>>>pd.DataFrame(d, index=['d', 'b', 'a'])
数据结构DataFrame的查看
>>>df.head(6)
>>>df.info()
>>>df.index
>>>df.columns
>>>df.dtypes
>>>df.values
数据结构的索引对象
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都可以被转换成一个Index。
指定索引
>>>df = df.set_index('Name')
pandas中主要的index对象

Index的方法和属性1
Index的方法和属性2
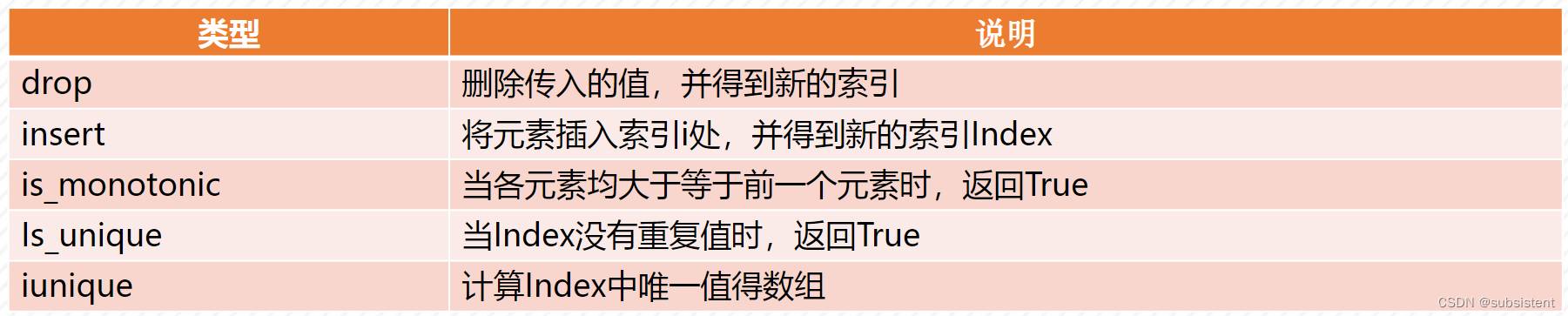
索引操作
loc用label来去定位,iloc用position来去定位
>>>df.iloc[0:5,1:3]
>>>df = df.set_index('Name')
>>>df.loc['Heikkinen, Miss. Laina']
>>>df.loc['Heikkinen, Miss. Laina':'Allen, Mr. William Henry']
重新索引
创建一个适应新索引的新对象,该Series的reindex将会根据新索引进行重排。如果某个索引值当前不存在,就引入缺失值
reindex函数的参数

reindex操作
>>>s1 = pd.Series(['a','b','c','d','e'],index=[2,1,3,5,4])
>>>s2 = s1.reindex([1,2,3,4,5,6],fill_value=0)
>>>s3 = s2.reindex(range(10),method='bfill')
groupby操作
>>>df = pd.DataFrame({'key':['A','B','C','A','B','C','A','B','C'], 'data':[0,5,10,5,10,15,10,15,20]})
>>>df.groupby('key').sum()
>>>df = pd.read_csv('./data/titanic.csv')
>>>df.groupby('Sex')['Age'].mean()
函数应用和映射
DataFrame的apply方法(index)
对象的applymap方法(因为Series有一个应用于元素级的map方法)
DataFrame的apply方法
>>>def plus(df,n):
>>>df['c'] = (df['a']+df['b'])
>>>df['d'] = (df['a']+df['b']) * n
>>>return df
>>>list1 = [[1,3],[7,8],[4,5]]
>>>df1 = pd.DataFrame(list1,columns=['a','b'])
>>>df1 = df1.apply(plus,axis=1,args=(2,))
>>>print(df1)
DataFrame的applymap方法
对象的applymap方法(因为Series有一个应用于元素级的map方法)
apply对一个列进行整体运算
applymap对一个DataFrame中的每个元素进行转换
map对一个Series中的每个元素进行转换
排序和排名
对行或列索引进行排序
对于DataFrame,根据任意一个轴上的索引进行排序
可以指定升序降序
按值排序
对于DataFrame,可以指定按值排序的列
rank函数
>>>df = pd.DataFrame([1, 2, 3, 4, 5], index=[10, 52, 24, 158, 112], columns=['S'])
>>>df.sort_index(inplace=True)
对于DataFrame,可以指定按值排序的列
>>>frame = pd.DataFrame({'b':[4, 7, -3, 2], 'a':[0, 1, 0, 1]})
>>>frame.sort_values(by='b')
算术运算
对不同的索引对象进行算术运算
对齐操作会同时发生在行和列上,把2个对象相加会得到一个新的对象,其索引为原来2个对象的索引的并集:
>>>df1 = pd.DataFrame(np.arange(9).reshape(3,3),columns=list('bcd'),index=['b','s','g'])
>>>df2 = pd.DataFrame(np.arange(12).reshape(4,3),columns=list('cde'),index=['b','s','g','t'])
>>>df1+df2
>>>df3 = df1.add(df2,fill_value='0')
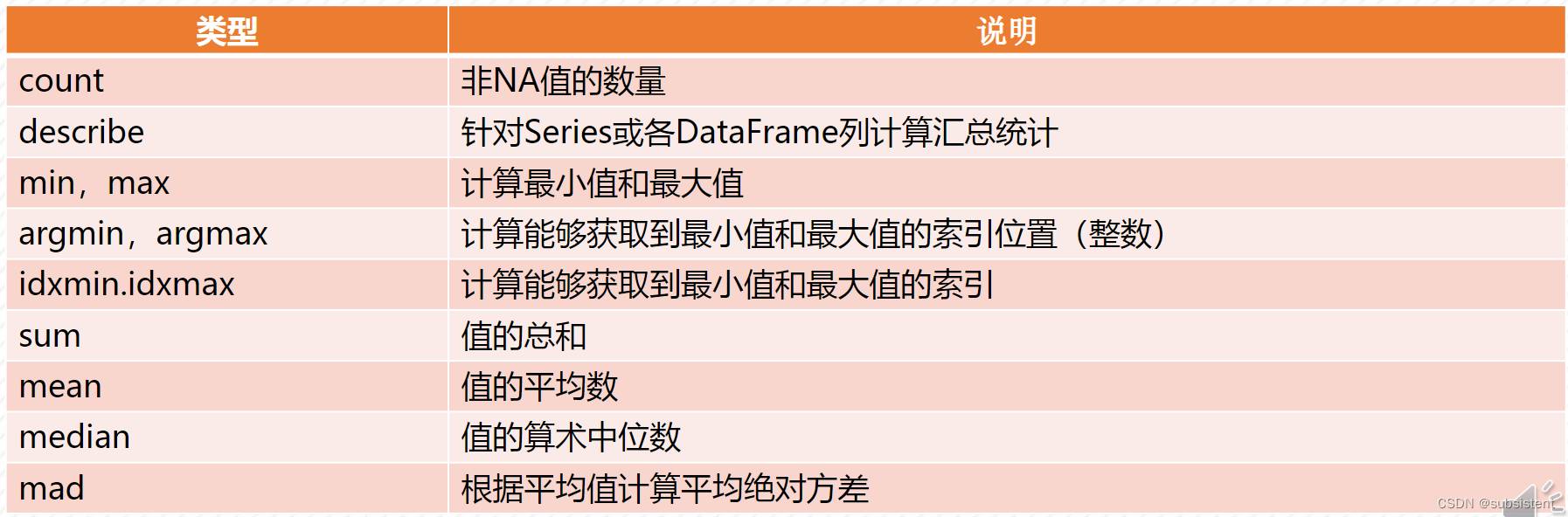
汇总和计算描述统计
常用描述和汇总统计函数
唯一值以及成员资格

缺失数据处理
NaN(Not a Number)表示浮点数和非浮点数组中的缺失数据
None也被当作NAN处理
处理缺失数据滤除缺失数据方法
dropna()
drop()
how参数控制行为,axis参数选择轴,thresh参数控制留下的数量
处理缺失数据滤除缺失数据
>>>ser = pd.Series([4.5,7.2,-5.3,3.6], index=['d','b','a','c'])
>>>ser.drop('c')
>>>from numpyimport NaN
>>>se1=pd.Series([4,NaN,8,NaN,5])
>>>se2 = se1.dropna()
>>>se2
>>>df = DataFrame(np.arange(9).reshape(3,3), index=['a','c','d'], columns=['oh','te','ca'])
>>>df.drop('a')
>>>df.drop(['oh','te'],axis=1)
>>>df1=pd.DataFrame([[1,2,3],[NaN,NaN,2],[NaN,NaN,NaN],[8,8,NaN]])
>>>df1.dropna()
>>>df1.dropna(how='all')
处理缺失数据填充缺失数据
fillna
inplace参数控制返回新对象还是就地修改
>>>from numpy import nan as NaN
>>>df1=pd.DataFrame([[1,2,3],[NaN,NaN,2],[NaN,NaN,NaN],[8,8,NaN]])
>>>df1.fillna(100)
>>>df1.fillna({0:10,1:20,2:30})
传入inplace=True直接修改原对象
>>>df1.fillna(0,inplace=True)
>>>df2=pd.DataFrame(np.random.randint(0,10,(5,5)))
>>>df2.iloc[1:4,3]=NaN
>>>df2.iloc[2:4,4]=NaN
>>>df2.fillna(method='ffill')#用前面的值来填充
>>>df2.fillna(method='bfill',limit=2) #传入limit=” “限制填充个数:
>>>df2.fillna(method="ffill",limit=1,axis=1) #传入axis=” “修改填充方向:
实验实现Pandas自行车数据分析
假设我们现在有些自行车行驶数据,这组数据记录的是蒙特利尔市内七条自行车道的自行车 骑 行 人 数,让 我 看 看 我 们 能 用Pandas分 析 出 一 些 什 么 吧,原 始 数 据 集bikes.csv可 以 在Pandas官方网址上进行下载。
(1)导入Pandas:
>>>import pandas as pd
(2)准备画图环境:
>>>import matplotlib.pyplotas plt
>>>pd.set_option('display.mpl_style', 'default')
>>>plt.rcParams['figure.figsize'] = (15, 5)
(3)使用read_csv函数读取csv文件,读取一组自行车骑行数据,得到一个DataFrame对象:
# 使用latin1编码读入,默认的utf-8编码不适合
>>>broken_df= pd.read_csv('bikes.csv', encoding='latin1')
# 查看表格的前三行
>>>broken_df[:3]
Date;Berri1;Brébeuf (donnéesnon disponibles);Côte-Sainte-Catherine;Maisonneuve1;Maisonneuve 2;du Parc;Pierre-Dupuy;Rachel1;St-Urbain (donnéesnon disponibles)
0 01/01/2012;35;;0;38;51;26;10;16;
1 02/01/2012;83;;1;68;153;53;6;43;
2 03/01/2012;135;;2;104;248;89;3;58;(4)对比原始文件的前五行即图2-1和导入的DataFrame数据结构,我们发现读入的原始数据存在以下两个问题:即使用“;”作为分隔符(不符合函数默认的“,”作为分隔符)和首列的日期文本格式为xx/xx/xxxx(不符合Pandas的时间日期格式)。
head-n5bikes.csv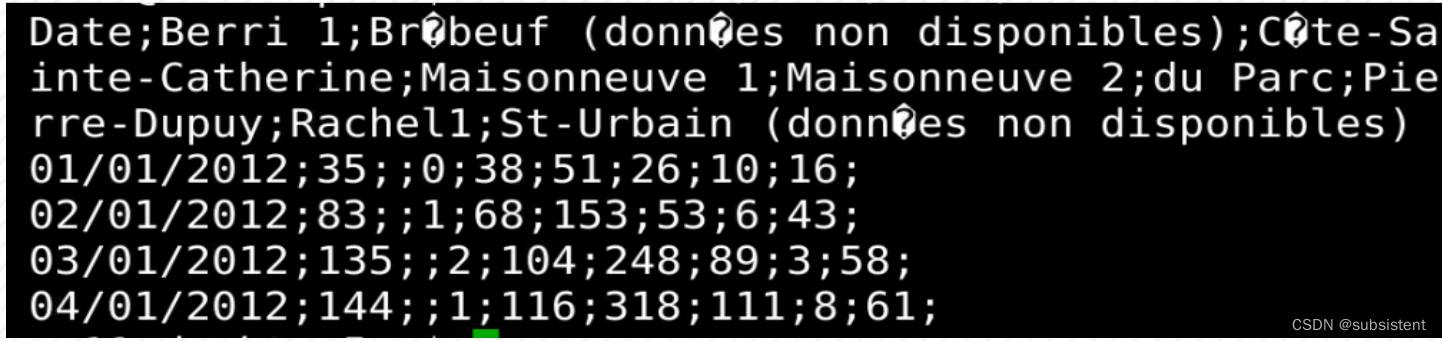
(5)修复读入问题:
1)使用“;”作为分隔符
2)解析Date列(首列)的日期文本
3)设置日期文本格式
4)使用日期列作为索引
>>>fixed_df=pd.read_csv('bikes.csv',encoding='latin1',sep=';',parse_dates=['Date'],dayfirst=True,index_col='Date')
>>>fixed_df[:3]
Berri 1 Brébeuf (données non disponibles) Côte-Sainte-Catherine \
Date
2012-01-01 35 NaN 0
2012-01-02 83 NaN 1
2012-01-03 135 NaN 2
Maisonneuve 1 Maisonneuve 2 du Parc Pierre-Dupuy Rachel1 \
Date
2012-01-01 38 51 26 10 16
2012-01-02 68 15 35 36 43
2012-01-03 104 248 89 3 58
St-Urbain(données non disponibles)
Date
2012-01-01 NaN
2012-01-02 NaN
2012-01-03 NaN(6)读取csv文件所得结果是一个DataFrame对象,每列对应一条自行车道,每行对应一天的数据,我们从DataFrame中选择一列,使用类似于字典(dict)的语法访问选择其中的一列:
>>>fixed_df['Berri 1']
Date
2012-01-01 35
2012-01-02 83
2012-01-03 135
2012-01-04 144
2012-01-05 197
2012-01-06 146
2012-01-07 98
2012-01-08 95
2012-01-09 244
2012-01-10 397
2012-01-11 273
2012-01-12 157
2012-01-13 75
2012-01-14 32
2012-01-15 54
2012-01-16 168
2012-01-17 155
2012-01-18 139
2012-01-19 191
2012-01-20 161
2012-01-21 53
2012-01-22 71
2012-01-23 210
2012-01-24 299
2012-01-25 334
2012-01-26 306
2012-01-27 91
2012-01-28 80
2012-01-29 87
2012-01-30 219
......
2012-10-07 1580
2012-10-08 1854
2012-10-09 4787
2012-10-10 3115
2012-10-11 3746
2012-10-12 3169
2012-10-13 1783
2012-10-14 587
2012-10-15 3292
2012-10-16 3739
2012-10-17 4098
2012-10-18 4671
2012-10-19 1313
2012-10-20 2011
2012-10-21 1277
2012-10-22 3650
2012-10-23 4177
2012-10-24 3744
2012-10-25 3735
2012-10-26 4290
2012-10-27 1857
2012-10-28 1310
2012-10-29 2919
2012-10-30 2887
2012-10-31 2634
2012-11-01 2405
2012-11-02 1582
2012-11-03 844
2012-11-04 966
2012-11-05 2247
Name: Berri 1, Length: 310, dtype: int64(7)将所选择的列绘成图,可以直观地看出骑行人数的变化趋势:
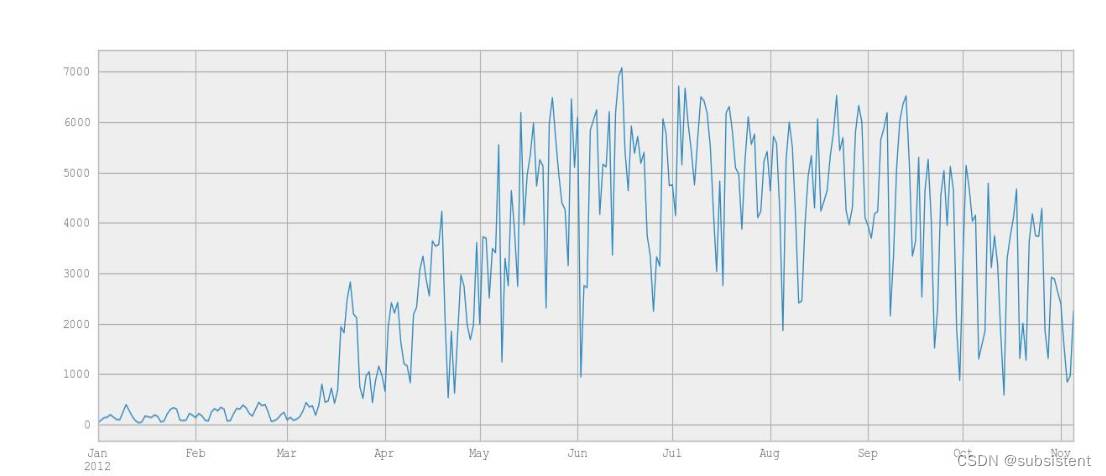
(8)绘制所有的列(自行车道)如下图,可以看到,每条车道的变化趋势都是类似的:
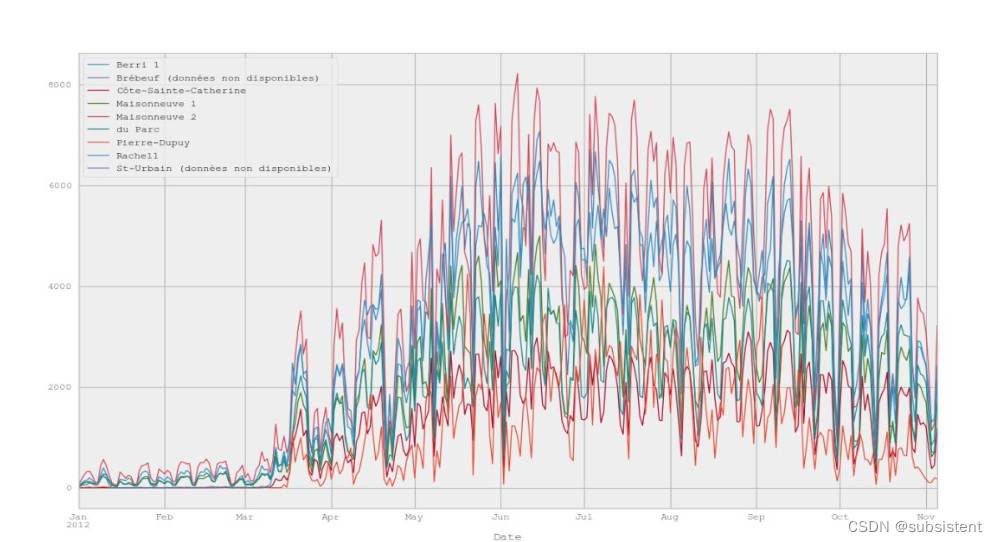
(9)假设我们住在蒙特利尔,我很好奇人们是在周末还是在工作日骑自行车?在我们的数据结构dataframe中添加一个“工作日”列,下一步,我们查看贝里自行车路径数据。贝里是蒙特利尔的一条街道,有一条非常重要的自行车道。我会去图书馆的路上骑自行车,有时去旧蒙特利尔工作的时候也常常骑自行车。因此,我们将创建一个数据框,其中只有贝里(BiKePath):
>>>berri_bikes= fixed_df[['Berri 1']].copy()
>>>berri_bikes[:5]
Berri 1
Date
2012-01-01 35
2012-01-02 83
2012-01-03 135
2012-01-04 144
2012-01-05 197(10)接下来,我们需要添加一个“工作日”列。首先,我们可以从索引中获得工作日。我们还没有谈到索引,但是索引是在上面的数据框的左边,在“日期”下。基本上是一年中的所有日子:>>>berri_bikes.index
DatetimeIndex(['2012-01-01','2012-01-02','2012-01-03','2012-01-04','2012-01-05','2012-01-06','2012-01-07','2012-01-08','2012-01-09','2012-01-10',...'2012-10-27','2012-10-28','2012-10-29','2012-10-30','2012-10-31','2012-11-01','2012-11-02','2012-11-03','2012-11-04','2012-11-05'],dtype='datetime64[ns]',name='Date',length=310,freq=None)
(11)我们可以看到实际上数据是不完整的,通过length数据可以发现,一年只有310天。为什么呢?Pandas时间序列功能非常的强大,所以如果我们想得到每一行的月份,我们可以输入以下语句:
>>>berri_bikes.index.day
Int64Index([1,2,3,4,5,6,7,8,9,10,...27,28,29,30,31,1,2,3,4,5],dtype='int64',name='Date',length=310)
(12)为普通日进行索引设置:
>>>berri_bikes.index.weekday
Int64Index([6,0,1,2,3,4,5,6,0,1,...5,6,0,1,2,3,4,5,6,0],dtype='int64',name='Date',length=310)
(13)通过上面的语句,这我们获得了一周中的单位日,我们通过与日历进行对比会发现数据中的0代表的是星期一。我们现在已经知道如何设置普通日进行索引了,我们接下来需要做的是把普通日的索引设置为dataframe中的一列:
>>>berri_bikes.loc[:,'weekday']=berri_bikes.index.weekday
>>>berri_bikes[:5]
Berri 1 weekday
Date
2012-01-01 35 6
2012-01-02 83 0
2012-01-03 135 1
2012-01-04 144 2
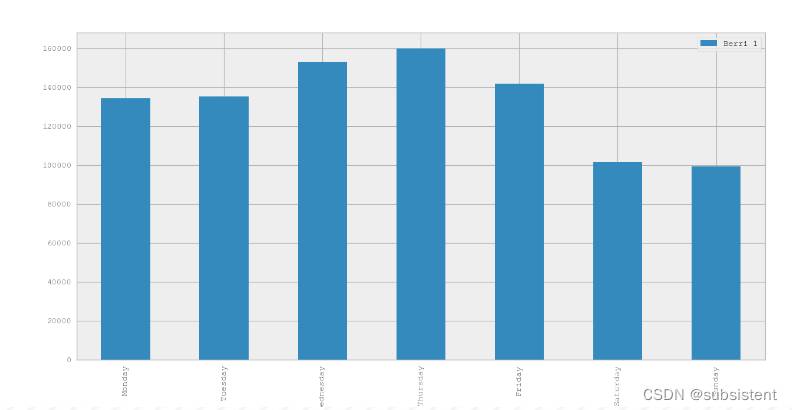
2012-01-05 197 3(14)接下来我们就可以把普通日作为一个统计日进行骑行人数的统计了,而这在Pandas中实现也非常简单,Dataframes中 存 在 一 个groupby()方法,这 个 方 法 有 点 类 似 与SQL语 句 中 的groupby方法。而 实 现 的 语 句 是,weekday_counts=berri_bikes.groupby('weekday').aggregate(sum),语句的目的是把Berri车道数据按照相同普通日的标准进行分组并累加:
>>>weekday_counts= berri_bikes.groupby('weekday').aggregate(sum)
>>>weekday_counts
Berri 1
weekday
0 134298
1 135305
2 152972
3 160131
4 141771
5 101578
6 99310(15)这时候我们会发现通过0,1,2,3,4,5,6这样的数字很难记住其相对应的日子,我们可以通过以下方法修改:
>>>weekday_counts.index=['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday']
>>>weekday_counts
Berri 1
Monday 134298
Tuesday 135305
Wednesday 152972
Thursday 160131
Friday 141771
Saturday 101578
Sunday 99310(16)通过直方图2-7看看统计情况:通过结果我们发现Montrealers似乎是一个喜欢使用自行车作为通勤工具的城市即人们在工作日也大量的使用自行车。
>>>weekday_counts.plot(kind='bar')
Matplotlib是一款功能强大的数据可视化工具。它与NumPy的无缝集成,使得Python拥有与MATLAB、R等语言旗鼓相当的能力。
通过使用plot()、bar()、hist()、和pie()等函数,Matplotlib可以方便地绘制散点图、条形图、直方图及饼形图等专业图形。
与Numpy类似,如果我们已经通过Anconada安装了Python,那么就无须再次显式安装Matplotlib了,因为它已经默认被安装了。
如果的确没有安装Matplotlib,可在控制台的命令行使用如下命令在线安装。
1)在Anaconda平台下安装
condainstall matplotlib
2)在Python平台下安装
pip install matplotlib
绘制简单图形
二维图形是人们最常用的图形呈现媒介。通常,我们使用Matplotlib中的子模块pyplot来绘制2D图形。它能让用户较为便捷地将数据图像化,并能提供多样的输出格式。
在使用pyplot模块之前,需要先显示地导入。为了使用方便,我们常为这个模块取一个别名plt。
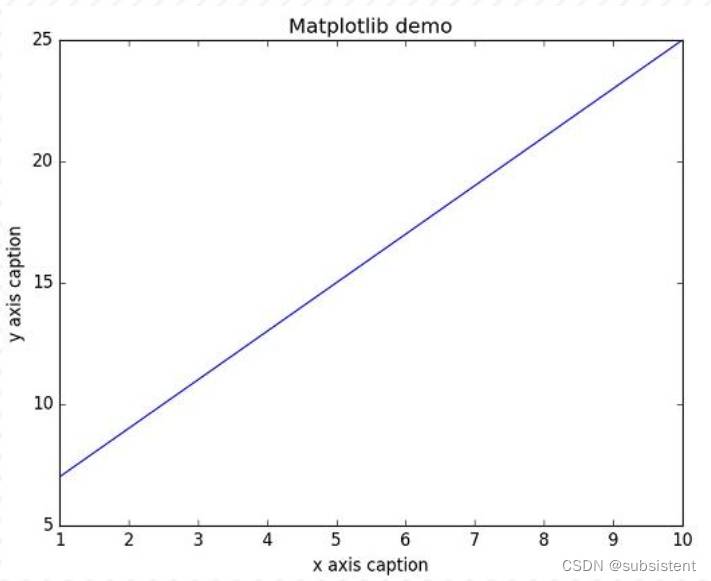
import numpy as np
from matplotlib import pyplot as plt
x=np.arange(1,11)
y=2*x+5
plt.title("Matplotlibdemo")
plt.xlabel("xaxiscaption")
plt.ylabel("yaxiscaption")
plt.plot(x,y)
plt.show()以上实例中,np.arange()函数创建x轴上的值。y轴上的对应值存储在另一个数组对象y中。这些点使用matplotlib软件包的pyplot子模块的plot()函数绘制。图形由show()函数显示。
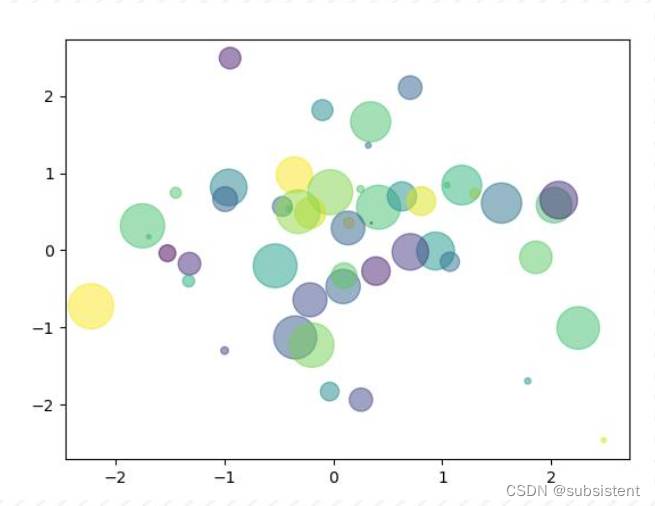
散点图
在可视化图像应用中,散点图的应用范围也很广泛。例如,如果某一个点或某几个点偏离大多数点,成为孤立点,通过散点图就可以一目了然。在机器学习中,散点图常常用在分类、聚类当中,以便显示不同类别。
在Matplotlib中,绘制散点图的方法与使用plt.plot()绘制图形的方式类似。
import matplotlib.pyplotas plt
import numpyas np
#产生50对服从正态分布的样本点
nbPointers= 50
x = np.random.standard_normal(nbPointers)
y = np.random.standard_normal(nbPointers)
# 固定种子数,以便实验结果具有可重复性
np.random.seed(19680801)
colors = np.random.rand(nbPointers)
area = (30 * np.random.rand(nbPointers))**2
plt.scatter(x, y, s = area, c = colors, alpha = 0.5)
plt.show()运行结果如图所示:
直方图
在数据可视化中,条形图常用来展示和对比可测量数据。pyplot子模块提供bar() 函数来生成条形图。
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
objects=('Python','C++','Java','Perl','Scala','Lisp')
y_pos=np.arange(len(objects))
performance=[10,8,6,4,2,1]
plt.bar(y_pos,performance,align='center',alpha=0.5)
plt.xticks(y_pos,objects)
plt.ylabel('用户量')
plt.title('数据分析程序语言使用分布情况')
plt.show()以上python代码运行结果如下:
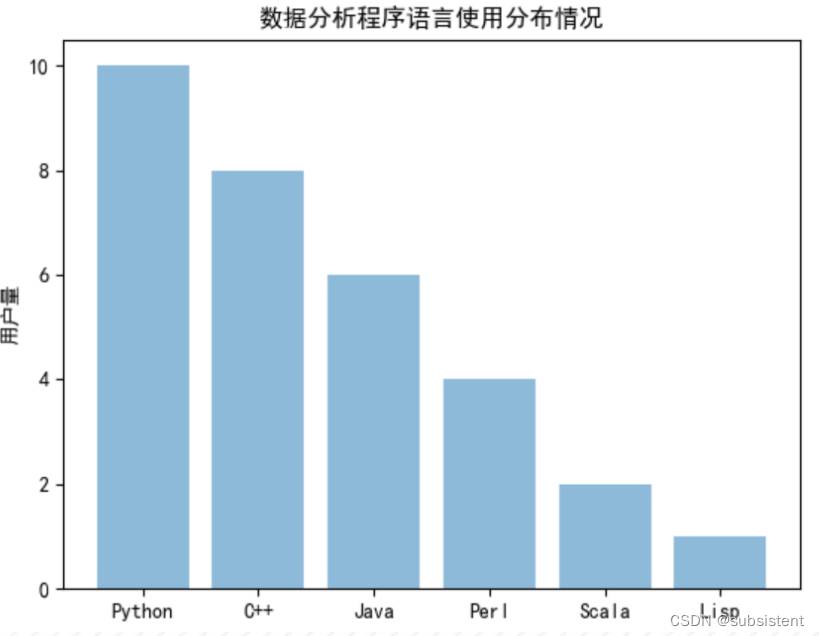
实验波士顿房价之构建回归预测模型
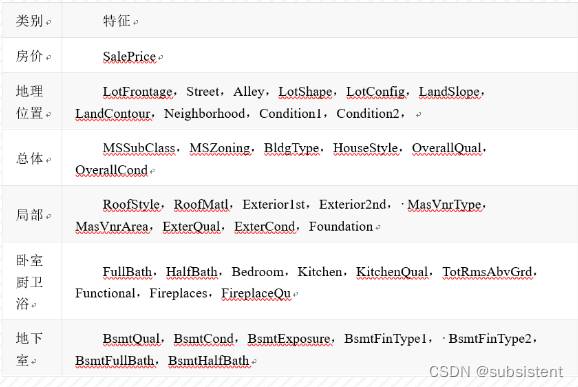
本实验所使用的数据集为经过数据清洗过的波士顿房价数据,下面对数据集中所涉及的字段做一个简单的分类说明。
为了便于过程演示,本案例基于jupyternotebook开发。本实验所使用的数据集为经过数据清洗过的波士顿房价导入相关库,并加载数据:

使用交叉验证法计算精度:定义得分函数,实例化Lasso 算法,并指定正则项系数,输出评分结果

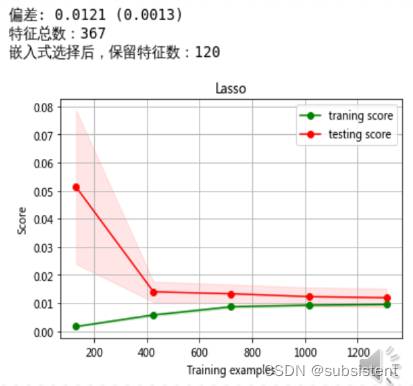
返回特征的权重系数:sklearn提供coef_ 函数返回特征的权重系数。我们使用这个函数观察嵌入式选择后,还有多少特征保留下来。

查看学习器性能:这里我们用学习曲线来观察学习器性能,最后可以看到我们的学习器很健康。




上面这段代码运行时间较长,请耐心等待。最后进行预测并保存数据:

实现效果图:
对生成的结果文件submission.csv进行查看:

实现效果图如下图所示:
回归分析是一种针对连续型数据进行预测的方法,目的在于分析两个或多个变量之间是否相关以及相关方向和强度的关系。回归分析可以帮助连接有一个自变量变化时因变量的变化。本章介绍不同回归算法及其应用,并使用python来建立回归模型进行分析。几种回归算法分别是线性回归、岭回归和LASSO回归、逻辑回归。
回归分析(regression analysis)是确定两种或两种以上变量间相互依赖定量关系的一种统计分析方法,是应用极其广泛的数据分析方法之一。作为一种预测模型,它基于观测数据建立变量间适当的依赖关系,以分析数据内在规律,并用于预测、控制等问题。
例1:假设我们想要一个能够预测二手车价格的系统。
系统输入:品牌、年龄、发动机性能、里程等我们认为会影响车价的属性信息。
输出:车的价格。
这种输出为数值的问题是回归问题。
现假设x表示车的属性,y表示车的价格。我们通过调查以往的交易情况,能够收集训练数据。而机器学习中的线性回归方法能够构造出一个函数来拟合这些数据,从而得到关于x的函数y。如下图所示,其中w和w0为待拟合的参数值,拟合函数具有如下表达式:
y=wx+w0
例2:移动机器人的导航。如自动汽车导航。
输出:每次转动的角度,使得汽车前进而不会撞到障碍物或偏离车道
输入的数值:由汽车上的传感器(如视频相机、GPS等)提供。训练数据可以通过监视和记录驾驶员的动作收集。
例3:假设要制造一个焙炒咖啡的机器。
输入数值为各种温度、时间、咖啡豆种类等配置。针对不同的输入配置进行大量实验,并检测咖啡的品质。
例如,可根据消费者的满意度测量咖啡的品质。
为寻求最优配置,我们可以先拟合一个回归模型,并在当前模型的最优样本附近选择一些新的点,来检测咖啡的品质,再将他们加入训练数据,并拟合新的模型。
预测问题可以划分为回归和分类这两大类,前者的输出为连续值,后者的输出为离散值。由于这两类问题具有不同的特点,需要使用不同的分析方法。本节将对回归问题进行讨论。
1、波士顿房价数据集
波士顿房价数据集(BostonHousePriceDataset)包含对房价的预测,以千美元计,给定的条件是房屋及其相邻房屋的详细信息。该数据集是一个回归问题。每个类的观察值数量是均等的,共有506个观察值,13个输入变量和1个输出变量。部分变量名如下:
CRIM:表示城镇人均犯罪率;
ZN:表示住宅用地超过25000英寸的比例;
INDUS:表示城镇中非商业用地的所占比例;
CHAS:表示查尔斯河虚拟变量,用于回归分析;
NOX:表示环保指数;
RM:表示每栋住宅平均房间数;
AGE:表示1940年以前建成的自住单位的比例;
DIS:表示距离五个波士顿就业中心的加权距离;
RAD:表示辐射性公路的接近指数;
TAX:表示每一万美元的不动产税率。
2、温室气体观测网络数据集
该数据集根据天气模型模拟给出的综合观测值和示踪剂的时间序列,来监测加利福尼亚的温室气体(GHG)排放得到。该数据集包含使用化学方法对天气研究和预报模型(WRF-Chem)模拟创建的加利福尼亚州2921个网格单元的温室气体(GHG)浓度的时间序列。
利用这些数据:
(1)使用逆方法来确定与合成观测值最匹配的15个示踪剂的加权总和中的权重的最佳值;
(2)使用优化方法来确定要观测的最佳位置。
数据集中的每个文件都标记为ghg.gid.siteWXYZ.dat,其中WXYZ是网格单元的位置ID。每个网格单元文件中(GHG浓度以万亿分之一为单位):
第1-15行:从区域1-15排放的示踪剂的温室气体浓度第16行:综合观测值的温室气体浓度第1-327列:自2010年5月10日至2010年7月31日,每6个小时的温室气体浓度。
数据集下载地址:
http://archive.ics.uci.edu/ml/datasets/Greenhouse+Gas+Observing+Network
3、葡萄酒质量数据集
包括来自葡萄牙北部的两个与红色和白色vinhoverde葡萄酒样品有关的数据集。目标是根据理化测试对葡萄酒质量进行建模。这两个数据集与葡萄牙“VinhoVerde”葡萄酒的红色和白色变体有关。由于隐私和物流问题,只有理化变量特征是可以进行使用的(例如,数据集中没有关于葡萄品种、葡萄酒品牌、葡萄酒销售价格等的数据)。此数据集可以视为分类或回归任务。本数据集有4898个观察值,11个输入变量和一个输出变量。变量名如下:
输入变量(基于理化测试):
1-固定酸度;2-挥发性酸度;3-柠檬酸;
4-残留糖;5-氯化物;6-游离二氧化硫;
7-总二氧化硫;8-密度;9-pH;
10-硫酸盐;11-醇;
输出变量(基于感官数据):
12-质量(得分在0到10之间)。
数据集下载地址:
http://archive.ics.uci.edu/ml/datasets/Wine+Quality
原理与应用场景
当两个或多个变量间存在线性相关关系时,常常希望在变量间建立定量关系,相关变量间的定量关系的表达即是线性回归。
给定由d个属性描述的示例x=(x1,x2,⋯,xd),其中xi是x在第i个属性上的取值,线性模型就是通过属性的线性组合构造预测的函数,即
f(x)=w1x1+w2x2+...+wdxd+b
一般用向量形式写成:
f(x)=w^Tx+b
其中w=(w1,w2,⋯,wd)。得到参数w和b之后,模型就得以确定,即线性回归模型。
特点:
形式简单、易于建模,但蕴含着机器学习中一些重要的基本思想,许多功能更为强大的非线性模型可在线性模型的基础上通过引入层级结构或高维映射获得。此外,由于푤直观表达了各属性在预测中的重要性,因此线性模型有很好的解释性。
1、以下代码定义了一个线性回归拟合函数,其中X_parameters和Y_parameter是样本点值,predict_value是要预测的自变量值。
def linear_model_main(X_parameters,Y_parameters,predict_value):
# 创建一个线性回归实例
regr= linear_model.LinearRegression()
regr.fit(X_parameters, Y_parameters) #训练模型
predict_outcome= regr.predict(predict_value)
predictions = {}
predictions[‘intercept’] = regr.intercept_ #截距项
predictions[‘coefficient’] = regr.coef_ #系数
#预测结果
predictions[‘predicted_value’] = predict_outcome
return predictions2、以下代码传入X与Y的数值,训练好模型后,对数据700进行预测,最后返回线性拟合系数푎和푏,以及预测出的因变量值。这里使用的是scikit-learn机器学习算法包。
X=[[150.0],[200.0],[250.0],[300.0],[350.0],[400.0],[600.0]]
Y=[6450.0,7450.0,8450.0,9450.0,11450.0,15450.0,18450.0]
predictvalue=[[700]]
result=linear_model_main(X,Y,predictvalue)
print("截距值:",result['intercept'])
print("常数值:",result['coefficient'])
print("预测值:",result['predicted_value'])
show_linear_line(X,Y)3、再定义一个拟合曲线绘图函数,输入是样本值X_parameters和Y_parameters,输出是样本的散点图以及拟合曲线。输出结果及图像如下所示。
def show_linear_line(X_parameters,Y_parameters):
#创建线性回归实例
regr=linear_model.LinearRegression()
regr.fit(X_parameters,Y_parameters)
plt.scatter(X_parameters,Y_parameters,color='blue')
plt.plot(X_parameters,regr.predict(X_parameters),color='red',linewidth=4)
plt.xticks(())
plt.yticks(())
plt.show()输出结果为:
截距值:1771.80851064
常数值:[28.77659574]
预测值:
[21915.42553191]
最小二乘法用于求目标函数的最优值,它通过最小化误差的平方和寻找匹配项,所以又称为:最小平方法;这里将用最小二乘法用于求得线性回归的最优解。以下是算法具体代码:
1、加载相关模块:
import numpy as np
import matplotlib.pyplot as plt
from bz2 import__author__2、构造最小二乘算法,代码如下。
seed=np.random.seed(100)#设置随机种子
#构造一个100行1列的矩阵。矩阵数值生成用rand,得到数字是0-1均匀分布的小数。
#最终得到的是0-2均匀分布的小数组成的100行1列的矩阵。这一步构建列X(训练集数据)
X=2*np.random.rand(100,1)
#构建X与y之间的函数关系,np.random.randn(100,1)给y增加波动范围。y=4+3*X+np.random.randn(100,1)
#将两个矩阵组合成一个矩阵。得到的X_b是100行2列的矩阵。其中第一列全都是1.
X_b=np.c_[np.ones((100,1)),X]
#解析theta得到最优解
theta_best=np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
#生成两个新的数据点,得到的是两个x1的值
X_new=np.array([[0],[2]])
#填充x0的值,两个1
X_new_b=np.c_[(np.ones((2,1))),X_new]
#用求得的theata和构建的预测点X_new_b相乘,得到yhat
y_predice=X_new_b.dot(theta_best)3、对结果进行可视化。结果如下图所示:
#画出预测函数的图像,r-表示为用红色的线
plt.plot(X_new,y_predice,'r-')
#画出已知数据X和掺杂了误差的y,用蓝色的点表示
plt.plot(X,y,'b.')
#建立坐标轴
plt.axis([0,2,0,15,])
plt.show()在讨论岭回归和Lasso之前,先学习两个概念:经验风险最小化和结构风险最小化。
经验风险最小化:求解最优化问题,线性回归中的求解损失函数最小化问题即是经验风险最小化策略。由统计学知识知,当训练集数据足够大时,经验风险最小化能够保证得到很好的学习效果。当训练集较小时,则会产生过拟合现象。虽然对训练数据的拟合程度高,但对未知数据的预测精确度低,这样的模型不是适用的模型。
结构风险最小化:为了防止过拟合现象而提出的策略。结构风险最小化等价于正则化,在经验风险上加上表示模型复杂度的正则项(也称惩罚项)。
而岭回归和Lasso使用的正是结构风险最小化的思想。即在线性回归的基础上,加上对模型复杂度的约束。
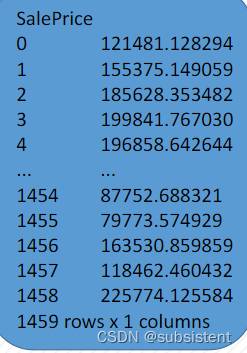
岭回归与Lasso回归的出现是为了解决线性回归出现的过拟合以及在通过正规方程方法求解휃的过程中出现的푥转置乘以푥不可逆这两类问题的,这两种回归均通过在损失函数中引入正则项来防止过拟合,三者具体的损失函数如下:

Lasso回归和岭回归的几何意义可下图,椭圆和灰色阴影区域的切点就是目标函数的最优解。我们可以看到,如果是圆形,则很容易切到圆周的任意一点,但是很难切到坐标轴上,则在该维度上的取值不为0,因此没有稀疏;但是如果是菱形或者多边形,则很容易切到坐标轴上,使得部分维度的特征权重为0,因此很容易产生稀疏的结果。
线性回归是最常用的回归分析方法,其形式简单,在数据量较大的情况下,使用该方法可以得到较好的学习效果。但在数据量较少的情况下会出现过拟合的现象。岭回归和Lasso可以在一定程度上解决这个问题。由于Lasso回归得到的是稀疏解,故除了可以用于回归分析外,还可以用于特征选取。

调用sklearn库中的线性回归模型实现岭回归算法。
首先,导 入 相 应 的 库 文 件,其中linear_model为线 性 回 归模块,reg.coef_为 预 测 模 型 的 系 数,reg.intercept_为预测模型的截距项。结果如下所示:
from sklearn import linear_model
#实例化岭回归模型,并设置alpha参数大小为0.5
reg=linear_model.Ridge(alpha=.5)
#导入x与y数据,并训练模型
reg.fit([[0,0],[0,0],[1,1]],[0,.1,1])
#打印岭回归模型的系数与截距项
print(reg.coef_)print(reg.intercept_) 接下来,我们同样调用sklearn库中的线性回归模型实现LASSO算法。首先,导入相应的库文件,其中linear_model为线性回归模块,reg.predict()为利用新建立的LASSO模型对新数据进行预测并查看结果。也可以利用reg.coef_、reg.intercept_分别求出模型的系数和截距项。结果如下所示:
接下来,我们同样调用sklearn库中的线性回归模型实现LASSO算法。首先,导入相应的库文件,其中linear_model为线性回归模块,reg.predict()为利用新建立的LASSO模型对新数据进行预测并查看结果。也可以利用reg.coef_、reg.intercept_分别求出模型的系数和截距项。结果如下所示:
from sklearn import linear_model
#实例化LASSO模型对象
reg=linear_model.Lasso(alpha=0.1)
#训练模型,并打印结果
print(reg.fit([[0,0],[1,1]],[0,1]))
#运用训练好的模型,对[1,1]进行预测,并打印预测结果
print(reg.predict([[1,1]]))
逻辑回归分析是在线性回归分析的基础上,套用了一个逻辑函数,常用于预测二值型因变量。其在机器学习领域有着特殊的地位,并且是计算广告学的核心。在运营商的智慧运营案例中,逻辑回归分析可以通过历史数据预测用户未来可能发生的购买行为,通过模型推送的精准性降低营销成本以扩大利润。
根据因变量的取值不同,逻辑回归分析可分为二元逻辑回归分析和多元逻辑回归分析。二元逻辑回归中的因变量只能取0和1两个值(虚拟因变量),而多元逻辑回归中的因变量可以取多个值(多分类问题)。
逻辑回归算法虽然名字里带“回归”,但它实际上是一种分类方法,主要用于二分类问题。对于二分类任务,其输出标记为y∈(0,1),而线性回归模型产生的预测值z=w^Tx+b是实值。
因此,我们需要将线性回归模型里的实值转换为0或1。最理想的是“单位阶跃函数”,即若预测值z大于零就判为正例,小于零则判为反例,预测值为临界值零则可任意判定。其表达式如下:

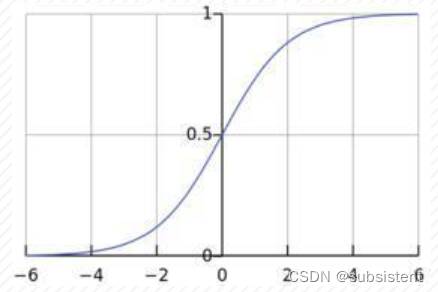
但单位阶跃函数是不连续,于是我们希望找到能在一定程度上近似单位阶跃函数的“替代函数”,并且希望它是单调可微。Logistic函数(或Sigmod函数)正是这样一个常用的替代函数,其函数形式为:
它将z值转化为一个接近0或1的y值,并且其输出值在z=0附近处斜率较为陡峭。逻辑回归分析实际上是利用线性回归模型的预测结果逼近真实标签的对数概率。
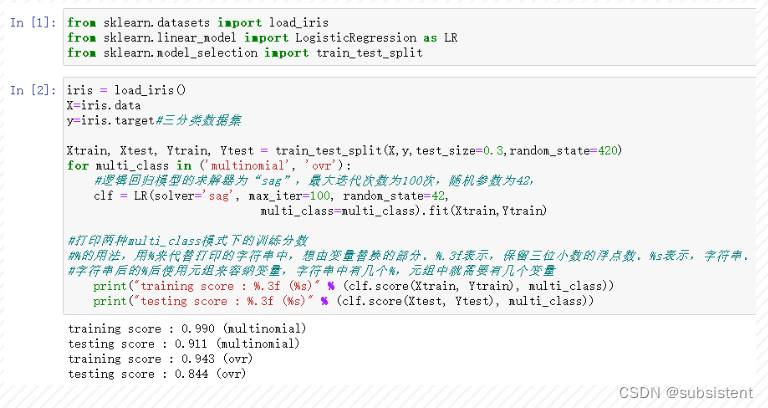
本小节利用sklearn库实现逻辑回归算法,linear_model为线性回归模块,包含了逻辑回归算法模型,model_selection模块对原始数据划分训练集与测试集,本实验的数据集为鸢尾花数据集。
1、导入实验所需库文件。
from sklearn.datasets import load_iris #加载鸢尾花数据集
from sklearn.linear_model import LogisticRegressionasLR #加载逻辑回归模型
from sklearn.model_selection import train_test_split #划分数据集为训练数据与测试数据2、加载鸢尾花,鸢尾花为三分类的数据集,并运用逻辑回归模型对其进行训练,并将训练结果打印出来。
iris=load_iris()
X=iris.data
y=iris.target #三分类数据集Xtrain,Xtest,Ytrain,Ytest=train_test_split(X,y,test_size=0.3,random_state=420)
#逻辑回归模型的求解器为“sag”,最大迭代次数为100次,随机参数为42。
for multi_class in ('multinomial','ovr'):
clf=LR(solver='sag',max_iter=100,random_state=42,multi_class=multi_class).fit(Xtrain,Ytrain)
#打印两种multi_class模式下的训练分数
#%的用法,用%来代替打印的字符串中,想由变量替换的部分。%.3f表示,保留三位小数的浮点数。%s表示,字符串。
#字符串后的%后使用元组来容纳变量,字符串中有几个%,元组中就需要有几个变量print("trainingscore:%.3f(%s)"%(clf.score(Xtrain,Ytrain),multi_class))
print("testingscore:%.3f(%s)"%(clf.score(Xtest,Ytest),multi_class))3、输出结果如下图所示,模型在两种multi_class模式下的训练集得分均高于测试集得分,说明模型存在一定的过拟合。
本章介绍机器学习的基础知识,包括特征工程、高维数据降维、超参数调优,目标是理解并掌握机器学习的主要原理。
“数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,这里的数据指的就是经过特征工程得到的数据。
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的模型准确性。
特征工程在机器学习中占有非常重要的作用。
一般来说,特征工程是指在从总体上理解数据之后,进行缺失值处理、数据的特征值化、数据特征选择、数据转换四个部分。
缺失值处理:当数据拿到手里后,首先需要查验数据是否有空缺值,对异常数据进行处理,这是缺失值处理。
特征构建:从现有数据中挑选或将现有数据进行变形,组合形成新特征。
特征抽取:当特征维度比较高,通过映射或变化的方式,用低维空间样本来表示样本的过程。
特征选择:从一组特征中挑选出一些最有效的特征,以达到降低维度和降低过拟合风险的目的。
机器学习中的原始数据往往会存在缺失值,在进行机器学习建模前需要对缺失值进行处理,处理方法包括:
直接删除:按行删除、按列删除
填充:有前后向值填充、统一值填充、统计值填充、插值法填充、建模预测填充等方法。
(1)构造数据
import numpy as np
import pandas as pd
# 构造数据
col1 = [1, 2, 3, np.nan, 5,np.nan]
col2 = [3, 13, 7, np.nan, 4, np.nan]
col3 = [3, np.nan, 10, np.nan, 4, np.nan]
y = [10, 15, 8, 14, 16, np.nan]
data = {'feature1':col1, 'feature2':col2, 'feature3':col3, 'label':y}
df = pd.DataFrame(data)
print(df)(2)使用pandas的dropna函数进行缺失值删除
# 1.按默认参数删除:
df1 = df.dropna()
print(df1)
# 2.删除值全为空的行:
df1 = df.dropna(axis=0,how='all')print(df1)
# 3.保留至少有两个非空值的行:
df3 = df.dropna(thresh=2)
print(df3)
# 4.指定列删除空缺值:
df4 = df.dropna(subset=['feature1', 'feature2'])
print(df4)
# 5.直接在原有的dataframe上删除空缺值:
dfcopy= df.copy()
df5 = dfcopy.dropna(inplace=True)
print('--df5---')
print(df5)print('--dfcopy---')
print(dfcopy)
# 6.删除包含缺失值的列,但保存至少有4个非空值的列:
df6 = df.dropna(axis=1,thresh=4)
print(df6)
(3)使用pandas的drop函数进行缺失值删除:
# 1.删除指定列:
df10 = df.drop(['feature1', 'feature2'], axis=1)
print(df10)
# 2.删除指定行:
df11 = df.drop([0,1,2,3], axis=0)
print(df11)(4)使用pandas的fillna函数进行缺失值填充
# 1.使用指定值填充所有缺失值:
df20 = df.fillna(0)
print(df20)
# 2.使用前值填充所有缺失值:
df21 = df.fillna(method='ffill')
print(df21)
# 3.使用后值填充所有缺失值:
df22 = df.fillna(method='bfill')
print(df22)
# 4.针对不同列使用不同的指定值填充缺失值:
values = {'feature1': 100, 'feature2': 200, 'feature3': 300, 'label': 400}
df23 = df.fillna(value=values)
print(df23)
# 5.针对不同列使用不同的指定值填充缺失值:
values = {'feature1': 100, 'feature2': 200, 'feature3': 300, 'label': 400}
df23 = df.fillna(value=values)
print(df23)
# 6.针对不同列使用不同的指定值填充缺失值:
values = {'feature1': 100, 'feature2': 200, 'feature3': 300, 'label': 400}
df23 = df.fillna(value=values)
print(df23)
# 7.使用统计值填充:
df24 =df.fillna(df.mean())
print(df24)将任意数据(如文本或图像)转换为可用于机器学习的数字特征。计算机没有办法直接识别文本或者图片,把文本或图像进行数字化,是为了计算机更好的去理解数据。
(1)字典数据进行特征值化
作用:对字典数据进行特征值化
类:sklearn.feature_extraction.DictVectorizerDictVectorizer的处理对象是符号化(非数字化)的但是具有一定结构的特征数据,如字典等,将符号转成数字0/1表示。
from sklearn.feature_extraction import DictVectorizer
# 默认sparse参数为True,编码后返回的是一个稀疏矩阵的对象,dict = DictVectorizer(sparse=False)
#调用fit_transform方法输入数据并转换,返回矩阵形式数据
data = dict.fit_transform([{'city': '北京','temperature': 100},{'city': '上海','temperature':60},{'city': '深圳','temperature': 30}])
# 转换后的数据
print(data)
# ['city=上海', 'city=北京', 'city=深圳', 'temperature']
#获取特征值
print(dict.get_feature_names())
# [{'city=北京': 1.0, 'temperature': 100.0}, {'city=上海': 1.0, 'temperature': 60.0},
# {'city=深圳': 1.0, 'temperature': 30.0}]
# 获取转换之前数据
print(dict.inverse_transform(data))(2)文本特征抽取
One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
类:sklearn.feature_extraction.text.CountVectorizer
CountVectorizer()函数只考虑每个单词出现的频率;然后构成一个特征矩阵,每一行表示一个训练文本的词频统计结果。该方法又称为词袋法(Bag of Words)。
#导入包
from sklearn.feature_extraction.text import CountVectorizer
#实例化CountVectorizer()
vector = CountVectorizer()
#调用fit_transform输入并转换数据
res = vector.fit_transform(["life is short,i like python","life is too long,i dislike python"])
# 获取特征值
print(vector.get_feature_names())
# 转换后的数据
print(res.toarray())特征选择的原因是部分相似特征的相关度高,容易消耗计算性能。另外部分特征对预测结果有负影响。
特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后可以改变值、也不改变值,但是选择后的特征维数肯定比选择前小,毕竟我们只选择了其中的一部分特征。
类:sklearn.feature_selection.VarianceThreshold
from sklearn.feature_selection import VarianceThreshold
#实例化VarianceThreshold()
var = VarianceThreshold()
#调用fit_transform()输入并转换数据
data = var.fit_transform([[0,2,0,3],[0,1,4,3],[0,1,1,3]])
#转换后的数据
print(data)特征构建通过特定的统计方法(数学方法)将数据转换成算法要求的数据。
常见的特征构建方法有归一化、标准和、缺失值处理。
(1)归一化
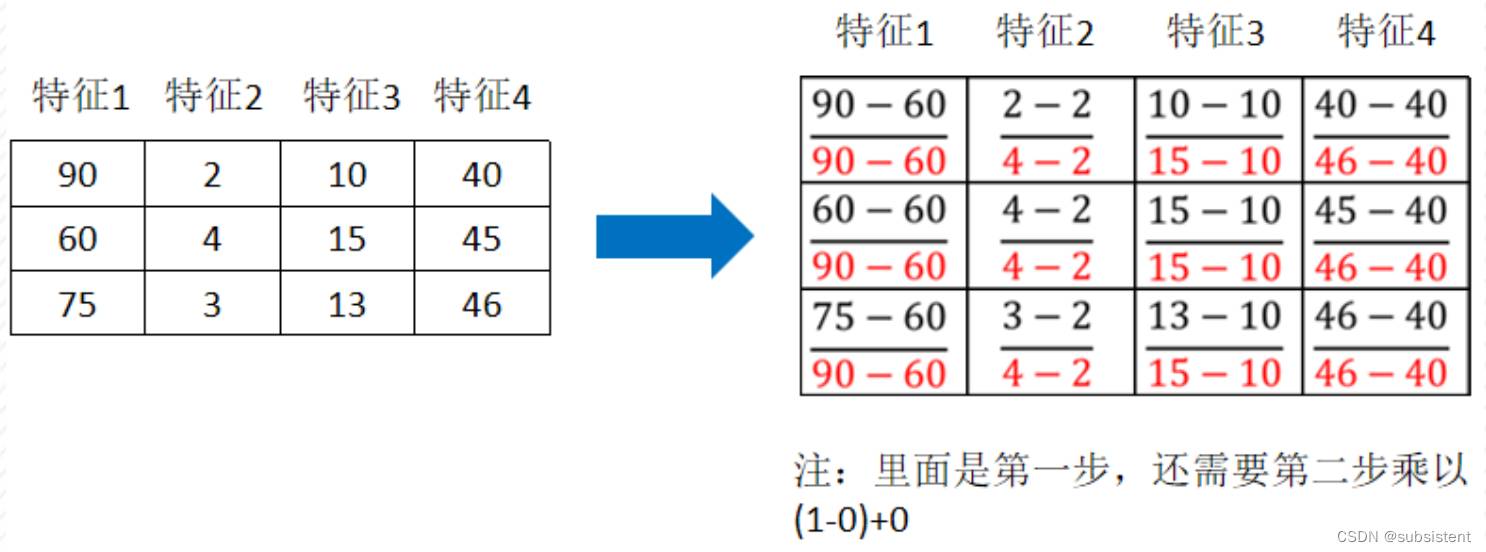
特点:通过对原始数据进行变换把数据映射到(默认为[0,1])之间
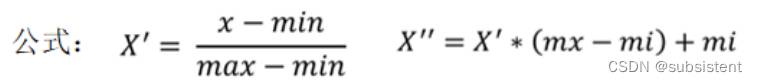
注:作用于每一列,max为一列的最大值,min为一列的最小值,那么X’’为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
归一化计算过程
sklearn归一化API: sklearn.preprocessing.MinMaxScaler
"""
归一化处理:通过对原始数据进行变换把数据映射到(默认为[0,1])之间缺点:最大值与最小值非常容易受异常点影响,这种方法鲁棒性较差,只适合传统精确小数据场景。
"""
from sklearn.preprocessing import MinMaxScaler
#实例化MinMaxScaler()
mm = MinMaxScaler()
# 调用fit_transform()输入并转换数据
data = mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
# 转换后的数据
print(data)归一化总结
注意在特定场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
(2)标准化
通过对原始数据进行变换把数据变换到均值为0,方差为1范围内。
公式: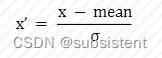
注:此公式作用于每一列,为平均值,标准差的计算公式为,表示方差,的计算公式为
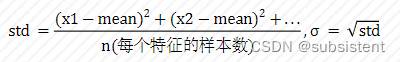

对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
sklearn标准化API: scikit-learn.preprocessing.StandardScaler
from sklearn.preprocessing import StandardScaler
#实例化StandardScaler()
standard = StandardScaler()
#调用fit_transform()输入并转换数据
data = standard.fit_transform([[1,-1,3],[2,4,2],[4,6,1]])
#转换后的数据
print(data)数据在真实世界中的表示
在真实的训练数据中总是存在各种各样的问题:存在噪声或者冗余。在这种情况下,需要一种特征降维的方法来减少特征数,减少噪音和冗余,减少过度拟合的可能性
特征维度减少的方法
实现维度减少有两种技术,既特征选择和特征提取
特征选择指的是选择原始数据集中最具代表性或者统计意义的维度特征
特征提取指的是将原始特征转换为一组具有明显物理意义或者统计意义的特征
特征选择
基于统计测试来选择最好的特征,常用的统计指标:
评分最高:SelectKBest
用户指定的最高得分百分比:SelectPercentile
假阳性率(false positive rate):SelectFpr
伪发现率(false discovery rate):SelectFdr
族系误差(family wise error):SelectFwe
特征选择的代码实现
>>> from sklearn.datasetsimport load_iris
>>> from sklearn.feature_selectionimport SelectKBest
>>> from sklearn.feature_selectionimport chi2
>>> iris = load_iris()
>>> X, y = iris.data, iris.target
>>> X_new= SelectKBest(chi2, k=2).fit_transform(X, y)
特征提取
特征提取指的是将原始特征转换为一组具有明显物理意义或者统计意义的特征
提取指的是我们并不会因此丢弃某些维度的数据,而转换指的是保留所有的维度数据,只是将高维数据投影低维数空间
特征提取的转换
思考:考虑三维到二维的转换
特征提取
常用的降维方法:
主成分分析(PCA)
因子分析(Factor Analysis)
PCA算法
主成分分析(PCA)中,数据从原来的坐标系转换到新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选择和第一个坐标轴正交且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目
PCA图示
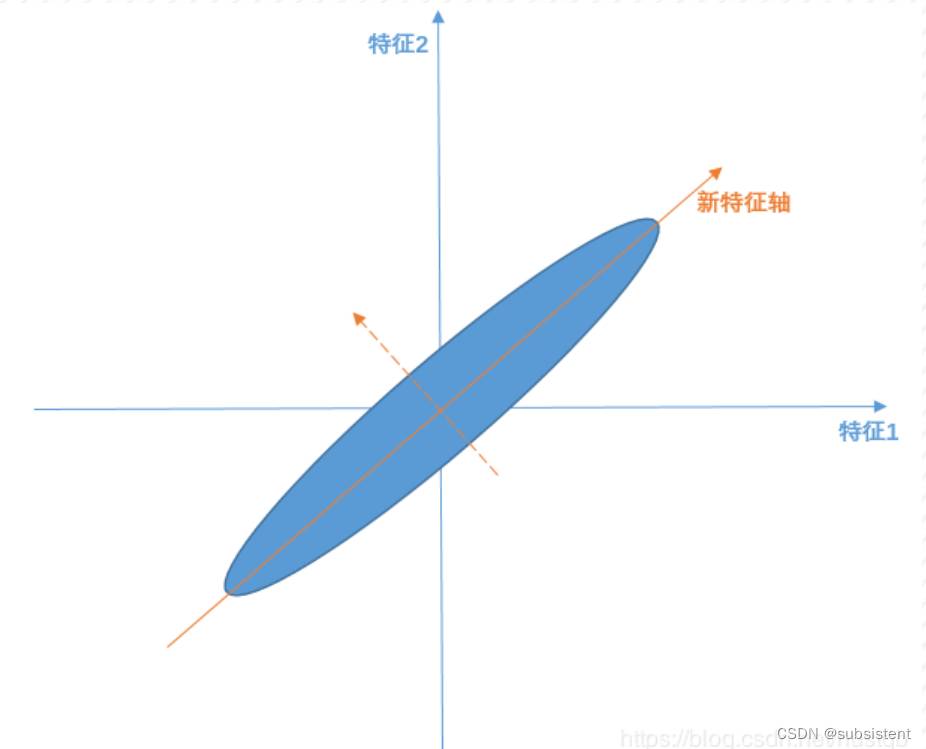
PCA算法过程
线性变换=>新特征轴可由原始特征轴线性变换表征
线性无关=>构建的特征轴是正交的
主要线性分量(或者说是主成分)=>方差最大的方向(希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述)
PCA算法的求解就是找到主要线性分量及其表征方式的过程
PCA算法的特点
相应的,PCA解释方差并对离群点很敏感:少量原远离中心的点对方差有很大的影响,从而也对特征向量有很大的影响
PCA的代码实现
>>> from sklearnimport datasets
>>> iris = datasets.load_iris()
>>> data=iris.data
>>> from sklearn.decompositionimport PCA
>>> pca=PCA(n_components=2)
>>> newData=pca.fit_transform(data)
机器学习工作流中最难的部分之一是为模型寻找最佳的超参数。所谓超参数,就是机器学习模型里面的框架参数,比如聚类方法里面类的个数,或者话题模型里面话题的个数等等,都称为超参数。
(1)交叉验证
交叉验证为了让被评估的模型更加准确可信。
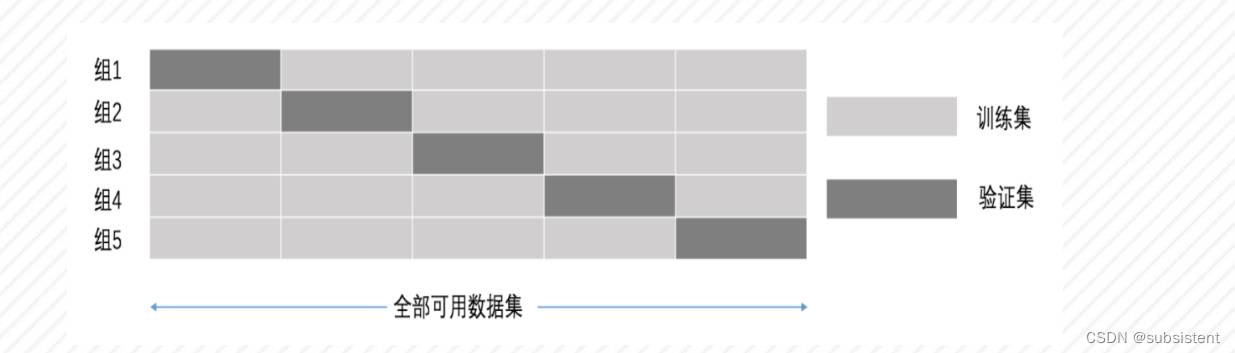
不同的训练集、测试集分割的方法将会导致模型的准确率不同,而交叉验证(Cross Validation) 的基本思想是将数据集进行一系列分割,生成多组不同的训练与测试集对,然后分别训练模型并计算测试准确率,最后对结果进行平均处理,从而有效降低测试准确率的差异。
简单交叉验证:将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此分类器的性能指标。好处:处理简单,只需随机把原始数据分为两组即可。坏处:由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关系,得到的结果并不具有说服性。
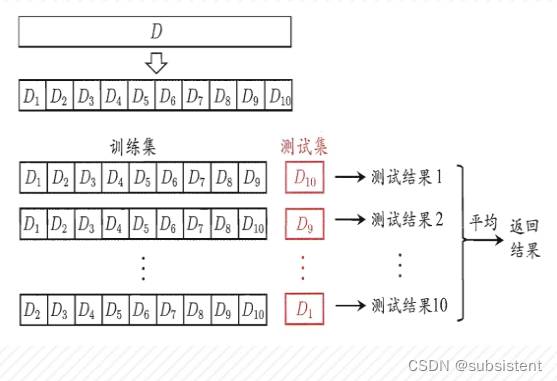
5折交叉验证:将拿到的数据,分为训练和验证集。以下图7-5为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。
(2)超参数搜索-网格搜索
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。
(3)超参数搜索-API
sklearn.model_selection.GridSearchCV(estimator,param_grid=None,cv=None)
estimator:估计器对象
param_grid: 估计器参数(dict或list){“n_neighbors”:[1,3,5]}
cv:指定几折交叉验证
score:准确率
结果分析:best_estimator_:最好的参数模型
best_score_:在交叉验证中测试的最好结果
best_params_: 最好结果的参数设置
cv_results_:每次交叉验证后的测试集准确率结果和训练集准确率结果
K-近邻网格搜索案例
"""
K-近邻算法,网格搜索交叉验证的使用
威斯康星州乳腺癌数据集
含有30个特征、569条记录、目标值为0或1
"""
# 0.导包
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import GridSearchCV
# 1.导入数据
data_cancer = load_breast_cancer()
# 2.将数据集划分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(data_cancer.data, data_cancer.target, test_size=0.25)
# print(x_train)
# 3.数据标准化处理
stdScaler = StandardScaler().fit(x_train)
x_trainStd = stdScaler.transform(x_train)
x_testStd = stdScaler.transform(x_test)
# 4.使用KNeighborsClassifier函数构建
knn模型knn_model = KNeighborsClassifier()
param_grid = {"n_neighbors": [1, 3, 5, 7]}
grid_search = GridSearchCV(knn_model, param_grid=param_grid, cv=5).fit(x_trainStd, y_train)
print("网格搜索中最佳结果的参数设置:", grid_search.best_params_)
print("网格搜索中最高分数估计器的分数为:", grid_search.best_score_)分类是一种常见的机器学习问题。本章首先讨论分类的基本概念、机器学习中常见的数据集,然后对KNN算法、概率模型、朴素贝叶斯分类、空间向量模型、支持向量机以及集成学习算法和应用等进行介绍。
分类问题是最为常见的监督学习问题,遵循监督学习问题的基本架构和流程。一般地,分类问题的基本流程可以分为训练和预测两个阶段:
1.训练阶段。先需要准备训练数据(文本、图像、音频、视频等),然后抽取所需要的特征,形成特征数据;最后将这些特征数据连同对应的类别标记一起送入分类学习算法中,训练得到一个预测模型。
2.预测阶段。先将与训练阶段相同的特征抽取方法作用于测试数据,得到对应的特征数据;其次,使用预测模型对测试数据的特征数据进行预测;最后得到测试数据的类别标记。
监督学习可分为
分类
回归
一个关于分类学习的例子
我们来看一个问题
当我们获得一些关于肿瘤的医疗数据,我们怎么让机器判断肿瘤是良性的还是恶性的呢?

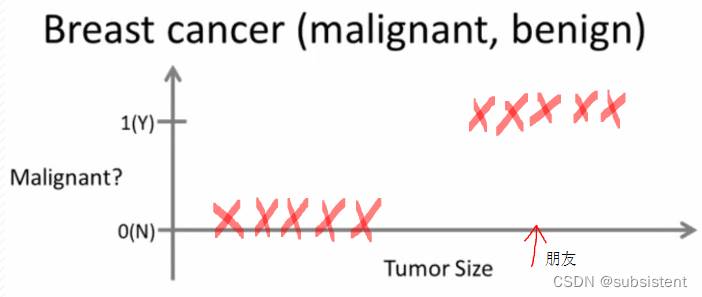
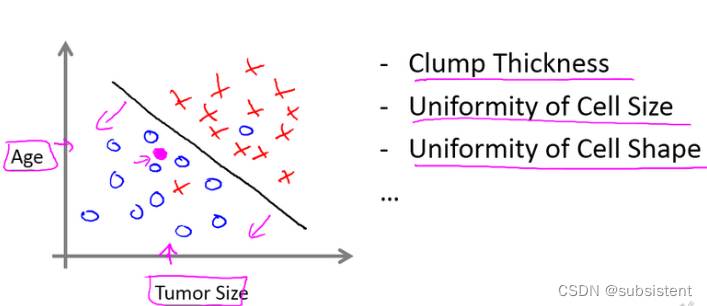
例子实现了什么?
指我们给算法一个数据集,并且给定正确答案
在分类学习中,数据集中的每个数据,算法都知道数据的“正确答案”
算法将算出更多新的结果如瘤是恶性的还是良性的
分类方法的定义
分类分析的是根据已知类别的训练集数据,建立分类模型,并利用该分类模型预测未知类别数据对象所属的类别。
分类方法的应用
模式识别(Pattern Recognition),就是通过计算机用数学技术方法来研究模式的自动处理和判读
预测,从利用历史数据记录中自动推导出对给定数据的推广描述,从而能对未来数据进行类预测
分类器
分类的实现方法是创建一个分类器(分类函数或模型),该分类器能把待分类的数据映射到给定的类别中。
创建分类的过程与机器学习的一般过程一致
分类器的构建图示
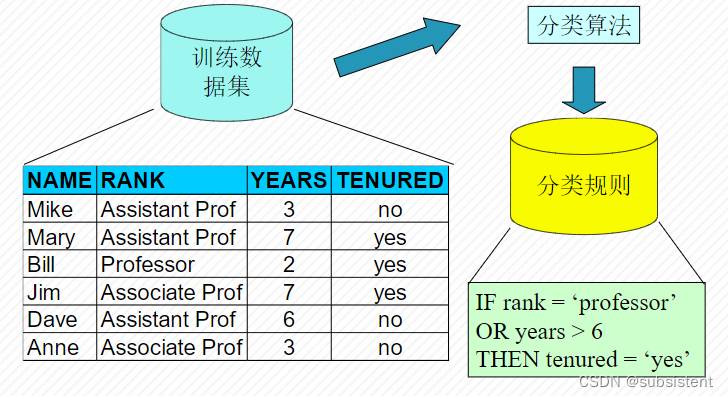
分类器的构建标准
使用下列标准比较分类和预测方法
预测的准确率:模型正确预测新数据的类编号的能力
速度:产生和使用模型的计算花销
健壮性:给定噪声数据或有空缺值的数据,模型正确预测的能力
可伸缩性:对大量数据,有效的构建模型的能力
可解释性:学习模型提供的理解和洞察的层次
鸢尾花数据集:load_iris()
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’sIrisdataset。iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,iris数据集是一个150行5列的二维表。
通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。
iris的每个样本都包含了品种信息,即目标属性(第5列,也叫target或label)。即iris数据集每行包括4个输入变量和1个输出变量。变量名如下:
萼片长度(cm);
萼片宽度(cm);
花瓣长度(cm);
花瓣宽度(cm);
类(IrisSetosa,IrisVersicolour,IrisVirginica)。
python的机器学习库scikit已经内置了iris数据集,样本局部截图:
打开python集成开发环境,输入以下代码:
fromsklearnimportdatasets
iris=datasets.load_iris()
#data对应了样本的4个特征,150行4列
print(iris.data.shape)
#显示样本特征的前5行
print(iris.data[:5])
#target对应了样本的类别(目标属性),150行1列print(iris.target.shape)
#显示所有样本的目标属性
print(iris.target)其运行结果如下所示:

其中,iris.target用0、1和2三个整数分别代表了花的三个品种。
手写数字数据集包括1797个0-9的手写数字数据,每个数字由8*8大小的矩阵构成,矩阵中值的范围是0-16,代表颜色的深度。使用sklearn.datasets.load_digits即可加载相关数据集。其中,参数:
*return_X_y:若为True,则以(data,target)形式返回数据;默认为False,表示以字典形式返回数据全部信息(包括data和target)。
*n_class:表示返回数据的类别数,如:n_class=5,则返回0到4的数据样本。
加载数据:
from sklearn.datasets import load_digits
digits=load_digits()
print(digits.data.shape)
print(digits.target.shape)
print(digits.images.shape)其输出结果如下所示:
(1797, 64)
(1797,)
(1797, 8, 8)
MNIST手写体数据集
MNIST数据集是一个手写体数据集,这个数据集由四部分组成,分别是一个训练图片集,一个训练标签集,一个测试图片集,一个测试标签集;这个数据集不是普通的文本文件或是图片文件,而是一个包含60000张手写体识别数字图片的压缩文件:
训练样本:共60000个;
其中55000个用于训练,另外5000个用于验证(评估训练过程中的准确度);
测试样本:共10000个(评估最终模型的准确度);
所有数字图像已经进行尺寸归一化、数字居中处理,固定尺寸为28×28像素。
乳腺癌数据集
scikit-learn内置的乳腺癌数据集来自加州大学欧文分校机器学习仓库中的威斯康辛州乳腺癌数据集。
乳腺癌数据集是一个共有569个样本、30个输入变量和2个分类的数据集。
乳腺癌数据集的相关统计:
数据集样本实例数:569个;
特征(属性)个 数 :30个 特 征 属 性 和2个 分 类 目 标(恶性-Malignant,良性-Benign);
特征(属性)信息:30个数值型测量结果由数字化细胞核的10个不同特征的均值、标准差和最差值(即最大值)构成。
这些特征包括:
radius(半径):meanofdistancesfromcentertopointsontheperimeter;
texture(质地):standarddeviationofgray-scalevalues;
perimeter(周长);
area(面积);
smoothness(光滑度):localvariationinradiuslengths;
compactness(致密性):perimeter^2/area-1.0;
concavity(凹度):severityofconcaveportionsofthecontour;
concavepoints(凹点);
symmetry(对称性);
fractaldimension(分形维数):"coastlineapproximation"–1。
目标分类分布:212-恶性(Malignant),357-良性(Benign);
数据集的创建者:Dr.WilliamH.Wolberg,W.NickStreet,OlviL.Mangasarian;
数据集的创建时间:1995年11月;
乳腺癌数据集的使用:使用sklearn.datasets包下的load_breast_cancer函数即可加载相关数据:from sklearn.datasets import load_breast_cancer
#加载sklearn自带的乳腺癌数据集
dataset=load_breast_cancer()
#提取特征数据和目标数据,都是numpy.ndarray类型
x=dataset.data
y=dataset.target
print(x)
print(y)
其输出结果如下所示:
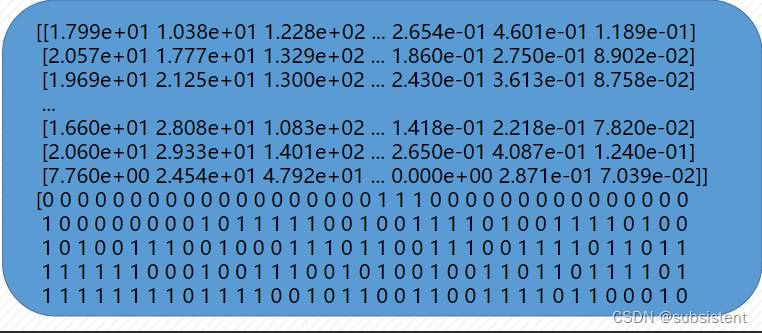
KNN分类器算法
K近邻(K Nearest Neighbors,KNN)算法,又称为KNN算法
思想是寻找与待分类的样本在特征空间中距离最近的K个已标记样本(即K个近邻),以这些样本的标记为参考,通过投票等方式,将占比例最高的类别标记赋给待标记样本
KNN分类器
K面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?
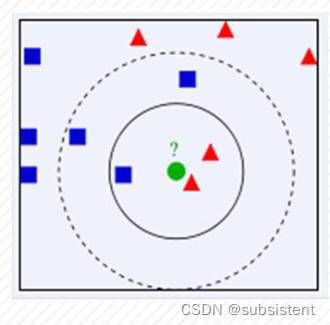
如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那类
如果K=5,蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类
KNN分类器算法
KNN算法需要确定K值、距离度量和分类决策规则
K值过小时,只有少量的训练样本对预测起作用,容易发生过拟合,或者受含噪声训练数据的干扰导致错误
K值过大,过多的训练样本对预测起作用,当不同类别样本数量不均衡时,结果偏向数量占优的样本
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
分类、回归、聚类不同的评判指标。
分类算法中,常用的性能指标有:
1.准确率( accuracy)
2.AUC(Area Under Curve)
回归分析中,常用的性能指标有:
1.均方误差(mean_squared_error)
2.可析方差得分(explained_variance_score)
交叉验证(Cross validation):
KNN案例
加载数据
from sklearnimport datasets
iris = datasets.load_iris()导入模型
>>>from sklearn.neighborsimport KNeighborsClassifier
>>> knn= KNeighborsClassifier()
sklearn库的框架
train_x, train_y, test_x, test_y= getData()
model1 = somemodel()
model.fit(train_x,train_y)
predictions = model.predict(test_x)
score =score_function(test_y, predictions)
joblib.dump(knn, 'filename.pkl')基于以上对KNN算法的介绍,本小节带领大家使用Python实现KNN,代码如下:
#导入所需要的包
import numpy as np
from math import sqrt
from collections import Counter
def distance(k, X_train, Y_train, x):
#保证K有效
assert 1 <= k <= X_train.shape[0], "K must be valid"
#X_train的值必须等于y_train的值
assert X_train.shape[0] == Y_train.shape[0], "the size of X_trainmust equal to the size of y_train"
#x的特征号必须等于X_train
assert X_train.shape[1] == x.shape[0], "the feature number of x must be equal to X_train"
#迅速计算距离
distance = [sqrt(np.sum((x_train-x)**2)) for x_trainin X_train]
#返回距离值从小到大排序后的索引值的数组
nearest = np.argsort(distance)
#获取距离最小的前k个样本的标签
topk_y= [Y_train[i] for iin nearest[:k]]
#统计前k个样本的标签类别以及对应的频数
votes = Counter(topk_y)
#返回频数最多的类别
return votes.most_common(1)[0][0]
if __name__ == "__main__":
#使用numpy生成8个点
X_train= np.array([[1.0, 3.5],[2.0, 7],[3.0, 10.5],[4.0, 14],[5, 25],[6, 30],[7, 35],[8, 40]])
#使用numpy生成8个点对应的类别
Y_train= np.array([0, 0, 0, 0, 1, 1, 1, 1])
#使用numpy生成待分类样本点
x = np.array([8, 21])
#调用distance函数并传入参数
label = distance(3, X_train, Y_train, x)
#显示待测样本点的分类结果
print(label)以上python代码实现了KNN算法,其最终的运行结果如下所示:
1
由此可以得出结论:待测样本点[8, 21]的类别标签为1。
几个重要的公式
概率论中的几个重要公式。
条件概率公式: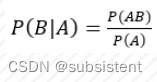
全概率公式: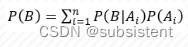
贝叶斯公式:
应用场景
概率模型通过比较提供的数据属于每个类型的条件概率, 将它们分别计算出来,然后预测具有最大条件概率的那个类别是最后的类别。当样本越多,统计的不同类型的特征值分布就越准确,使用此分布进行预测也会更加准确。
贝叶斯分类方法是一种具有最小错误率的概率分类方法,可用于分类和预测。
概率模型与是自然语言处理中统计学派的常用模型。
贝叶斯简介
贝叶斯(约1701-1761),英国数学家
贝叶斯方法源于他生前解决逆概的一篇文章
贝叶斯要解决的问题
使正向概率:假设袋子里有N个白球,M个黑球,随机摸一个,摸出黑球的概率有多大
逆向概率:如果事先不知道袋子里黑白球的比例,随机摸出几个球,根据这些球的颜色,可以推测袋子里面的黑白球比例
一个例子
男生总是穿长裤,女生则一半穿长裤一半穿裙子
正向概率:随机选取一个学生,穿长裤的概率和穿裙子的概率是多大
逆向概率:迎面走来一个穿长裤的学生,无法确定该学生的性别,请问该学生是女生的概率有多大
假设学校里面人的总数是U
穿长裤的男生:U*P(Boy)*P(Pants|Boy)
P(Boy)是男生的概率= 60%
P(Pants|Boy)是条件概率,即在Boy的条件下,穿长裤的概率是多大,这里是100%
穿长裤的女生:U*P(Girl)*P(Pants|Girl)
求解:穿长裤的总数:U*P(Boy)*P(Pants|Boy)+U*P(Girl)*P(Pants|Girl)
穿长裤的人为女生的概率:
P(Girl|Pants)
=U*P(Girl)*P(Pants|Girl)/穿长裤的总数=U*P(Girl)*P(Pants|Girl)/[U*P(Boy)*P(Pants|Boy)+U*P(Girl)*P(Pants|Girl)]
与总人数有关吗?
分子分母均包含总人数,结果与总人数无关,可以消去
P(Girl|Pants)=P(Girl)*P(Pants|Girl)/[P(Boy)*P(Pants|Boy)+P(Girl)*P(Pants|Girl)]=P(Girl)*P(Pants|Girl)/ P(Pants)
分母就是P(Pants)贝叶斯算法
贝叶斯公式

朴素贝叶斯分类器
我们介绍的第一个分类学习方法是朴素贝叶斯(Naive Bayes)模型, 它是一种基于概率的学习方法
“朴素”指的是条件的独立性
我们一起通过一个例子来了解一下朴素贝叶斯分类算法
朴素贝叶斯案例
现在给我们的问题是,如果一对男女朋友,男生想女生求婚,男生的四个特点分别是不帅,性格不好,身高矮,不上进,请你判断一下女生是嫁还是不嫁?
这是一个典型的分类问题
数学问题就是比较p(嫁|(不帅、性格不好、身高矮、不上进))与p(不嫁|(不帅、性格不好、身高矮、不上进))
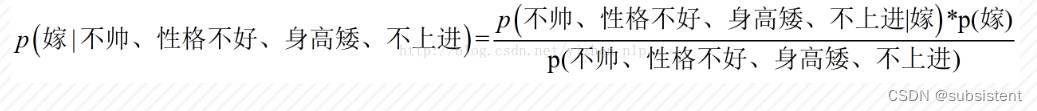
其中p(不帅、性格不好、身高矮、不上进|嫁) = p(不帅|嫁)*p(性格不好|嫁)*p(身高矮|嫁)*p(不上进|嫁)
那么我就要分别统计后面几个概率,也就得到了左边的概率!
我们将上面公式整理一下如下:

下面我将一个一个的进行统计计算(在数据量很大的时候,中心极限定理,频率是等于概率的)
p(嫁)=?
首先我们整理训练数据中,嫁的样本数如下:则p(嫁) = 6/12(总样本数)= 1/2
则p(嫁) = 6/12(总样本数)= 1/2
p(不帅|嫁)=?
求出其他统计量的概论代入

思考刚才的案例,我们做了哪些事情
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集
2、统计得到在各类别下各个特征属性的条件概率估计,即只计算P(a1|y1),P(a2|y1)......的概率
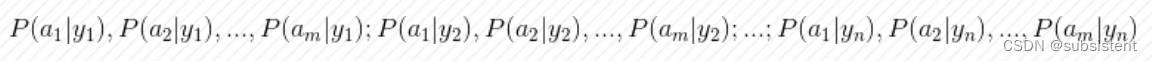
3、假设各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
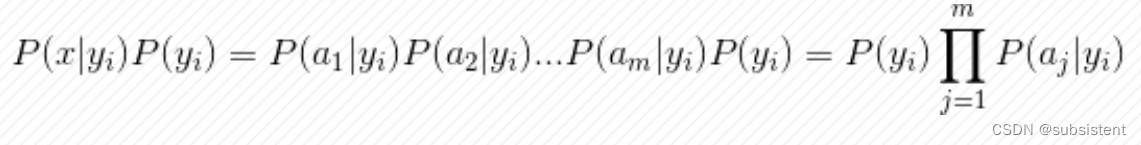 朴素贝叶斯分类算法
朴素贝叶斯分类算法
1、设x={a1,a2,a3,......am}为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合C={y1,y2,......yn}。
3、计算P(y1|x),P(y2|x),......,P(yn|x),。
4、如果,P(yk|x)=max{P(y1|x),P(y2|x),......,P(yn|x)},则x属于yk
讨论P(a|y)的估计
朴素贝叶斯分类的关键:计算条件概率P(a|y),当特征属性为离散值时,使用频率即可用来估计P(a|y)
下面重点讨论特征属性是连续值的情况。
当特征属性为连续值时,通常假定其值服从高斯分布(也称正态分布)。即:
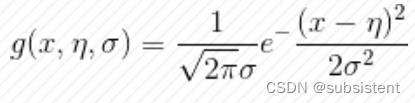
而
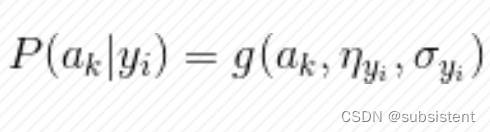
讨论P(a|y)=0的估计
另一个需要讨论的问题就是当P(a|y)=0怎么办?
当某个类别下某个特征项划分没有出现时,就是产生这种现象,这会令分类器质量大大降低
为了解决这个问题,我们引入Laplace校准
高斯和多项式朴素贝叶斯
数据集类型的不同,数据的分布也不同
什么样的数据适合使用高斯?什么样的数据适合使用多项式贝叶斯?
了解多项式分布和高斯分布
朴素贝叶斯案例
加载数据
from sklearnimport datasets
iris = datasets.load_iris()
导入模型
>>> from sklearn.naive_bayesimport GaussianNB
>>> gnb= GaussianNB()
训练模型+预测数据
y_pred= gnb.fit(iris.data, iris.target).predict(iris.data)
输出
print("Number of mislabeled points out of a total %d points : %d"% (iris.data.shape[0],(iris.target!= y_pred).sum()))
空间中具有大小和方向的量叫做空间向量
我们可以想象我们所分析的数据的每一个属性视为一个向量维度,我们输入的数据其实是某个高维向量空间中的一个点
很多基于向量空间的分类器在分类决策时用到距离的概念。
空间距离计算方法:欧氏距离(Euclidean distance)
在二维和三维空间中的欧式距离的就是两点之间的距离,二维的公式是
d = sqrt((x1-x2)^2+(y1-y2)^2)
三维的公式是
d=sqrt(x1-x2)^2+(y1-y2)^2+(z1-z2)^2)
推广到n维空间
向量空间模型进行分类
空间向量如何进行分类?
在向量空间的分类中,我们必须要做的工作是定义类别之间的边界,从而得到分类的结果
向量空间模型应用
经典的向量空间模型由Salton等人于60年代提出,并成功地应用于著名的SMART文本检索系统。
Gensim库的基本使用
支持向量机概述
关于支持向量机,读者可以先了解如下内容:
线性可分
最大间隔超平面与支持向量
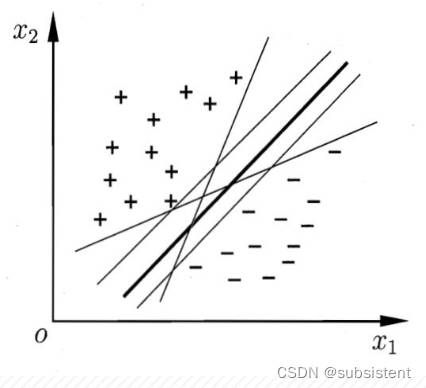
支持向量机的优势如下:
(1)在高维空间中非常高效。
(2)即使在数据维度比样本数量大的情况下仍然有效。
(3)在决策函数(称为支持向量)中使用训练集的子集,因此它也是高效利用内存的。
支持向量机的缺点如下:
(1)如果特征数量比样本数量大得多,在选择核函数核函数时要避免过拟合。
(2)而且正则化项是非常重要的。
(3)支持向量机不直接提供概率估计,这些都是使用昂贵的五次交叉验算计算的。
支持向量机实现分类
>>> from sklearnimport svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf= svm.SVC()
>>> clf.fit(X, y)
>>> clf.predict([[2., 2.]])
支持向量机实现分类-获得支持向量
获得支持向量
>>> clf.support_vectors_
array([[ 0., 0.], [ 1., 1.]])
获得支持向量的索引
get indices of support vectors
>>> clf.support_
array([0, 1]...)
为每一个类别获得支持向量的数量
>>> clf.n_support_
array([1, 1]...)
支持向量机实现回归
>>> from sklearnimport svm
>>> X = [[0, 0], [2, 2]]
>>> y = [0.5, 2.5]
>>> clf= svm.SVR()
>>> clf.fit(X, y)
>>> clf.predict([[1, 1]])
array([ 1.5])
支持向量机异常检测
支持向量机也可用于异常值的检测,即给定一个样例集,生成这个样例集的支持边界。因而,对一个新的数据点时,可以通过支持边界来检测它是否属于这个样例集。
异常检测属于非监督学习,没有类标签
过拟合问题
训练中,我们希望模型在新样本上也能表现的很好。为了达到这个目的,应该从训练样本中尽可能学出适用于所有潜在样本的“普遍规律",这样才能在遇到新样本时做出正确的判别。然而,当学习器把训练样本学得“太好”的时候,可能已经把训练样本自身的一些特点当作所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降。这种现象在机器学习中称为“过拟合”(Overfitting)。
过拟合问题-原因
过拟合问题产生的原因如下:
(1) 使用的模型比较复杂,学习能力过强。
(2) 有噪声存在。
(3) 数据量有限。
过拟合问题-解决方法
解决过拟合办法有以下3种:
(1)提前终止(当验证集上的效果变差的时候)。
(2)数据集扩增(Data augmentation)。
(3)寻找最优参数。
过拟合问题-最优参数寻找
学习曲线
验证曲线
集成学习
定义:本身并不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务,以达到获得比单个学习器更好的学习效果的一种机器学习方法。高端点的说叫“博彩众长”,庸俗的说叫“三个臭皮匠,顶个诸葛亮”。
思路:在对新的实例进行分类的时候,把若干个单个分类器集成起来,通过对多个分类器的分类结果进行某种组合来决定最终的分类,以取得比单个分类器更好的性能。如果把单个分类器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决策。
原理:生成一组个体学习器,然后采用某种策略将他们结合起来。个体学习器可以由不同的学习算法生成,之间也可以按照不同的规律生成。
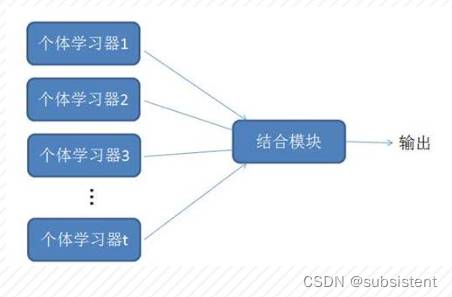
集成学习的方法
目前应用较多的集成学习主要有2种:基于Boosting的和基于Bagging,前者的代表算法有Adaboost(提升树)、GBDT(梯度下降树),后者的代表算法主要是随机森林。
Boosting是个体学习器之间存在着强依赖关系,必须串行生成的序列化方法;Bagging是个体学习器之间没有强依赖关系,可同时并行生成。
Boosting之原理
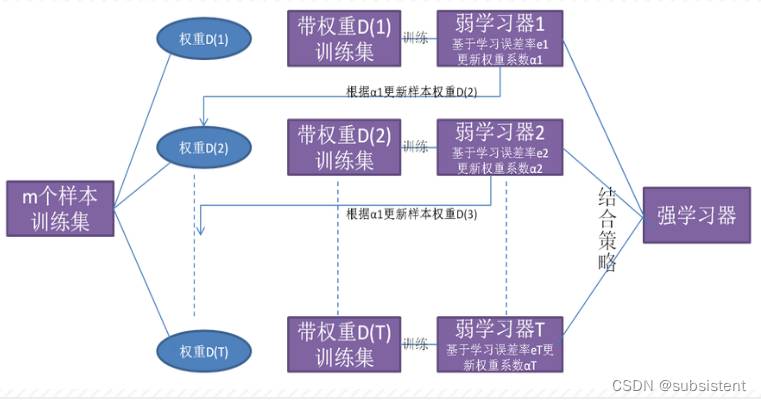
从图中可以看出,首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
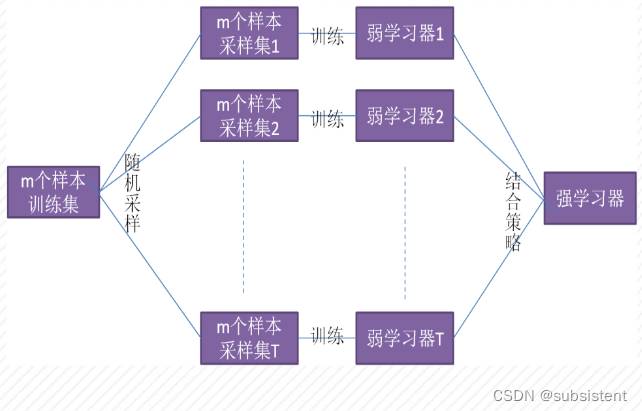
个体弱学习器的训练集是通过随机采样得到的。通过T次的随机采样,我们就可以得到T个采样集,对于这T个采样集,我们可以分别独立的训练出T个弱学习器,再对这T个弱学习器通过集合策略来得到最终的强学习器。
Boosting和Bagging的区别
1、样本选择:前者每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。后者训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
2、样例权重:前者根据错误率不断调整样例的权值,错误率越大则权重越大;后者使用均匀取样,每个样例的权重相等。
3、预测函数:前者每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。后者所有预测函数的权重相等。
4、并行计算:前者各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果;后者各个预测函数可以并行生成
树形结构都比较熟悉,由节点和边两种元素组成的结构。决策树(Decision Tree)利用树结构进行决策,每一个非叶节点是一个判断条件,每一个叶子节点是结论,从跟节点开始,经过多次判断得出结论。
决策树案例
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。
相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。
假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员
决策树模型构造
所谓决策树的构造就是进行属性选择度量,确定各个特征属性之间的拓扑结构。关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。
决策树的分裂属性
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
ID3算法
从信息论知识中我们知道,期望信息越小,信息增益越大,从而纯度越高。ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
引入熵的概念:熵是表示随机变量不确定性的度量,白话称为物体内部的混乱程度。
一个例子:A集合[1,1,1,2,2] B集合[1,2,3,4,5]
显然A集合的熵值要低,因为只有两种类别,相对稳定一些;而B集合的类别太多,熵值就会大很多。
设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
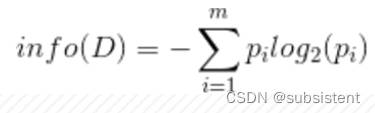
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。
熵的实际意义表示是D中元组的类标号所需要的平均信息量。现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:

ID3算法信息的增益
信息增益即为两者的差值
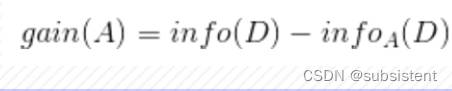
ID3算法就是在每次需要分裂时,计算每个属性的增益,然后选择增益最大的属性进行分裂
ID3算法案例
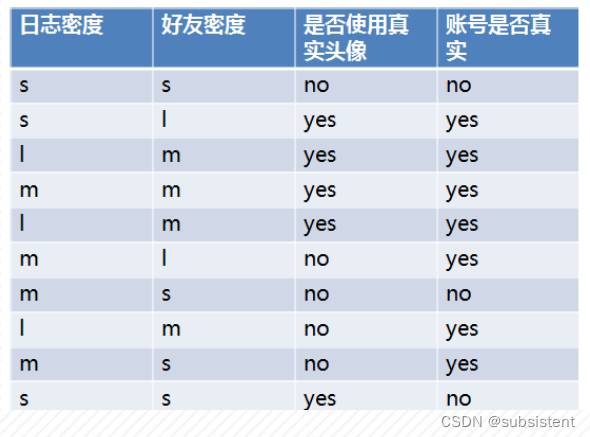
其中s、m和l分别表示小、中和大
设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。

在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。
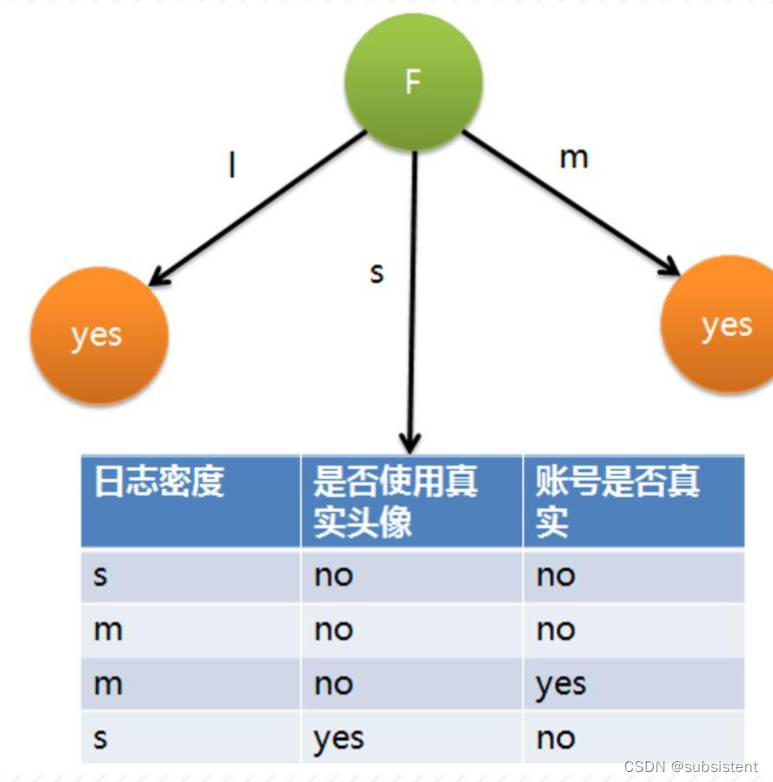
决策树的调用过程
>>>from sklearn.datasets import load_iris
>>> from sklearn import tree
#加载数据
>>> iris = load_iris()
#训练数据
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(iris.data, iris.target)
随机森林
机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定,这意味着通过在分类器构造中引入随机性来创建一组不同的分类器。
随机森林举例
通过例子来理解随机森林:
有一个决策公司(集成学习器),公司里有许多的预测大师(个体学习器),我们现在要找这个决策公司对某堆(测试集)西瓜的好坏做预测(分类)或者定量预测西瓜的甜度(回归)。当然我们首先需要拿一堆西瓜N个(测试集)给这些预测大师。每个西瓜有M个属性(比如颜色、纹路、尾巴等)。
每次从N个西瓜中随机选择几个西瓜(子集),对某个预测大师进行训练,预测大师学习西瓜的各种M个属性与结果的关系,比如先判断颜色如何?再判断纹路如何?再判断尾巴如何?预测大师开始预测然后自我调节学习,最后成为研究西瓜的人才。所有的预测大师都采用这种训练方式,都学成归来。测试的时候,每拿出一个西瓜,所有专家一致投票,我们把最高投票的结果作为最终结果。
随机森林的生成算法
1.从样本集中通过重采样的方式产生n个样本
2.假设样本特征数目为a,对n个样本选择a中的k个特征,用建立决策树的方式获得最佳分割点
3.重复m次,产生m棵决策树
4.多数投票机制来进行预测(需要注意的一点是,这里m是指循环的次数,n是指样本的数目,n个样本构成训练的样本集,而m次循环中又会产生m个这样的样本集)
随机森林的算法图示
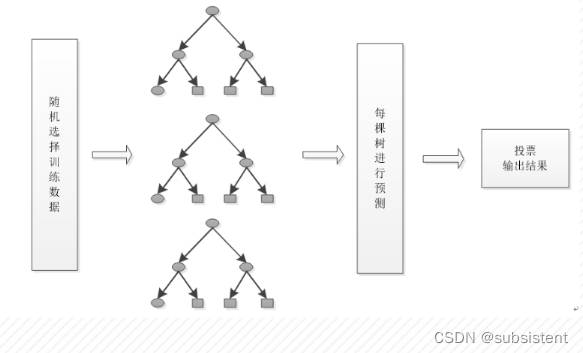
随机森林算法的代码
>>> from sklearn.ensemble import RandomForestClassifier
>>> X = [[0, 0], [1, 1]]
>>> Y = [0, 1]
>>> clf = RandomForestClassifier(n_estimators=10)
>>> clf = clf.fit(X, Y)
随机森林的随机性
集合中的每一棵树都是从训练集替换出来的样本中构建的。在树构建期间分割节点时,所选择的分割不再是所有特征之间最好的分割。相反,被选中的分割是特征的随机子集之间最好的分割。由于随机性,森林的偏向通常略有增加。但是,由于平均值,它的方差也减小,从而产生一个整体更好的模型
随机森林优势
随机森林算法几乎不需要输入的准备。它们不需要测算就能够处理二分特征、分类特征、数值特征的数据。随机森林算法能完成隐含特征的选择,并且提供一个很好的特征重要度的选择指标。
随机森林算法训练速度快。性能优化过程刚好又提高了模型的准确性
通用性。随机森林可以应用于很多类别的模型任务。它们可以很好的处理回归问题,也能对分类问题应付自如(甚至可以产生合适的标准概率值),它们还可以用于聚类分析问题。
简洁性。对于随机森林来说,算法本身很简洁。基本的随机森林学习算法仅用几行代码就可以写出来了。
Adaboost算法
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。
每个连续的迭代,样本权重分别修改和学习算法重新的加权数据。在给定的步骤中,在前一步引起的增强模型错误地预测了那些训练实例,它们的权重增加,而正确预测的权重则降低。随着迭代的进行,难以预测的例子受到越来越多的影响。因此,每一个后继的弱学习者都必须集中精力于前面的序列中遗漏的例子。
Adaboost算法步骤
主要步骤:
i)重复地从一个样本集合D中采样n个样本
ii)针对每次采样的子样本集,进行统计学习,获得假设Hi
iii)将若干个假设进行组合,形成最终的假设Hfinal
iv)将最终的假设用于具体的分类任务
Adaboost算法构建过程
给定训练数据集:{(x1,y1),...(xn,yn)},yi表示类别标签
相关符号的定义:
Dt(i):训练样本集的权值分布;
Wi:每个训练样本的权值大小;
h:弱分类器;H:基本分类器;
Hfinal:最终的强分类器;
e:误差率。
首先,初始化训练数据的权值分布,每一个训练样本最开始时被赋予相同的权值:wi=1/N,这样训练样本集的初始权值分布
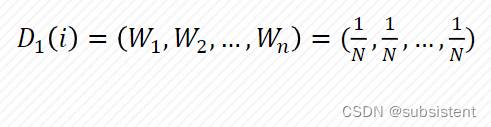
其次,进行迭代t=1,...,T
(a)每次迭代中选取一个当前误差率最低的弱分类器h作为第t个基本分类器Ht,并更新误差:
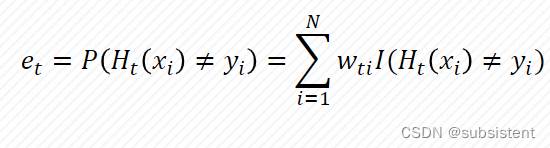
(b)计算该弱分类器在最终分类器中所占的权重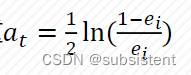
(c)更新训练样本的权值分布,正确样本: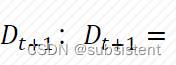
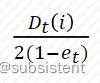 ,
,
错误样本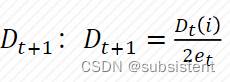 ,其中et为误差率
,其中et为误差率
最后,按弱分类器权值at组合各个弱分类器:
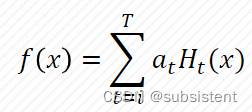
通过符号函数sign的作用,得到一个强分类器为:
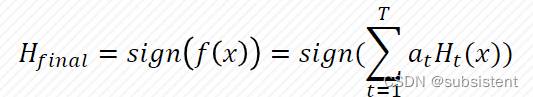
Adaboost优点
Adaboost提供一种框架,在框架内可以使用各种方法构建子分类器。可以使用简单的弱分类器,不用对特征进行筛选,也不存在过拟合的现象。
Adaboost算法不需要弱分类器的先验知识,最后得到的强分类器的分类精度依赖于所有弱分类器。无论是应用于人造数据还是真实数据,Adaboost都能显著的提高学习精度。
Adaboost算法不需要预先知道弱分类器的错误率上限,且最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度,可以深挖分类器的能力。Adaboost可以根据弱分类器的反馈,自适应地调整假定的错误率,执行的效率高。
Adaboost对同一个训练样本集训练不同的弱分类器,按照一定的方法把这些弱分类器集合起来,构造一个分类能力很强的强分类器。
Adaboost缺点
在Adaboost训练过程中,Adaboost会使得难于分类样本的权值呈指数增长,训练将会过于偏向这类困难的样本,导致Adaboost算法易受噪声干扰。此外,Adaboost依赖于弱分类器,而弱分类器的训练时间往往很长。
Adaboost实现
>>>from sklearn.model_selectionimport cross_val_score
>>> from sklearn.datasetsimport load_iris
>>> from sklearn.ensembleimport AdaBoostClassifier
>>> iris = load_iris()
>>> clf= AdaBoostClassifier(n_estimators=100)
>>> scores = cross_val_score(clf, iris.data, iris.target, cv=5)
>>> scores.mean()
关联规则是机器学习经典的算法之一。本章首先讨论关联规则的基本概念,然后介绍现实中如何通过关联规则挖掘出数据背后的有用信息。然后讲解典型关联规则算法——Apriori算法的原理和应用。
推荐算法目的
帮助用户找到想要的商品(新闻/音乐/......
降低信息过载
推荐算法
推荐算法是什么?

如何进行推荐?
关联规则
协同过滤
关联规则挖掘
关联规则挖掘:一种发现大量数据中事物(特征)之间有趣的关联的技术。
典型应用是购物篮分析:找出顾客购买行为模式、发现交易数据库中不同商品(项)之间的联系
关联规则挖掘的应用:
互联网
零售
交通事故成因
生物医学
啤酒尿布案例
关联规则挖掘例子
TID Items
T1 {牛奶,面包}
T2 {面包,尿布,啤酒,鸡蛋}
T3 {牛奶,尿布,啤酒,可乐}
T4 {面包,牛奶,尿布,啤酒}
T5 {面包,牛奶,尿布,可乐}
总项集I={牛奶,面包,尿布,啤酒,鸡蛋,可乐}。
{啤酒}->{尿布} 是一条表征购买了啤酒也会购买尿布的关联规则。
关联规则定义
假设I = {I1,I2,...Im}是项的集合。给定一个事务数据库D,其中每个事务(Transaction) t是I的非空子集
关联规则:不相交的非空项集X、Y,蕴含式X–>Y,X–>Y是一条关联规则。其中X含于I,Y含于I,且X^Y=非空集合
关联规则的度量:支持度(support)
支持度的定义:support(X–>Y) = |X^Y|/N=集合X与集合Y中的项在一条记录中同时出现的次数/数据记录的个数。
例如:support({尿布}–>{啤酒}) = 啤酒和尿布同时出现的次数/数据记录数= 3/5=60%
关联规则的度量:置信度(confidence)来描述
置信度:confidence(X–>Y) = |X^Y|/|X| = 集合X与集合Y中的项在一条记录中同时出现的次数/集合X出现的个数。
confidence({尿布}–>{啤酒}) = 啤酒和尿布同时出现的次数/尿布出现的次数= 3/4 = 75%
关联规则的度量:
支持度和置信度越高,说明规则越强。关联规则挖掘就是要找出数据库中满足支持度support >= min_support、置信度confidence >= min_confidence的所有规则
关联规则挖掘的步骤
有一个简单而粗暴的方法
1. 列出所有规则
2. 计算这些规则的支持度和置信度
3. 留下满足支持度置信度阈值的关联规则
关联规则挖掘的定义与步骤
仔细想一下,我们发现对于{啤酒–>尿布},{尿布–>啤酒}这两个规则的支持度实际上只需要计算{尿布,啤酒}的支持度。
于是我们可以把关联规则挖掘拆解成按支持度和置信度两个要求分开计算。
关联规则挖掘的定义:给定一个交易数据集T,找出其中所有支持度support >= min_support、置信度confidence >= min_confidence的关联规则。
关联规则分为两步:
找出所有频繁项集
由频繁项集生成满足最小信任度阈值的规则
关联规则挖掘的步骤
1)找出所有频繁项集
这一阶段找出所有满足最小支持度的项集,找出的这些项集称为频繁项集。
2)由频繁项集生成满足最小信任度阈值的规则,在上一步产生的频繁项集的基础上生成满足最小自信度的规则,产生的规则称为强规则。
频繁项集挖掘
搜索空间依旧组合爆炸:
n个项数,2d个可能
apriori定律
为了减少频繁项集的搜索空间,应该尽早的消除一些完全不可能是频繁项集的集合
apriori定律,频繁项集的非空子集必为频繁项集。
apriori定律的性质
apriori定律性质1):如果一个集合是频繁项集,则它的所有非空子集都是频繁项集。
举例:假设一个集合{A,B}是频繁项集,即A、B同时出现在一条记录的次数大于等于最小支持度min_support,则它的子集{A},{B}出现次数必定大于等于min_support,即它的子集都是频繁项集。
apriori算法
apriori定律2):如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。
举例:假设集合{A}不是频繁项集,即A出现的次数小于min_support,则它的任何超集如{A,B}出现的次数必定小于min_support,因此其超集必定也不是频繁项集。
利用这两条定律,可以过滤掉很多的候选项集
利用性质1 通过已知的频繁项集构成长度更大的项集,并将其称为候选频繁项集。
利用性质2 过滤候选频繁项集中的非频繁项集
二项频繁集由在一项频繁集的基础上产生的,三项频繁项集由二项频繁项集的基础上产生的,以此类推。
apriori算法核心思想

apriori_gen连接步

连接步

apriori_gen剪枝步
判断项集是否非频繁

剪枝步
C3 =(牛奶,面包,尿布)
(牛奶,面包)(牛奶,尿布)(面包,尿布) 都出现在L2中
L3 = {(牛奶,面包,尿布) }
C4 ={abcd, acde}
acde被删除, 因为ade不在L3
L4={abcd}
apriori算法不足
可能产生大量的候选集,以及可能需要重复扫描数据库,是Apriori 算法的两大缺点。
主要改进方向:
减少候选集产生
降低无效的扫描库次数
提高候选集与原数据的比较效率
推荐模式评估
关联规则挖掘使用支持度-置信度框架
会产生大量冗余规则。
例如{A,B,C} →{D} 等同于{A,B} →{D}
强规则不代表有意义,甚至可能误导。
例如conf({怀孕->女性}) = 100%。
使用相邻矩阵进行推荐
用相邻矩阵计算一个规则X->Y的兴趣度。
相邻矩阵计算置信度
关联规则: Tea →Coffee
Confidence= P(Coffee|Tea) = 0.75
but P(Coffee) = 0.9
=> 虽然置信度很高, 但从购买影响看,规则误导了
=> P(Coffee|Tea) = 0.9375

统计独立性
1000 名学生
600 名会游泳(S)
700 名会骑车(B)
420 名同时会游泳和骑车(S^B)
P(S^B) = 420/1000 = 0.42
P(S) *P(B) = 0.6 *0.7 = 0.42
P(S^B) = P(S) *P(B) => 统计独立
P(S^B) > P(S) *P(B) => 正相关
P(S^B) < P(S) *P(B) => 负相关
能表现统计独立性的部分指标
相邻矩阵
关联规则: Tea →Coffee
x=coffee,y=tea时
p(x)=(75+15)/100
p(x|y)=15/20
关联规则: Tea →Coffee
Confidence= P(Coffee|Tea) = 0.75
but P(Coffee) = 0.9
=> Lift =0.75/0.9= 0.8333 (< 1, 负相关)
=> Interest = 0.15/(0.2*0.9) = 0.833 (< 1, 负相关)
兴趣度
非常多的兴趣度
用什么方式判断哪些指标比较好?

兴趣度的一些性质
P1:M(A,B) = 0 当A 和B 是统计独立的
P2:M(A,B) 随P(A,B) 增大,P(A) 和P(B)不变时候单调递增
O1:M(A,B) 变量交换不影响:即A->B 和B->A 值相同
O5:值与不包含A 或B 的记录无关
不同兴趣度的不同性质
根据需要选择合适的兴趣度度量规则
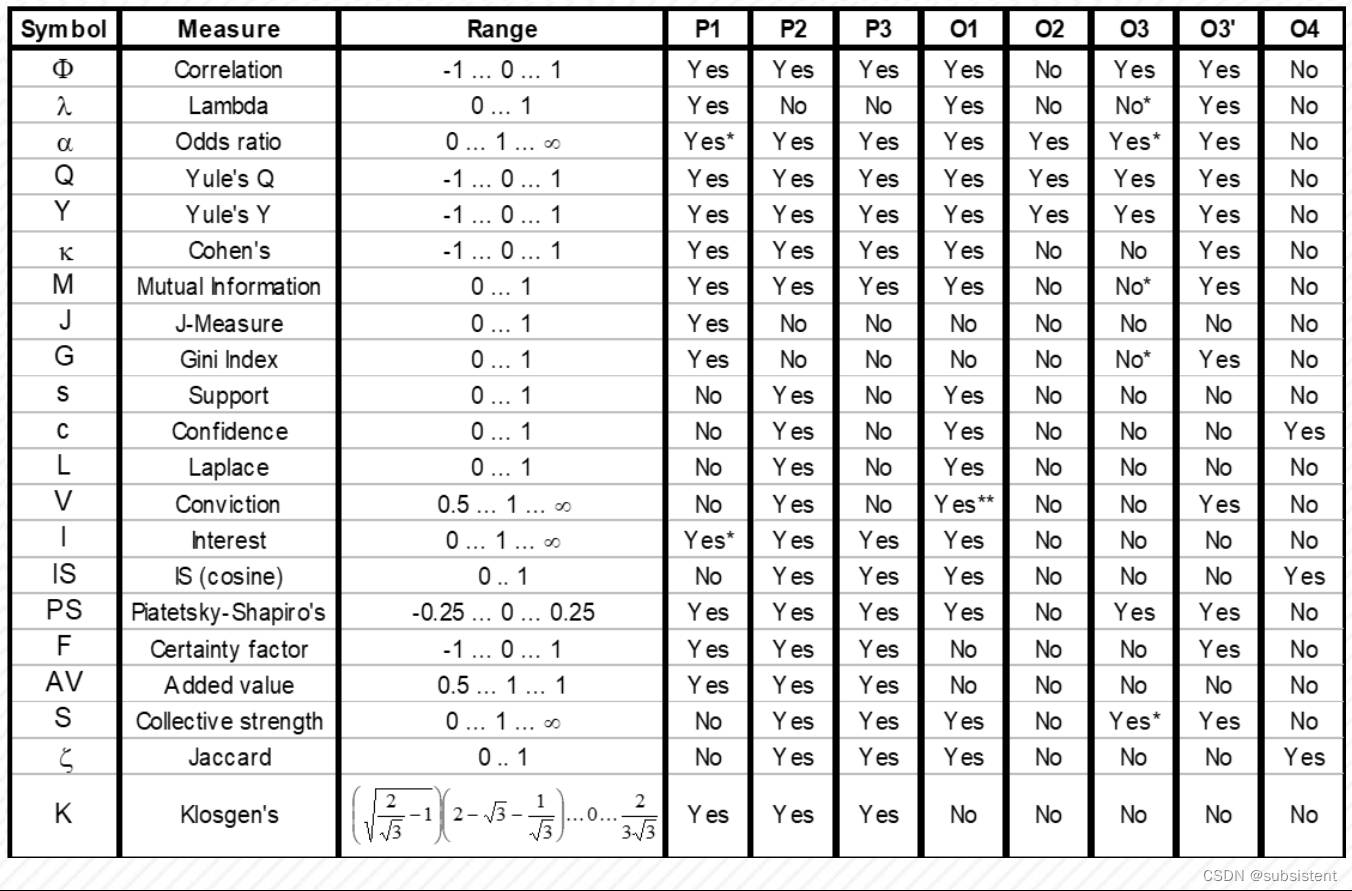
算法实现

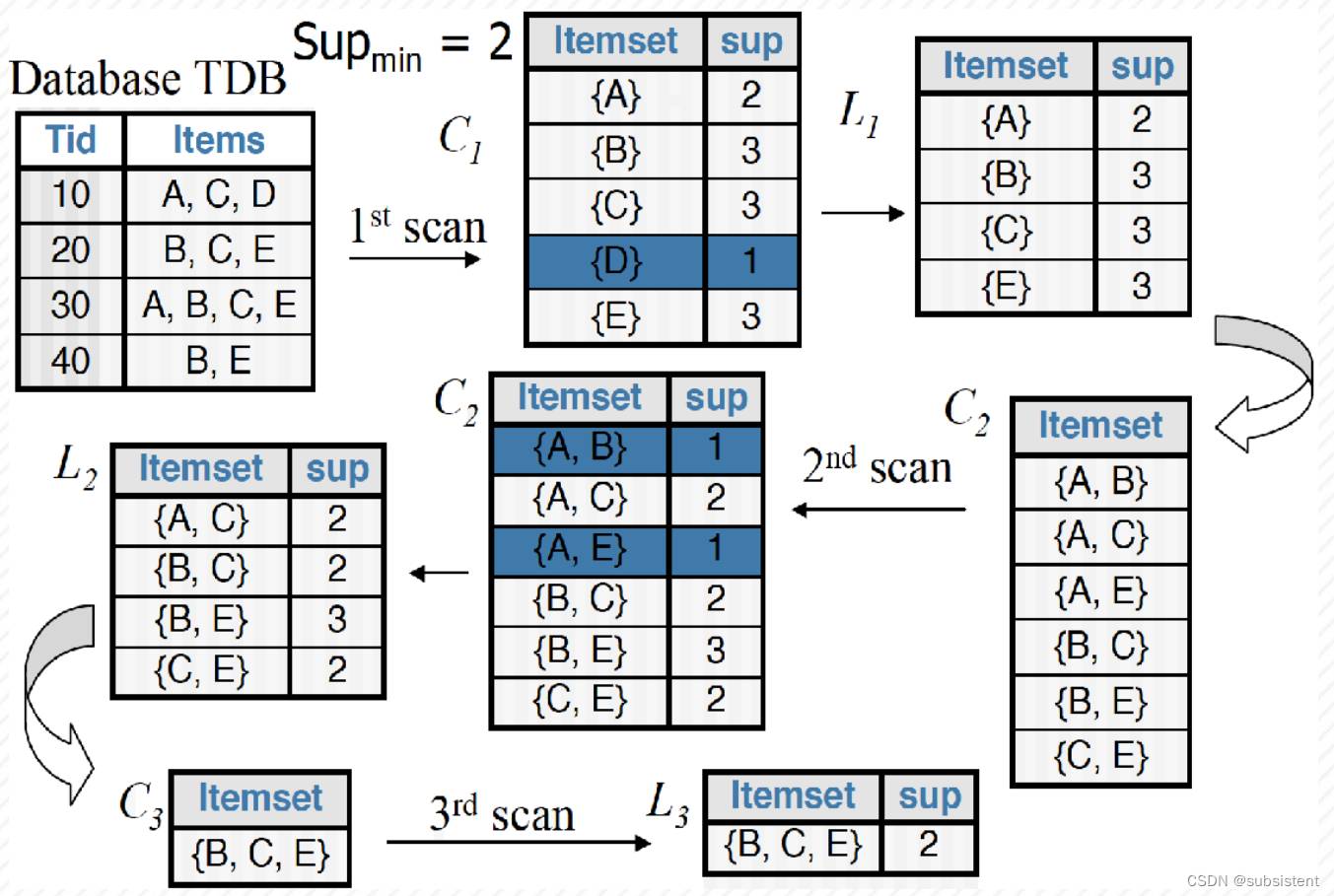
编程实现Apriori算法。
1.我们手动加载样本数据集。
def load_data_set():
data_set=[['l1','l2','l5'],['l2','l4'],['l2','l3'],['l1','l2','l4'],['l1','l3'],['l2','l3'],['l1','l3'],['l1','l2','l3','l5'],['l1','l2','l3']]
return data_set2.输入为事务数据集,返回生成的候选频繁项集C_1:def create_C1(data_set):
C1=set()
for t in data_set:
for item in t:
item_set=frozenset([item])
C1.add(item_set)
return C13.判断候选频繁k项集是否满足Apriori算法。
def is_apriori(Ck_item,Lksub1):
for item in Ck_item:
sub_Ck=Ck_item-frozenset([item])
if sub_Ck not in Lksub1:
return False
return True4.通过在L_"k-1"中执行self-joining策略创建一个包含所有频繁候选k项集的集合C_k:
def create_Ck(Lksub1,k):
Ck=set()
len_Lksub1=len(Lksub1)
list_Lksub1=list(Lksub1)
for i in range(len_Lksub1):
for j in range(1,len_Lksub1):
l1=list(list_Lksub1[i])
l2=list(list_Lksub1[ j])
l1.sort()
l2.sort()
if l1[0:k-2]==l2[0:k-2]:
Ck_item=list_Lksub1[i] | list_Lksub1[ j]
#pruning
if is_apriori(Ck_item,Lksub1):
Ck.add(Ck_item)
return Ck5.通过在C_k执行剪枝策略(pruning)生成L_k项集。:
def generate_Lk_by_Ck(data_set,Ck,min_support,support_data):
Lk=set()
item_count={}
for t in data_set:
for item in Ck:
if item.issubset(t):
if item not in item_count:
item_count[item]=1
else:
item_count[item]+=1
t_num=float(len(data_set))
for item in item_count:
if(item_count[item]/t_num)>=min_support:
Lk.add(item)
support_data[item]=item_count[item]/t_num
return Lk6.创建产生所有频繁项集。
def generate_L(data_set,k,min_support):
support_data={}
C1=create_C1(data_set)
L1=generate_Lk_by_Ck(data_set,C1,min_support,support_data)
Lksub1=L1.copy()
L=[]
L.append(Lksub1)
for i in range(2,k+1):
Ci=create_Ck(Lksub1,i)
Li=generate_Lk_by_Ck(data_set,Ci,min_support,support_data)
Lksub1=Li.copy()
L.append(Lksub1)
return L,support_data7.从所产生的频繁项集中生成规则。
def generate_big_rules(L,support_data,min_conf):
big_rule_list=[]
sub_set_list=[]
for i in range(0,len(L)):
for freq_set in L[i]:
for sub_set in sub_set_list:
if sub_set.issubset(freq_set):
conf=support_data[freq_set]/support_data[freq_set-sub_set]
big_rule=(freq_set-sub_set,sub_set,conf)
if conf>=min_conf and big_rule not in big_rule_list:
#printfreq_set-sub_set,"=>",sub_set,"conf:",conf
big_rule_list.append(big_rule)
sub_set_list.append(freq_set)
return big_rule_list8.运行apriori算法,代码如下:if__name__=="__main__":
data_set=load_data_set()
L,support_data=generate_L(data_set,k=3,min_support=0.2)
big_rules_list=generate_big_rules(L,support_data,min_conf=0.7)
for Lk in L:
print("="*50)
print("frequent"+str(len(list(Lk)[0]))+"-itemsets\t\tsupport")print("="*50)
for freq_set in Lk:
print(freq_set,support_data[freq_set])
print("BigRules")
for item in big_rules_list:
print(item[0],"=>",item[1],"conf:",item[2])9.输出结果如下:
=============================================
frequent1-itemsetssupport
=============================================
frozenset({'l1'}) 0.6666666666666666
frozenset({'l2'}) 0.7777777777777778
frozenset({'l4'}) 0.2222222222222222
frozenset({'l3'}) 0.6666666666666666
frozenset({'l5'}) 0.2222222222222222
=============================================
frequent2-itemsetssupport
=============================================
frozenset({'l3','l1'}) 0.4444444444444444
frozenset({'l3','l2'}) 0.4444444444444444
frozenset({'l5','l1'}) 0.2222222222222222
frozenset({'l5','l2'}) 0.2222222222222222
frozenset({'l4','l2'}) 0.2222222222222222
frozenset({'l2','l1'}) 0.4444444444444444
=============================================
frequent3-itemsetssupport
=============================================
frozenset({'l3','l2','l1'})0.2222222222222222
frozenset({'l2','l5','l1'})0.2222222222222222
BigRules
frozenset({'l5'}) => frozenset({'l1'}) conf: 1.0
frozenset({'l5'}) => frozenset({'l2'}) conf: 1.0
frozenset({'l4'}) => frozenset({'l2'}) conf: 1.0
frozenset({'l5','l2'}) => frozenset({'l1'}) conf: 1.0
frozenset({'l5','l1'}) => frozenset({'l2'}) conf: 1.0
frozenset({'l5'}) => frozenset({'l2','l1'}) conf: 1.0
聚类算法是一种的无监督机器学习算法,在无监督机器学习中占据很大的比例。本章主要介绍几种聚类分析的算法,如划分聚类、层次聚类、密度聚类,以及如何评测聚类效果。
基于划分的方法
基于层次的方法
基于密度的方法
基于划分聚类具有概念简单、速度快的优点,但是同时也有很多缺点:它们需要预先定义簇的数目
层次聚类(hierarchical clustering)是指对与给定的数据集对象,我们通过层次聚类算法获得一个具有层次结构的数据集合子集结合的过程
层次聚类分为两种:自底向上的凝聚法以及自顶向下的分裂法
凝聚法指的是初始时将每个样本点当做一个簇,所以原始簇的数量等于样本点的个数,然后依据某种准则合并这些初始的簇,直到达到某种条件或者达到设定的簇的数目
某种准则可以是相似度
分裂层次聚类
分裂法指的是初始时将所有的样本归为一个簇,然后依据某种准则进行逐渐的分裂,直到达到某种条件或者达到设定的簇的数目
基本算法流程
1.计算各数据间的相似度矩阵
2.每个数据就是一个簇
3.Repeat
4.合并两个最相似的簇形成新簇
5.更新相似度矩阵
6.Until 只剩一个类簇
层次聚类不需要事先指定簇的数目,设定层次树高度就可以达到任意选择簇数量的目的
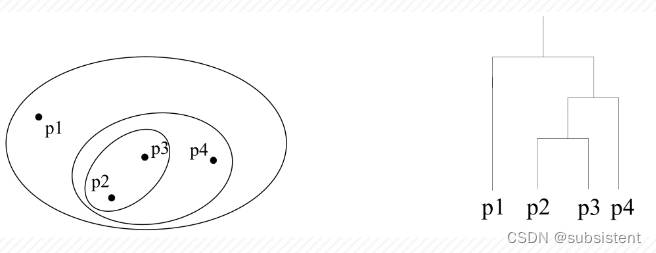
簇之间的相似度如何计算呢,即跟新相似度矩阵?
常用的策略
MIN(单连接)
MAX(全连接)
Group Average(组平均)
Distance Between Centroids(质心距离)
MIN(单连接):单链接的计算方法是将两个簇的数据点中距离最近的两个数据点间的距离作为这两个簇的距离
单链接的运算过程MIN(单连接):单链接的计算方法是将两个簇的数据点中距离最近的两个数据点间的距离作为这两个簇的距离
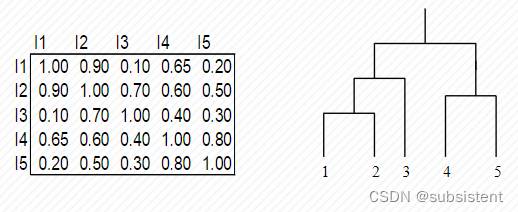
这种方法容易受到极端值的影响。两个并非很相似的簇可能由于其中的某个极端的数据点距离较近而组合在一起
单连接产生非常分散的簇,擅长处理非球形簇
对离群点和噪声敏感
这种方法容易受到极端值的影响。两个并非很相似的簇可能由于其中的某个极端的数据点距离较近而组合在一起
单连接产生非常分散的簇,擅长处理非球形簇
对离群点和噪声敏感
全链接(Complete Linkage)的计算方法与单链接相反,将两个簇的数据点中距离最远的两个数据点间的距离作为这两个簇的距离
全链接(Complete Linkage)的计算方法与单链接相反,将两个簇的数据点中距离最远的两个数据点间的距离作为这两个簇的距离
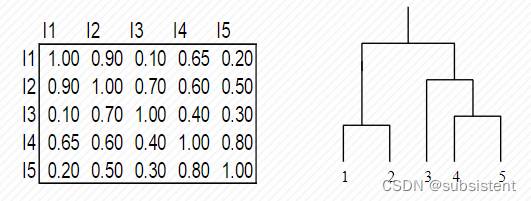
对那些与总体结构不太一致的离群点给予了过多的关注。也就是说,全连接聚类并不能找出最直观的簇结构,容易打破大团
对离群点和噪声敏感
组平均(Average Linkage)的计算方法是计算两个簇的数据点中的每个数据点与其他所有数据点的距离:
对单链接和全链接的权衡,方法计算量比较大,但结果比前两种方法合理
对噪声和离群点没那么敏感
质心距离(Distance Between Centroids)的计算方法是将两个簇的质心距离作为这两个簇的距离
减少组平均方法计算量比较大问题
对噪声和离群点没那么敏感
偏向于球型簇
不需要输入聚类数目k
一旦一个合并被执行,就不能修正
没有一个全局最优化的目标函数
计算量较大
AgglomerativeClustering(n_clusters=2, affinity='euclidean', memory=None, connectivity=None, compute_full_tree='auto', linkage='ward', pooling_func=<function mean at 0x174b938>)
STEP1:加载相关模块
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
from sklearn.neighbors import kneighbors_graphSTEP2:生成噪音数据
def add_noise(x: object, y: object, amplitude: object) -> object:
X = np.concatenate((x, y))
X += amplitude * np.random.randn(2, X.shape[1])
return X.T
def get_spiral(t, noise_amplitude=0.5):
r = t
x = r * np.cos(t)
y = r * np.sin(t)
return add_noise(x, y, noise_amplitude)
def get_rose(t, noise_amplitude=0.02):
# 在极坐标系中,以下方程表示的曲线称为玫瑰曲线:
# r = sin ( k θ )或r = cos ( k θ )
# 当k 是奇数时,玫瑰曲线有k 个花瓣;当k 是偶数时,玫瑰曲线有2k 个花瓣
k = 5
r = np.cos(k*t) + 0.25
x = r * np.cos(t)
y = r * np.sin(t)
return add_noise(x, y, noise_amplitude)STEP3:使用AgglomerativeClustering函数实例化层次聚类模型
def perform_clustering(X, connectivity, title, num_clusters=3, linkage='ward'):
plt.figure()
# 现在把数据和对应的分类数放入聚类函数中进行聚类,使用方差最小化的方法'ward',类簇的数量为3
model = AgglomerativeClustering(linkage=linkage, connectivity=connectivity, n_clusters=num_clusters)
model.fit(X)
# 提取标签
labels = model.labels_
#标识每个簇的形状和颜色
markers = 'ov*'
colors = 'rgb'
for i, marker,color in zip(range(num_clusters), markers, colors):
# 散点不同的簇的点,每个簇的点的形状和颜色一致
plt.scatter(X[labels==i, 0], X[labels==i, 1], s=50,marker=marker, color=color, facecolors='none')
plt.title(title)STEP4:训练模型,并查看聚类的结果
if __name__=='__main__':
# 生成样本数据
n_samples = 500
np.random.seed(2)
t = 2.5 * np.pi * (1 + 2 * np.random.rand(1, n_samples))
X = get_spiral(t)
# 未使用连通矩阵,默认值为None,即层次聚类算法是非结构化的。
connectivity = None
perform_clustering(X, connectivity, 'No connectivity')
# 使用kneighbors_graph生成连通矩阵,为每个样本定义给定数据结构的相邻样本
connectivity = kneighbors_graph(X, 10, include_self=False)
perform_clustering(X, connectivity, 'K-Neighbors connectivity')
plt.show()
基于划分的方法
基于层次的方法
基于密度的方法
密度聚类是根据密度而不是距离来计算样本相似度,所以基于密度的聚类算法能够用于机器学习任意形状的聚类,并且能够有效过滤掉噪声数据对于聚类结果的影响。
常见的基于密度的聚类算法有DBSCAN、OPTICS和DENCLUE等。OPTICS对DBSCAN算法进行了改进,降低了对输入参数的敏感程度。DENCLUE算法综合了基于划分、基于层次的方法。
人工神经网络(ANN)是由简单神经元经过相互连接形成网状结构,通过调节各连接的权重值改变连接的强度,进而实现感知判断。神经网络作为一种重要的机器学习方法,已在医学诊断、信用卡欺诈识别、手写数字识别以 及发动机的故障诊断等领域得到了广泛应用。
本小节完成一个实际案例——手写数字识别。一方面巩固本章前面所学知识,另一方面了解神经网络的完整建模流程。
案例需求描述,首先使用MNIST数据集训练神经网络,然后当拿到新的数字图片后能够识别出图片中的数字是多少。整个案例按照如下步骤完成:
1.导入图片数据集
2.分析MNIST图片特征,并定义训练变量
3.构建模型
4.使用测试数据训练模型,并输出中间状态
5.测试模型
6.保存模型
7.加载模型
下面对各个步骤拆分讲解。
本次案例使用到的是MNIST数据集,这个数据集是一个入门的计算机视觉数据集。
TensorFlow提供了一个库,可以把数据下载下来并进行解压,使用如下代码,即可完成下载和解压功能。
from tensorflow.examples.tutorials.mnist import input_data
mnist= input_data.read_data_sets('mnist_data', one_hot=True)read_data_sets函数首先会查看当前目录下mnist_data中有没有mnist的数据,如果没有,会从网络上下载;如果有,就直接解压。
one_hot=True,表示把下载的样本标签数据转换成one_hot编码。one_hot编码方式通常用于分类模型,比方说该案例中,数字总共有10个类型,那么这个one_hot编码就会占10位,数字0的one_hot编码就是1000000000,也就是第0位上的数字为1,其它位置上为0,数字1的one_hot编码就是01000000000,以此类推,对应位置上的数字为1,其它位置都为0。有多少种类别就占据多少位。
当上面代码执行完成后就会在当前目录下的mnist_data目录有如下的数据。两个标签数据文件(t10k-labels-idx1-ubyte.gz和train-labels-idx1-ubyte.gz),两个图片数据文件(train-images-idx3-ubyte.gz和t10k-images-idx3-ubyte.gz)。

TensorFlow读取到数据后,把整个数据集分作了三大类:训练数据集、测试数据集、验证数据集。每种数据集中都包含了图片及其标签数据(使用了one_hot编码)。
现在验证各种数据集的大小,训练数据集通过train属性获取,测试数据集通过test属性获取,而验证数据集使用validation属性获取,代码如下。
print(mnist.train.images.shape)
print(mnist.test.images.shape)
print(mnist.validation.images.shape)运行结果如下。
(55000, 784)
(10000, 784)
(5000, 784)
训练数据集的形状是55000*784;测试数据集的形状是10000*784;验证数据集的形状是5000*784;这表示训练数据集的图片数有55000张,测试数据集的图片有10000张,验证数据集图片有5000张。后面的数字784则代表了像素点个数,由于mnist中的每张图片都是28*28像素的,那么所有像素点就是784,这相当于把一张图片从二维的图形拉成了一个一维的数据。
下面验证图片和标签的对应关系,选取训练数据集中的第二张图片和第二个标签数据。由于现在的图片数据是一维的,首先把它转化成二维的,然后把图片展示出来。
# 读取第二张图片
im= mnist.train.images[1]
# 把图片数据变成28*28的数组
im= im.reshape(-1, 28)
# 展示图片
pylab.imshow(im)
pylab.show()
# 打印第二个标签数据
print(mnist.train.labels[1])标签数据打印出来结果如下。
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
第四个位置上为1,按照one_hot编码规则,就说明它表示的是3。
刚刚对三个数据集的形状大小以及特点进行了分析,现在介绍三种数据集的使用场景。
1.训练数据集用于对构建的神经网络进行训练
2.测试数据集验证训练的正确率
3.验证数据集评估模型的泛化能力。
接下来定义输入输出的参数,输入就是一张张的图片,那么它的形状是n*784(表示n张图片),而输出就是推测出的数字one_hot编码,每个图片对应一个one_hot编码,所以输出的形状是n*10。代码如下所示。
import tensorflow as tf
# 图片输入占位符
x = tf.placeholder(tf.float32, [None, 784])
# 图片标签数据占位符
y = tf.placeholder(tf.float32, [None, 10])shape参数中的None值表示这个对应维度可以是任意长度,x,y占位符形状中的None就表示根据图片张数来确定。
TensorFlow中构架模型通常分作如下几部分:
定义权重和偏置项
定义前向传播函数
定义反向传播函数
1)定义权重和偏置项
TensorFlow中都是使用各属性值分别乘以相应的权重,然后加上偏置项来推测输出。
首先确定权重的形状,由于一张图片中有784个像素,为了确定每个像素对于最终结果的影响,所以需要分别对这个784个像素点进行权重求值,通过这个权重需要输出的是一个长度为10的数组(因为本案例的类别有10个类别),即权重的形状就为784*10;
对于权重求出来的结果需要加上偏置项,所以偏置项的形状为长度为10的数组。代码如下:
# 定义权重
weights =tf.Variable(tf.random_normal([784, 10]))
# 定义偏置项
biases =tf.Variable(tf.zeros([10]))通常权重初始值设置为随机数,而偏置项设置为0。
2)定义前向传播函数
前向传播函数的意思就是通过当前的权重和偏置项推测出一个结果出来。本案例使用softmax进行分类。这个分类器的作用是把原始的输出结果经过softmax层后,能够推断出各个结果概率分布情况。代码如下:
# 定义前向传播函数
pred=tf.nn.softmax(tf.matmul(x, weights) +biases)本例中一个图片经过softmax后的输出结果可能是[0.1, 0.1, 0.6, 0.0, 0.1, 0.0, 0.0, 0.1, 0.0, 0.0]
这里把图片数据的权重和作为softmax的输入值求出结果的概率分布。
3)定义反向传播函数
前向传播函数用作预测,而反向传播函数用于学习调整,并减小整个神经网络的误差。因此定义反向传播函数有两个步骤:
1.定义损失函数,也就是推测值与标签数据之间的误差;
2.使用优化器减少损失。
本案例中使用交叉熵定义预测值和实际值之间的误差,并使用梯度学习算法学习以达到快速减少误差的目的。代码如下:
# 定义损失函数
cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred), reduction_indices=1))
# 定义学习率
learning_rate= 0.01
# 使用梯度下降优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)在这个过程中weights和biases会不停的进行调整,以达到最小损失的效果。
模型构建好后,需在会话中实际训练数据,其实就是运行优化器。在这个过程中对整体数据迭代25次,使用training_epochs定义;一次迭代中,每次取出训练集中的100张图片进行训练,直到所有图片训练完成,训练集大小用batch_size定义;每迭代5次展示当前的损失值。具体代码如下所示:
# 迭代次数
train_epochs= 25
# 批次数据大小
batch_size= 100
# 每隔多少次展示一次
display_step= 5
with tf.Session() as sess:
# 首先初始化所有变量
sess.run(tf.global_variables_initializer())
# 启动循环训练
for epoch in range(train_epochs):
# 当前迭代的平均损失值
avg_cost= 0
# 计算批次数
total_batches= int(mnist.train.num_examples/ batch_size)
# 循环所有训练数据
for batch_index in range(total_batches):
# 获取当前批次的数据
batch_x, batch_y= mnist.train.next_batch(batch_size)
# 运行优化器,并得到当前批次的损失值
_, batch_cost= sess.run([optimizer, cost], feed_dict={x:batch_x, y:batch_y})
# 计算平均损失
avg_cost+= batch_cost/ total_batches
if(epoch + 1) % display_step== 0:
print('Epoch:%04d cost=%f'% (epoch+1, avg_cost))
print("Train Finished")最终运行结果如下。
Epoch:0005 cost=2.160714
Epoch:0010 cost=1.338857
Epoch:0015 cost=1.070279
Epoch:0020 cost=0.931654
Epoch:0025 cost=0.844308
Train Finished
可以看到随着迭代的不停进行,损失值在不停地减小。
模型训练完后,需要使用准确率算法测试模型的好坏。
准确率的算法:直接判断预测结果和真实标签数据是否相等,如果相等则是正确的预测,否则为错误预测,最后使用正确个数除以测试数据集个数即可得到准确率。
由于是one_hot编码,所以这里使用argmax函数返回one_hot编码中数字为1的下标,如果预测值下标和标签值下标相同,则说明推断正确。代码如下:
# 把每个推测结果进行比较得出一个长度为测试数据集大小的数组,数组中值都是bool,推断正确为True,否则为False
correct_prediction=tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# 首先把上面的bool值转换成数字,True转换为1,False转换为0,然后求准确值
accuracy =tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print('Accuracy:%f' % accuracy.eval({x:mnist.test.images, y:mnist.test.labels}))注意:这段代码要在Session上下文管理器中执行。
测试正确率的方法和损失函数的定义方式略有差别,但意义却类似。
如果一个模型训练好后,可以把它保存下来,以便下一次使用。要保持模型,首先必须创建一个saver对象,实例化后调用该对象的save方法进行保存,代码如下。
# 实例化saver
saver = tf.train.Saver()
# 模型保存位置
model_path= 'log/t10kmodel.ckpt'
save_path= saver.save(sess, model_path)
print('Model saved in file:%s' % save_path)代码运行完成后,就会在当前目录下的log目录下保存模型,文件结构如下图所示。

既然模型能保存,那肯定可以用来加载,解决类似的问题。
下面做个实验:先把模型加载回来使用saver的restore函数,然后用加载回来的模型对两张图片进行预测结果,让它与真实数据进行比较。
接下来重启一个Session,然后再进行模型加载,代码如下。
print("Starting 2nd session...")
with tf.Session() as sess:
# 初始化变量
sess.run(tf.global_variables_initializer())
# 恢复模型变量
saver =tf.train.Saver()
model_path='log/t10kmodel.ckpt'
saver.restore(sess, model_path)
# 测试
modelcorrect_prediction=tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# 计算准确率
accuracy =tf.reduce_mean(tf.cast(correct_prediction, tf.float32))print ("Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))
output =tf.argmax(pred, 1)
batch_xs, batch_ys=mnist.train.next_batch(2)
outputval,predv=sess.run([output,pred], feed_dict={x: batch_xs})
print(outputval,predv,batch_ys)
im=batch_xs[0]
im=im.reshape(-1,28)
pylab.imshow(im)
pylab.show()
im=batch_xs[1]
im=im.reshape(-1,28)
pylab.imshow(im)
pylab.show()代码运行结果如下。
Starting 2nd session...
Accuracy: 0.8355
[5 0] [[4.7377224e-08 3.1628127e-12 3.2020047e-09 1.0474083e-05 1.2764868e-119.9984884e-01 8.5975152e-08 6.0223890e-15 1.4054133e-04 2.6081961e-09][1.0000000e+00 6.2239768e-19 1.7162091e-10 2.9598889e-11 7.0261283e-202.1224080e-09 4.5077828e-16 1.6341132e-15 2.5803047e-13 9.8767874e-16]] [[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.][1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
文本分析是机器学习领域重要的应用之一。通过对文本内部特征提取,获取隐含的语义信息或 概括性主题,从而产生高质量的结构化信息,合理的文本分析技术能够获取作者的真实意图。本章首先讨论文本数据处理的概念,再介绍中英文的文本数据处理方法对比,然后介绍文本分析的案例操作,最后会介绍自然语言处理的应用相关知识。
图像分析是机器学习领域重要的应用之一。本章讨论图像相关的基本概念,然后结合Python图像处理工具包介绍图像数据分析的常用方法。
深度学习是一种利用复杂结构的多个处理层来实现对数据进行高层次抽象的算法,是机器学习的一个重要分支。传统的BP算法往往仅有几层网络,需要手工指定特征且易出现局部最优问题;而深度学习引入了概率生成模型,可自动从训练集里提取特征,解决了手工特征考虑不周的问题;而且初始化了神经网络权重,采用反向传播算法进行训练,与BP 算法相比取得了很好的效果。 本章主要介绍深度学习相关的概念和主流框架,重点介绍卷积神经网络和循环神经网络的理论、整体结构以及常见应用,最后介绍一个基于卷积神经网络识别手写数字实战实验。
本章之前的各种机器学习方法来解决问题的解决思路是:
“人工提取特征+模型”
也就是说,需要在训练模型之前通过特征工程提取特征。
提取出合适的特征并不是一件容易的事,尤其是在图像、文本、语音等领域。即使是成功的模型,也难以推广应用。
以神经网络为基础的深度学习为特征提取问题提供了有效的解决方法,使得学习过程可以自动从大量训练数据中学习特征,不再需要过多人工干预,实现了端到端(EndtoEnd)学习。机器学习得以异军突起,得到广泛应用。
深度学习是一种使用包含复杂结构的多个处理层对数据进行高层次抽象的算法,是机器学习的一个重要分支。
神经网络层数越多,处理复杂问题能力就越强。但发展后随之而来的梯度消散问题又成了“拦路虎”,使得神经网络的层数不能任意增加,因此,神经网络的发展一度止步不前。
后来随着硬件和算法的进步,才一步步发展起来。主要是以下三方面:
1.大规模的训练样本可以缓解过拟合问题
2.网络模型的训练方法也有了显著的进步。发展出了很多缓解梯度消散问题的优化技术和学习方法,如 合 理 的 激 活 函 数、正 则 化、批标准化(BatchNormalization)、深 度 残 差 网 络(DeepResidualNetwork)等,使得神经网络的层次越来越多,处理问题的能力也越来越强。
3.计算机硬件的飞速发展(如英伟达显卡的出现)使得训练效率能够以几倍、十几倍的幅度提升。
2012年的ImageNet竞赛上,Hinton和他的学生用多层卷积神经网络在图像分类竞赛中取得了显著的成绩。此后,深度学习无论在学术上还是工业上都进入了爆发式的发展时期。到了2017年ImageNet的竞赛,深度学习在图像分类竞赛中的错误率已经低于人类5%的错误率。
深度神经网络具有强大的特征学习能力,相比于手工设计特征速度和准确性均有较大优势。随着求解问题的扩大,应用范围也越来越广。
深度神经网络是一个包含多个隐藏层的人工神经网络,影响力较大的类型主要有2种:
卷积神经网络:卷积特性使得整个网络具有一定的缩放、平移及形变不变性,具有良好的特征表达能力。
循环神经网络:该网络隐藏层的输入不仅包括输入层的数据,还包括前一时刻的隐藏层数据。这种结构的网络能有效处理序列数据,如自然语言处理。
以深度学习为代表的人工智能在图像识别、语音处理、自然语言处理等领域都有了很大突破。但在认知方面进展依然有限,对很多问题还没有满意的解决方案,还有很大的发展空间

目标分类不需要定位
物体检测需要定位出物体的位置(bbox),且要把所有图片中的物体都识别定位出来。卷积神经网络简介
卷积神经网络(ConvolutionalNeuronNetwork,CNN)是人工神经网络的一种,是由对猫的视觉皮层的研究发展而来的。研究发现猫视觉皮层的细胞对视觉子空间更敏感,其是通过子空间的平铺扫描实现对整个视觉空间的感知。卷积神经网络源于日本的福岛(Fukushima)于1980年提出的基于感受野的模型。
在1998年,乐康(Lecun)等人提出了LeNet-5卷积神经网络模型,用于对手写字母进行文字识别,它基于梯度的反向传播算法对模型进行训练,将感受野理论应用于神经网络。
近年来,卷积神经网络已在图像理解领域得到了广泛的应用,特别是随着大规模图像数据的产生及计算机硬件(特别是GPU)的飞速发展,卷积神经网络及其改进方法在图像理解中取得了突破性的成果,引发了研究的热潮。
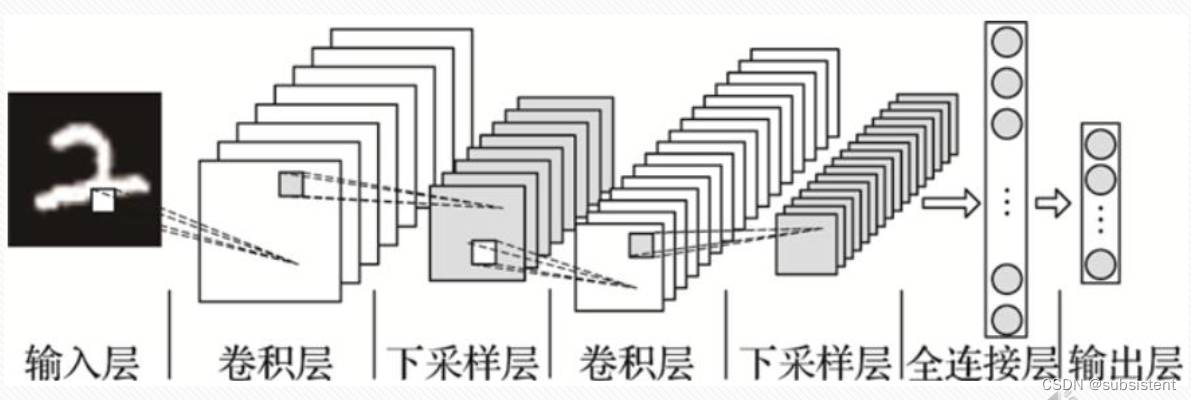
输入层
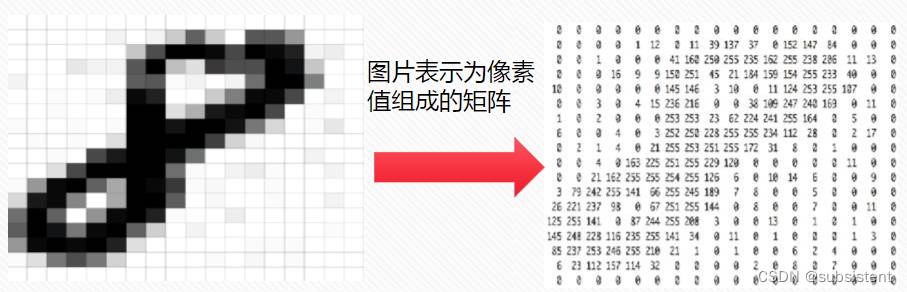 通道:图片的特定成分。
通道:图片的特定成分。
数码相机照片有三个通道——RGB,可以想象为是三个2d矩阵叠在一起,每个矩阵的值都在0-255之间。
灰度图像只有单通道。
矩阵中的每个像素值还是0到255,0表示白,255表示黑。卷积神经网络的整体结构
卷积层
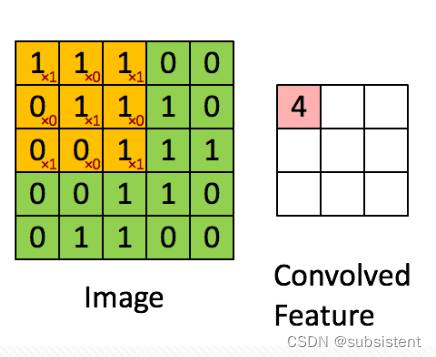
Filter
“滤波器”或者“特征探测器”,这里的重点就是,理解滤波器对于原输入图片来说,是个特征探测器。它的元素是通过网络训练得到的。
卷积操作
在原始图片(绿色)上从左往右、从上往下按照一定步数滑动橙色矩阵,并且在每个位置上,我们都对两个矩阵的对应元素相乘后求和得到一个整数,这就是输出矩阵(粉色)的元素。注意,3x3矩阵每次只“看见”输入图片的一部分,即局部感受野。
Convolved Feature
在原图上滑动滤波器、点乘矩阵所得的矩阵称为“卷积特征”、“激励映射”或“特征映射”。卷积神经网络的整体结构
卷积层
过滤器3×3 与原始图像上每个同样大小的区域作“点乘”计算
“点乘”:每个元素相乘再累加
步幅(Stride)
步幅是每次滑过的像素数。当Stride=2的时候每次就会滑过2个像素。步幅越大,特征映射越小。
补零(Zero-padding)
边缘补零,对图像矩阵的边缘像素也施加滤波器。补零的好处是让我们可以控制特征映射的尺寸。补零也叫宽卷积,不补零就叫窄卷积。卷积神经网络的整体结构
深度(Depth)
深度就是卷积操作中用到的滤波器个数。这里对图片用了两个不同的滤波器,从而产生了两个特征映射。你可以认为这两个特征映射也是堆叠的2d矩阵,所以这里特征映射的“深度”就是2。
池化层
池化层(PoolingLayer)是一种向下采样(Downsampling)的形式,在神经网络中也称之为子采样层(Sub-samplingLayer)。池化层神经网络不会改变三维矩阵的深度,但是它可以缩小矩阵的大小。池化操作可以认为是将一张分辨率较高的图片转化为分辨率较低的图片。
空间池化可以有很多种形式:最大(Max),平均(Average),求和(Sum)等等。最大池化成效最好。卷积神经网络的整体结构
池化层
 激活函数
激活函数
激活函数(activationfunction)运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经网络。神经网络之所以能解决非线性问题,本质上就是激活函数加入了非线性因素,弥补了线性模型的表达力,把“激活的神经元的特征”通过函数保留并映射到下一层。
常见卷积神经网络的激活函数有Sigmoid、tanh、ReLU函数。

sigmoid是传统神经网络中最常用的激活函数之一。
图像如下图所示
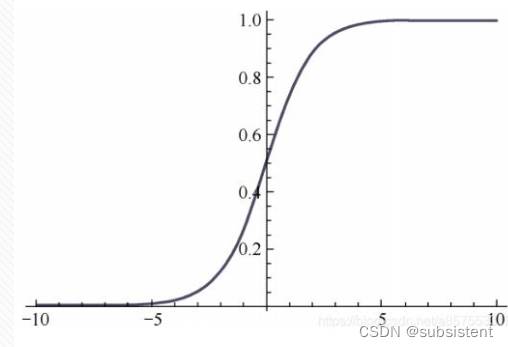
ReLU函数是目前最受欢迎的激活函数。
权重初始化
把权重初始化为0的方式不可取的。利用小的随机数据初始化每个神经元的权值,打破对称性。
随机初始化:如果权值初始化过大或过小,很容易出现梯度饱和或梯度消失。
Xavier初始化:尽可能的让输入和输出服从相同的分布,这样就能够避免后面层的激活函数的输出值趋向于0。
全连接层
卷积层得到的每张特征图表示输入信号的一种特征,而它的层数越高表示这一特征越抽象,为了综合低层的各个卷积层特征,用全连接层(Fully connected layer)将这些特征结合到一起,然后用Softmax进行分类或逻辑回归分析
输出层
输出层(Output Layer)的另一项任务是进行反向传播,依次向后进行梯度传递,计算相应的损失函数,并重新更新权重值。在训练过程中可以采用Dropout来避免训练过程产生过拟合。输出层的结构与传统神经网络结构相似,是基于上一全连接层的结果进行类别判定。
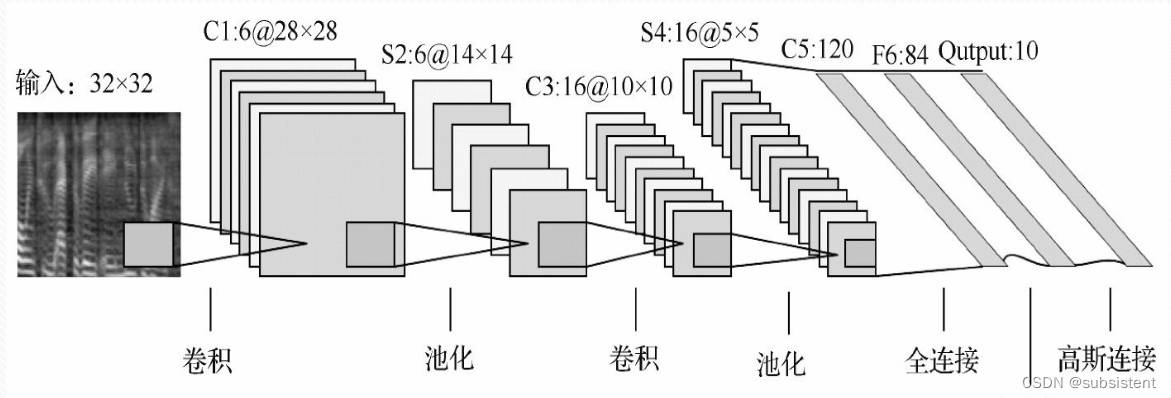
(1)输入层输入层的图像一般要比原始图像大一些,间接对原始图像进行缩小,使笔 画 连 接 点 和 拐 角 等 图 像 特 征 处 于 感 受 野 的 中 心。实际的数据图像为28×28,而输入层的大小为32×32,这样可以满足更高层的卷积层(如C3)依然可以提取到数据的核心特征。
(2)卷积层卷积层有3个,分别是C1、C3和C5,其中C1输入大小为32×32,卷积核大小为5×5,经过卷积运算,得到特征图的大小为28×28,即:32-5+1=28。C1有6个特征图(featuremap),每个特征图对应一个图像的通道(channel),那么C1层神经元的数量为28×28×6,这一层的待训练参数数量为6×(5×5+1)=156,其中的1表示每个卷积核有一个偏置。其他卷积层C3和C5与之类似。
(3)池化层池化层有2个,分别是S2(6个14×14)和S4(16个5×5),使用最大化池化将特征区域中的最大值作为新的抽象区域的值,减少数据的空间大小,同时也就减少了模型复杂度(参数数量)和运算量,一定程度上可以避免过拟合,也可以强化图像中相对位置等显著特征。
(4)全连接层卷积层得到的每张特征图表示的是输入信号的一种特征,层数越高特征越抽象,为了综合低层的卷积层特征,使用全连接层将这些特征结合到一起,计算输入向量和权重向量的点积,然后应用Sigmoid激活函数输出单元状态,全连接层的输出为84,而输入为120,加上1个偏置,可训练的参数为84×(120+1)=10164。
(5)输出层输出层根据最后一个完全连接层的结果进行判别。它的输出类别是10,分别代表数字0-9的概率。每个类别对应84个输入,可训练参数为84×10=840。通过计算输入向量和参数向量之间的欧氏距离作为损失函数,距离越大,损失越大。输出层的另一个任务是进行反向传播,然后向后进行梯度转移,以计算相应的损耗函数,从而使全连通层的输出与参数向量之间的距离最小化。
以下是基于TensorFlow实现的LeNet网络结构代码:
def LeNet(x):
#C1:卷积层 输入= 32×32×1. 输出= 28×28×6.
conv1_w =tf.Variable(tf.truncated_normal(shape =[5,5,1,6],mean =m,stddev=sigma))
conv1_b =tf.Variable(tf.zeros(6))
conv1 =tf.nn.conv2d(x,conv1_w,strides =[1,1,1,1],padding ='VALID')+conv1_b conv1=tf.nn.relu(conv1)
#S2:池化层输入= 28×28×6 输出= 14×14×6
pool_1 =tf.nn.max_pool(conv1,ksize =[1,2,2,1],strides =[1,2,2,1],padding ='VALID')
#C3:卷积层. 输入= 14×14×6 输出= 10×10×16.
conv2_w =tf.Variable(tf.truncated_normal(shape =[5,5,6,16],mean =m,stddev=sigma))
conv2_b =tf.Variable(tf.zeros(16))
conv2 =tf.nn.conv2d(pool_1,conv2_w,strides =[1,1,1,1],padding ='VALID')+conv2_b
conv2 =tf.nn.relu(conv2)
#S4:池化层输入= 10×10×16 输出= 5×5×16
pool_2 =tf.nn.max_pool(conv2,ksize=[1,2,2,1],strides =[1,2,2,1],padding ='VALID')
fc1 =flatten(pool_2)
#压缩成1 维输入= 5×5×16 输出= 1×400
#C5:全连接层输入= 400 输出= 120
fc1_w =tf.Variable(tf.truncated_normal(shape =(400,120),mean =m,stddev=sigma))
fc1_b =tf.Variable(tf.zeros(120))
fc1 =tf.matmul(fc1,fc1_w)+fc1_b
fc1 =tf.nn.relu(fc1)
#F6:全连接层输入= 120 输出= 84
fc2_w =tf.Variable(tf.truncated_normal(shape =(120,84),mean =m,stddev=sigma))
fc2_b =tf.Variable(tf.zeros(84))
fc2 =tf.matmul(fc1,fc2_w)+fc2_b fc2 =tf.nn.relu(fc2)
#输出层输入= 84 输出= 10
fc3_w =tf.Variable(tf.truncated_normal(shape =(84,10),mean =m,stddev=sigma))
fc3_b =tf.Variable(tf.zeros(10))
logits =tf.matmul(fc2,fc3_w)+fc3_b
return logitsLeNet网络构造完成之后,以交叉熵函数作为损失函数,并采用Adam策略进行自动优化学习率,具体过程如下代码所示。
rate =0.001
logits =LeNet(x)
cross_entropy=tf.nn.softmax_cross_entropy_with_logits(logits,one_hot_y)
loss_operation=tf.reduce_mean(cross_entropy)
optimizer =tf.train.AdamOptimizer(learning_rate=rate)
training_operation=optimizer.minimize(loss_operation)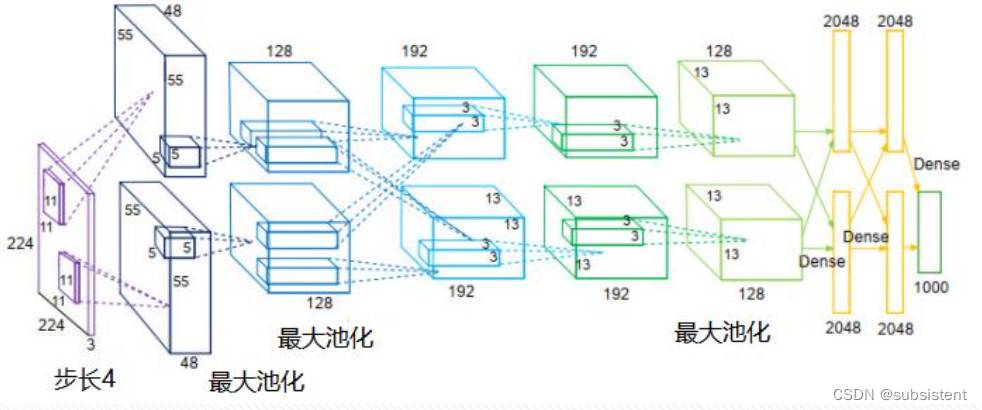
TensorFlow中AlexNet的官方示例代码如下所示:
with tf.variable_scope(scope,'alexnet_v2',[inputs]) as sc:
end_points_collection=sc.original_name_scope+'_end_points’
with slim.arg_scope([slim.conv2d,slim.fully_connected,slim.max_pool2d],outputs_collections=[end_points_collection]):
net =slim.conv2d(inputs,64,[11,11],4,padding='VALID',scope='conv1')
net =slim.max_pool2d(net,[3,3],2,scope='pool1')
net =slim.conv2d(net,192,[5,5],scope='conv2')
net =slim.max_pool2d(net,[3,3],2,scope='pool2')
net =slim.conv2d(net,384,[3,3],scope='conv3')
net =slim.conv2d(net,384,[3,3],scope='conv4')
net =slim.conv2d(net,256,[3,3],scope='conv5')
net =slim.max_pool2d(net,[3,3],2,scope='pool5')
With slim.arg_scope([slim.conv2d],weights_initializer=trunc_normal(0.005),biases_initializer=tf.constant_initializer(0.1)):
net =slim.conv2d(net,4096,[5,5],padding='VALID',scope='fc6')
net =slim.dropout(net,dropout_keep_prob,is_training=is_training,scope='dropout6')
net =slim.conv2d(net,4096,[1,1],scope='fc7')
end_points=slim.utils.convert_collection_to_dict(end_points_collection)
net =slim.dropout(net,dropout_keep_prob,is_training=is_training,scope='dropout7')
net =slim.conv2d(net,num_classes,[1,1],activation_fn=None,normalizer_fn=None,biases_initializer=tf.zeros_initializer(),scope='fc8')
net =tf.squeeze(net,[1,2],name='fc8/squeezed')
end_points[sc.name +'/fc8']=net
return net,end_pointsAlexNet之所以能够取得成功的原因如下。
(1)采用非线性激活函数ReLU
(2)采用数据增强和Dropout防止过拟合
(3)采用GPU实现
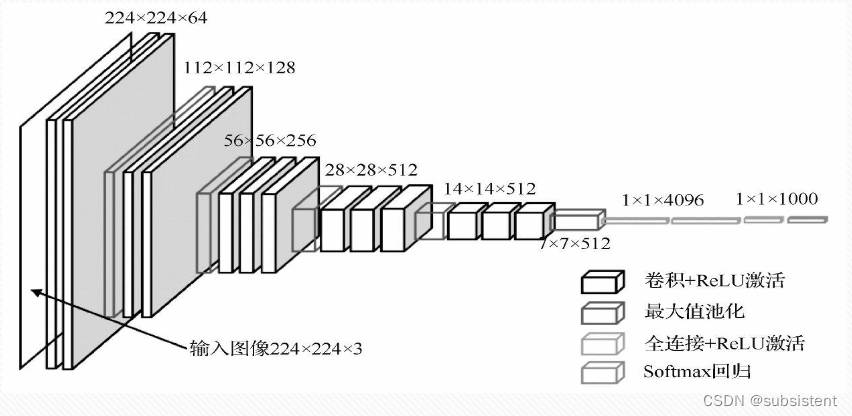
以下代码是基于TensorFlow中的tensorflow.contrib.slim库实现的VGG网络。
def vgg16(inputs):
with slim.arg_scope([slim.conv2d,slim.fully_connected],activation_fn=tf.nn.relu,weights_initializer=tf.truncated_normal_initializer(0.0,0.01),weights_regularizer=slim.l2_regularizer(0.0005)):
net =slim.repeat(inputs,2,slim.conv2d,64,[3,3],scope='conv1')
net =slim.max_pool2d(net,[2,2],scope='pool1')
net =slim.repeat(net,2,slim.conv2d,128,[3,3],scope='conv2')
net =slim.max_pool2d(net,[2,2],scope='pool2')
net =slim.repeat(net,3,slim.conv2d,256,[3,3],scope='conv3')
net =slim.max_pool2d(net,[2,2],scope='pool3')
net =slim.repeat(net,3,slim.conv2d,512,[3,3],scope='conv4')
net =slim.max_pool2d(net,[2,2],scope='pool4')
net =slim.repeat(net,3,slim.conv2d,512,[3,3],scope='conv5')
net =slim.max_pool2d(net,[2,2],scope='pool5')
net =slim.fully_connected(net,4096,scope='fc6')
net =slim.dropout(net,0.5,scope='dropout6')
net =slim.fully_connected(net,4096,scope='fc7')
net =slim.dropout(net,0.5,scope='dropout7')
net =slim.fully_connected(net,1000,activation_fn=None,scope='fc8')
return netGoogLeNet网络中Inception结构
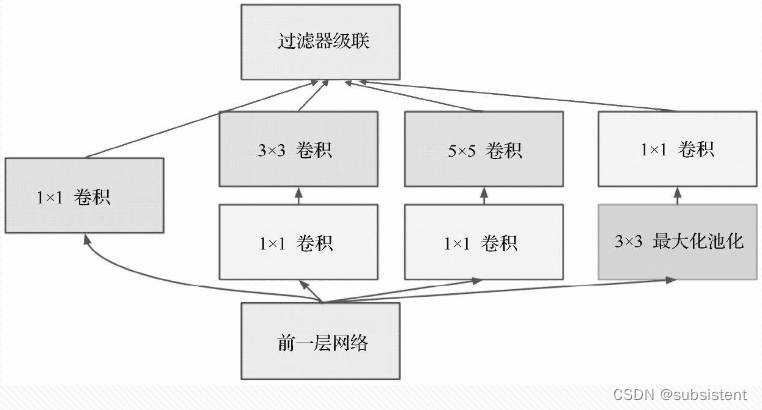
残差网络学习过程
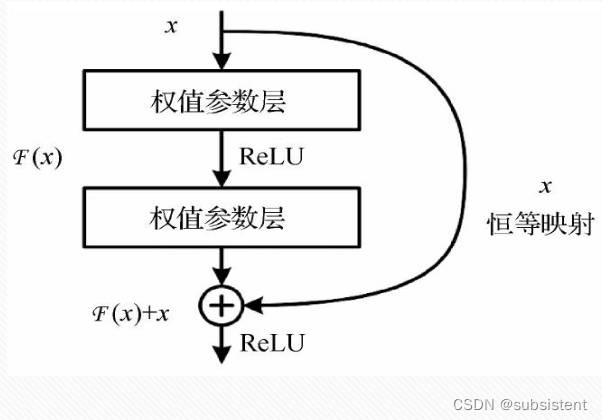
以下代码是构建ResNet模型的示意代码
def resnet_model(input_tensor,n,reuse):
layers =[]
with tf.variable_scope('conv0',reuse=reuse):
conv0 =create_conv_bn_relu_layer(input_tensor,[3,3,3,16],1)
layers.append(conv0)
for i in range(n):
with tf.variable_scope('conv1_%d'%i,reuse=reuse):
if i==0:
conv1 =create_residual_block(layers[-1],16,first_block=True)
else:
conv1 =crate_residual_block(layers[-1],16)
layers.append(conv1)
with tf.variable_scope('fc',reuse=reuse):
in_channel=layers[-1].get_shape().as_list()[-1]
bn_layer=create_batch_normalization_layer(layers[-1],in_channel)
relu_layer=tf.nn.relu(bn_layer)
global_pool=tf.reduce_mean(relu_layer,[1,2])
assert global_pool.get_shape().as_list()[-1:]==[64]
output =create_output_layer(global_pool,10)
layers.append(output)
return layers[-1]上述代码中主要不同之处在于其将不同的层合并成独立的Residual块,其中创建residual块的方法如下:
def create_residual_block(input_layer,output_channel,first_block=False):
input_channel=input_layer.get_shape().as_list()[-1]
with tf.variable_scope('conv1_in_block'):
if first_block:
filter=create_variables(name='conv',shape=[3,3,input_channel,output_ channel])
conv1 =tf.nn.conv2d(input_layer,filter=filter,strides=[1,1,1,1],padding='SAME')
else:
conv1 =bn_relu_conv_layer(input_layer,[3,3,input_channel,output_channel],stride)
with tf.variable_scope('conv2_in_block'):
conv2 =bn_relu_conv_layer(conv1,[3,3,output_channel,output_channel],1)
output =conv2 +input_layer
return output循环神经网络结构:
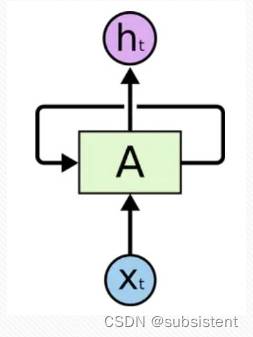
循环神经网络结构展开:
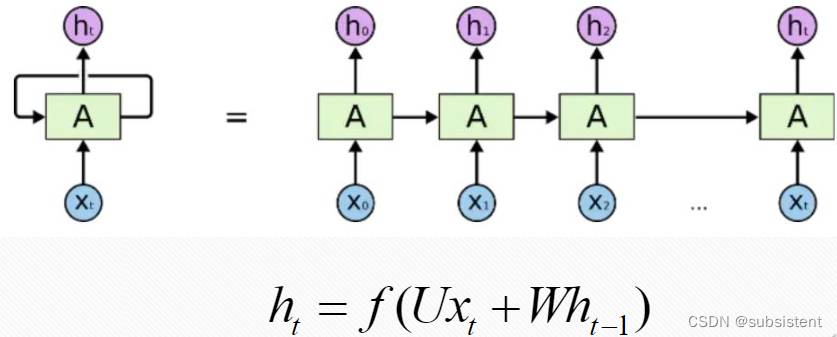
【例】对一个包含5个单词的语句,展开的网络便是一个五层的神经网络,每一层代表一个单词,网络参数为w1、w2和w3,如图所示。可以看到在时间t为1~5时网络的输入状态,每一个状态都会产生一个神经网络;当时间t=5时,输入包括了之前所有的状态输出。
RNN大致可以分为一对多、多对一、多对多几种:
LSTM模块结构:

LSTM细胞状态:
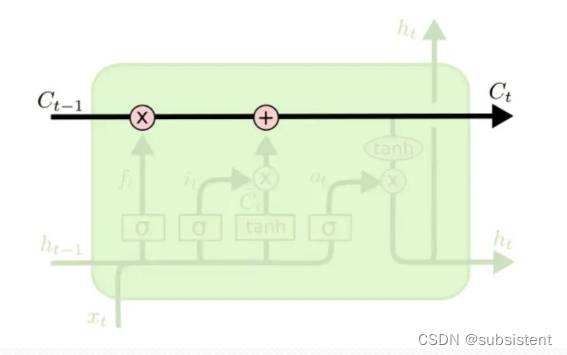
LSTM门结构:
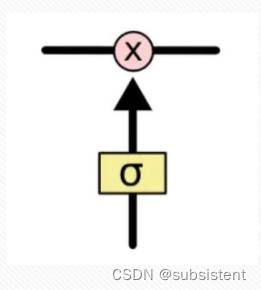
LSTM遗忘门:
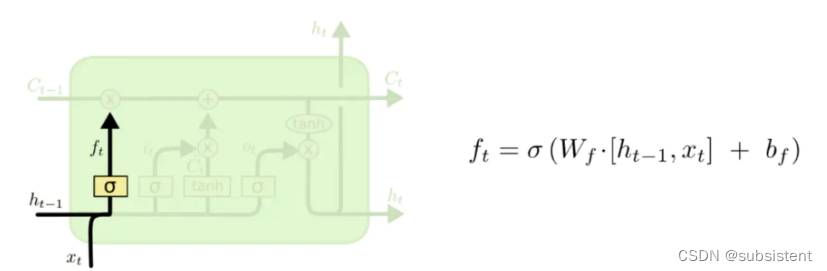
LSTM输出门-输出 :

LSTM输入门与忘记门结合:
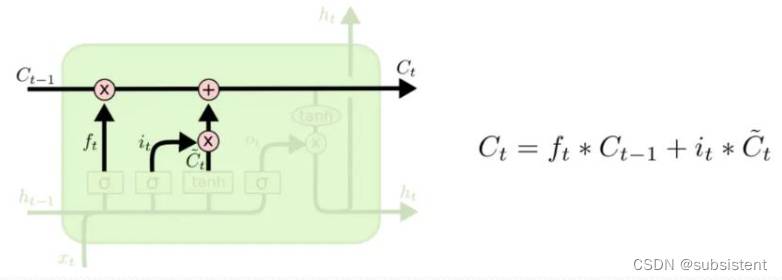
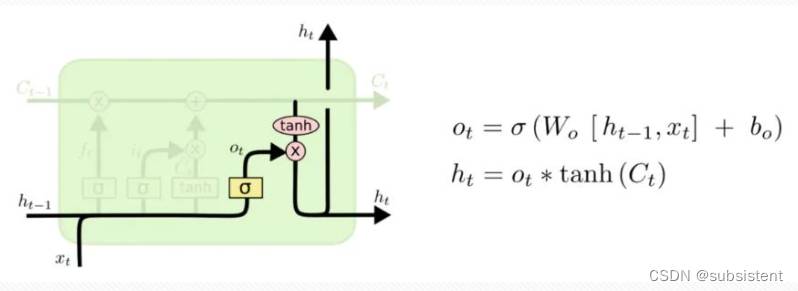
【例】基于LSTM预测股票走势。
股票市场的股价、指数等数据是典型的时间序列形式,即每隔一个时间段就会生成一条数据,本例是基于上证指数的收盘价对其进行分析预测。按照收集数据、建模、训练、预测这一过程进行。其中数据来源于上海证券交易所公开数据,每3分钟一条记录。共计30000条数据,数据格式如图所示。
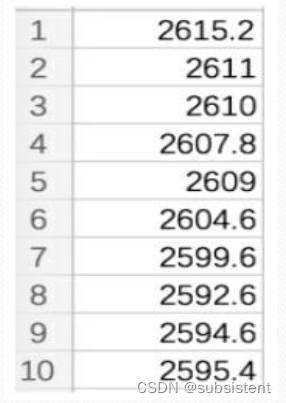
Karas库用于构建模型,代码如下:
def build_model(layers):
model =Sequential()
model.add(LSTM(input_shape=(layers[1],layers[0]),output_dim=layers[1],return_ sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(layers[2],return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(output_dim=layers[3]))
model.add(Activation("linear"))
model.compile(loss="mse",optimizer="rmsprop")
return model
seq_len=100
X_train,y_train,X_test,y_test=lstm.load_data('small_data.csv',seq_len,True)
filepath="model.h5"
checkpoint =ModelCheckpoint(filepath,monitor='loss',verbose=1,save_best_only=True,mode='min')
callbacks_list=[checkpoint]
model =build_model([1,100,200,1])
model.fit(X_train,y_train,batch_size=512,nb_epoch=1,validation_split=0.05,callbacks=callbacks_list)
print(model.summary())1.熟悉MNIST数据集的内容和格式
2.掌握通过卷积神经网络(CNN)的原理和运用
3.熟悉神经网络模型的创建、训练和预测的流程实验目的
本实验使用MNIST数据集,该数据包括55000个训练集数字图像和标签、5000个验证图像和标签,以及10000个测试集图像和标签。运用卷积神经网络(CNN)的原理,创建神经网络模型,读取55000个图像和标签进行训练,最后对测试数据集进行预测。MNIST数据集是一个被大量使用的数据集,几乎所有的图像训练教程都会以它为例子,它已经成为了一个典范数据。
本实验运用基于卷积神经网络(CNN)的TensorFlow实现对MNIST数据的识别.
卷积神经网络的特点在于隐藏层分为卷积层、激励层和池化层。
各层的作用
-输入层:用于将数据输入到训练网络
-卷积层:使用卷积核提取特征
-激励层:对线性运算进行非线性映射,解决线性模型不能解决的问题
-池化层:对特征进行稀疏处理,目的是减少特征数量
-全连接层:在网络末端恢复特征,减少特征的损失
-输出层:输出结果
1. 输入层
输入层的数据不限定维度,mnist数据集中是28*28的灰度图片,因此输入为[28, 28]的二维矩阵。2.卷积层
卷积层使用卷积核即过滤器来获取特征,这里需要指定过滤器的个数、大小、步长及零填充的方式,其工作方式如下图:
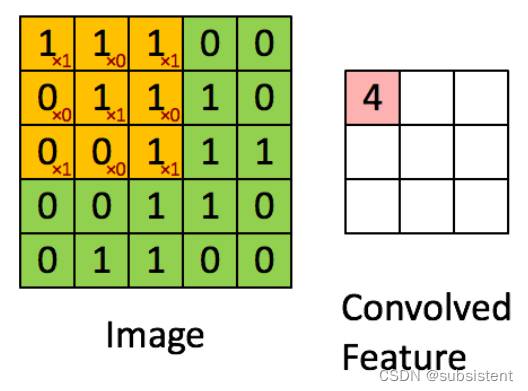
3.激励层
激励层是神经网络的关键,有了激活函数就可以解决一些复杂的非线性问题,卷积神经网络常用的激活函数是Relu函数:f(x) = max(0,x)。
4.池化层
池化层的主要目的是特征提取,Feature Map去掉不重要的样本,进一步减少参数数量,池化层常用的方法是Max Pooling。

5.全连接层
前面的卷积和池化相当于是特征工程,全连接相当于是特征加权,在整个神经网络中起到“分类器”的作用。
6.输出层
输出层表示最终结果的输出,该问题是个十分类问题,因此输出层有10个神经元向量。模型结构如下所示:
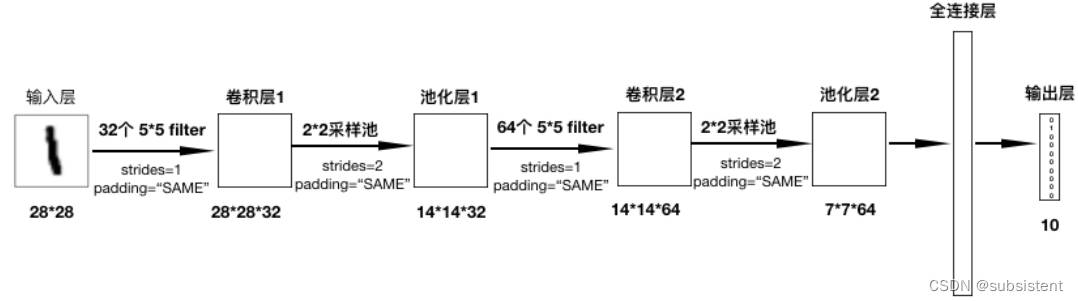
Ubuntu 16.04
Python 3.6
Numpy1.18.3
ensorFlow 1.5.0
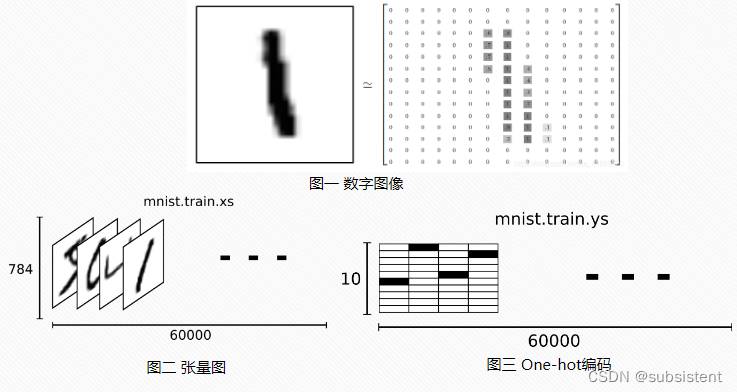
导入TensorFlow的examples里的数据集组件,加载mnist数据集。这时会创建一个MNIST_data目录,然后从网上下载数据集到这个目录。
实现代码如下:
from tensorflow.examples.tutorials.mnist import input_data
mnist= input_data.read_data_sets('MNIST_data/', one_hot=True)
# 为了便于读取,我们把数据集先各自使用一个变量指向它们
x_train, y_train= mnist.train.images, mnist.train.labels
x_valid, y_valid= mnist.validation.images, mnist.validation.labels
x_test, y_test= mnist.test.images, mnist.test.labels
print("训练集图像大小:{}".format(x_train.shape))
print("训练集标签大小:{}".format(y_train.shape))
print("验证集图像大小:{}".format(x_valid.shape))
print("验证集标签大小:{}".format(y_valid.shape))
print("测试集图像大小:{}".format(x_test.shape))
print("测试集标签大小:{}".format(y_test.shape))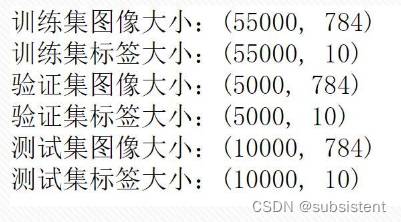
在训练神经网络模型前,需要预先设定参数,然后根据训练的情况来调整参数的值,本模型的参数如下:
# 图像的宽和高
img_size= 28 * 28
# 图像的10个类别,0~9
num_classes= 10
# 学习率
learning_rate= 1e-4
# 迭代次数
epochs = 10
# 每批次大小
batch_size= 100创建神经网络模型,使用卷积来添加网络模型中的隐藏层,这里添加两层卷积层,然后使用softmax多类别分类激活函数,配合交叉熵计算损失值,通过Adam来定义优化器。
1、准备数据占位符
# 定义输入占位符
x = tf.placeholder(tf.float32, shape=[None, img_size])
x_shaped= tf.reshape(x, [-1, 28, 28, 1])
# 定义输出占位符
y = tf.placeholder(tf.float32, shape=[None, num_classes])2、定义卷积函数。
卷积层的四个参数为:输入图像、权重、步长、填充。其中填充padding为SAME表示在移动窗口中,不够filter大小的数据就用0填充。
添加最大池化层,ksize值的形状是[batch,height,width,channels],步长strides值的形状是[batch,stride,stride,channels]。
# 定义卷积层
out_layer= tf.nn.conv2d(input_data, weights, (1, 1, 1, 1), padding="SAME")
out_layer+= bias
# 通过激活函数ReLU来计算输出
out_layer= tf.nn.relu(out_layer)
# 添加最大池化层
out_layer= tf.nn.max_pool(out_layer, ksize=(1, pool_shape[0], pool_shape[1], 1), strides=(1, 2, 2, 1), padding="SAME")3、添加第一层卷积网络,深度为32。
layer1 = create_conv2d(x_shaped, 1, 32, (5, 5), (2, 2), name="layer1")4、添加第二层卷积网络,深度为64
layer1 = create_conv2d(x_shaped, 1, 32, (5, 5), (2, 2), name="layer1")5、添加扁平化层,扁平化为一个大向量
flattened = tf.reshape(layer2, (-1, 7 * 7 * 64))6、添加全连接层
wd1 = tf.Variable(tf.truncated_normal((7 * 7 * 64, 1000), stddev=0.03), name="wd1")
bd1 = tf.Variable(tf.truncated_normal([1000], stddev=0.01), name="bd1")
dense_layer1 = tf.add(tf.matmul(flattened, wd1), bd1)
dense_layer1 = tf.nn.relu(dense_layer1)7、添加输出全连接层,深度为10,因为只需要10个类别
wd2 = tf.Variable(tf.truncated_normal((1000, num_classes), stddev=0.03), name="wd2")
bd2 = tf.Variable(tf.truncated_normal([num_classes], stddev=0.01), name="bd2")
dense_layer2 = tf.add(tf.matmul(dense_layer1, wd2), bd2)8、添加激活函数的softmax输出层,通过softmax交叉熵定义计算损失值,定义的优化器是Adam。
y_ = tf.nn.softmax(dense_layer2)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y_, labels=y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)9、比较正确的预测结果,计算预测的精确度。变量correct_prediction保存的值都是True或False之后,通过tf.cast函数将True转换成1,False转换成0,最后通过tf.reduce_mean计算元素的均值。
correct_prediction= tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))训练完本模型后,需要通过模型来预测测试集数据,所以此处使用tf.train.Saver()来保存模型的最佳检查点,模型会保存在checkpoints目录下,名称是mnist_cnn_tf.ckpt.
# 要迭代epochs次训练
for e in range(epochs):
# 对每张图像进行训练
for batch_iin range(batch_count):
# 每次取出batch_size张图像
batch_x, batch_y= mnist.train.next_batch(batch_size=batch_size)
# 训练模型
_, loss = sess.run([optimizer, cost], feed_dict={x: batch_x, y: batch_y})
# 每训练20次图像时打印一次日志信息,也就是20次乘以batch_size个图像已经被训练了
if batch_i% 20 == 0:
print("Epoch: {}/{}".format(e+1, epochs), "Iteration: {}".format(iteration), "Training loss: {:.5f}".format(loss))
iteration += 1
# 每迭代一次时,做一次验证,并打印日志信息
if iteration % batch_size== 0:
valid_acc= sess.run(accuracy, feed_dict={x: x_valid, y: y_valid})
print("Epoch: {}/{}".format(e, epochs),"Iteration: {}".format(iteration),"Validation Accuracy: {:.5f}".format(valid_acc))在每批次大小设置为50、迭代次数设置为10次时,总共训练次数为55000 / 50 * 10 = 11000 次,大约需要5分钟训练完毕,过程日志输出如下。从日志可以观察到损失值逐渐减小,精度逐渐变大,最后可达到0.98。

需要对测试数据集的样本进行预测,得到精确度。在预测前,先通过tf.train.Saver()读取训练时的模型检查点checkpoint,具体代码如下。从输出结果可知模型的精确度为0.983。
# 预测测试数据集
saver = tf.train.Saver()
with tf.Session() as sess:
# 从TensorFlow会话中恢复之前保存的模型检查点
saver.restore(sess, tf.train.latest_checkpoint('checkpoints/'))
# 通过测试集预测精确度
test_acc= sess.run(accuracy, feed_dict={x: x_test, y: y_test})
print("test accuracy: {:.5f}".format(test_acc))
本实验介绍了基于卷积神经网络(CNN)的TensorFlow实现对MNIST数据的识别,在训练的过程中计算并输出训练损失值,每迭代一次做一次验证,打印日志信息。训练完毕后,训练损失值从2.30降到1.46,而精度也从0.11提升到0.98。
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码