
目录
一、引言
二、零样本文本分类(zero-shot-classification)
2.1 概述
2.2 Facebook/bart-large-mnli
2.3 pipeline参数
2.3.1 pipeline对象实例化参数
2.3.2 pipeline对象使用参数
2.3.3 pipeline返回参数
2.4 pipeline实战
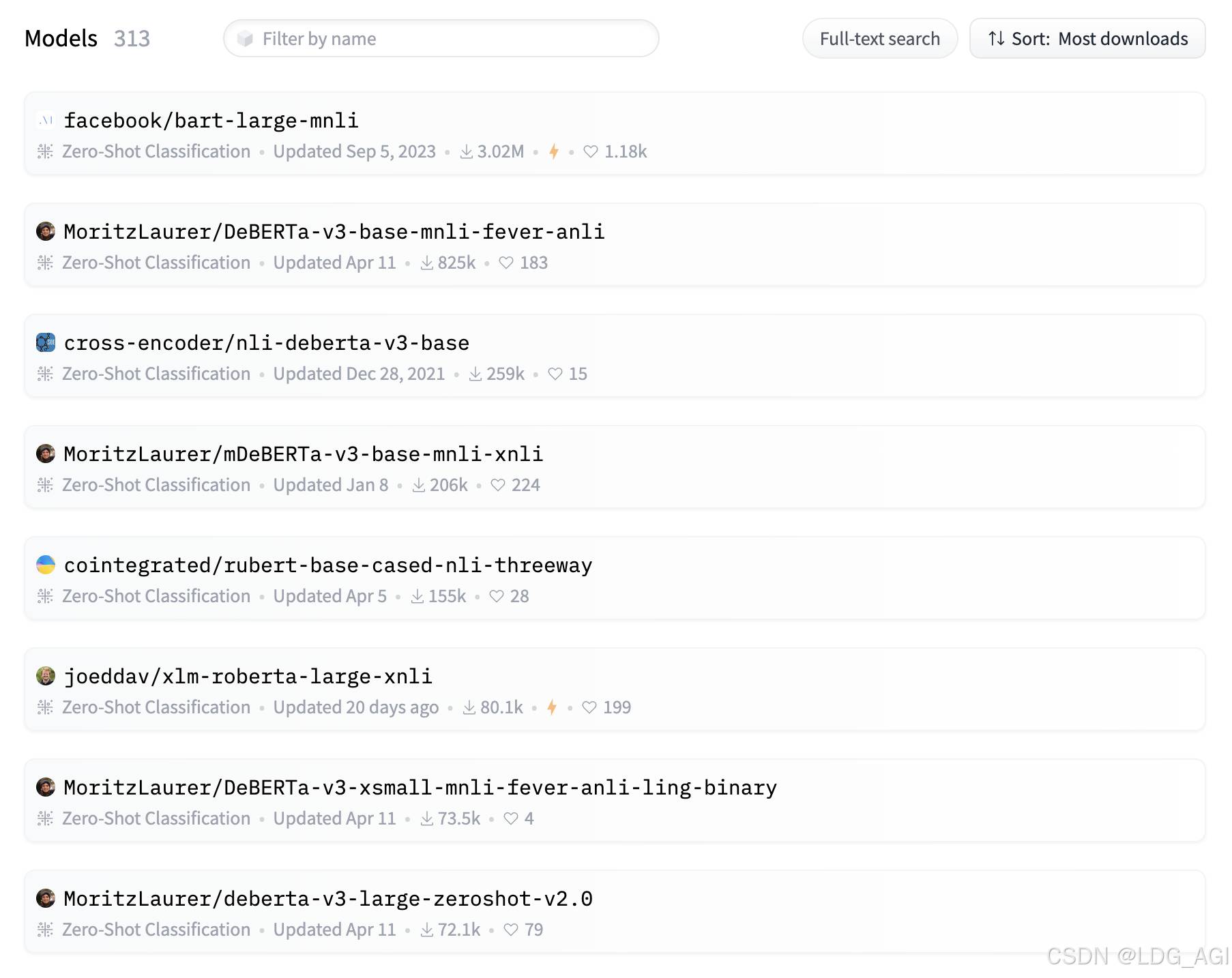
2.5 模型排名
三、总结
pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(Audio)、计算机视觉(Computer vision)、自然语言处理(NLP)、多模态(Multimodal)等4大类,28小类任务(tasks)。共计覆盖32万个模型
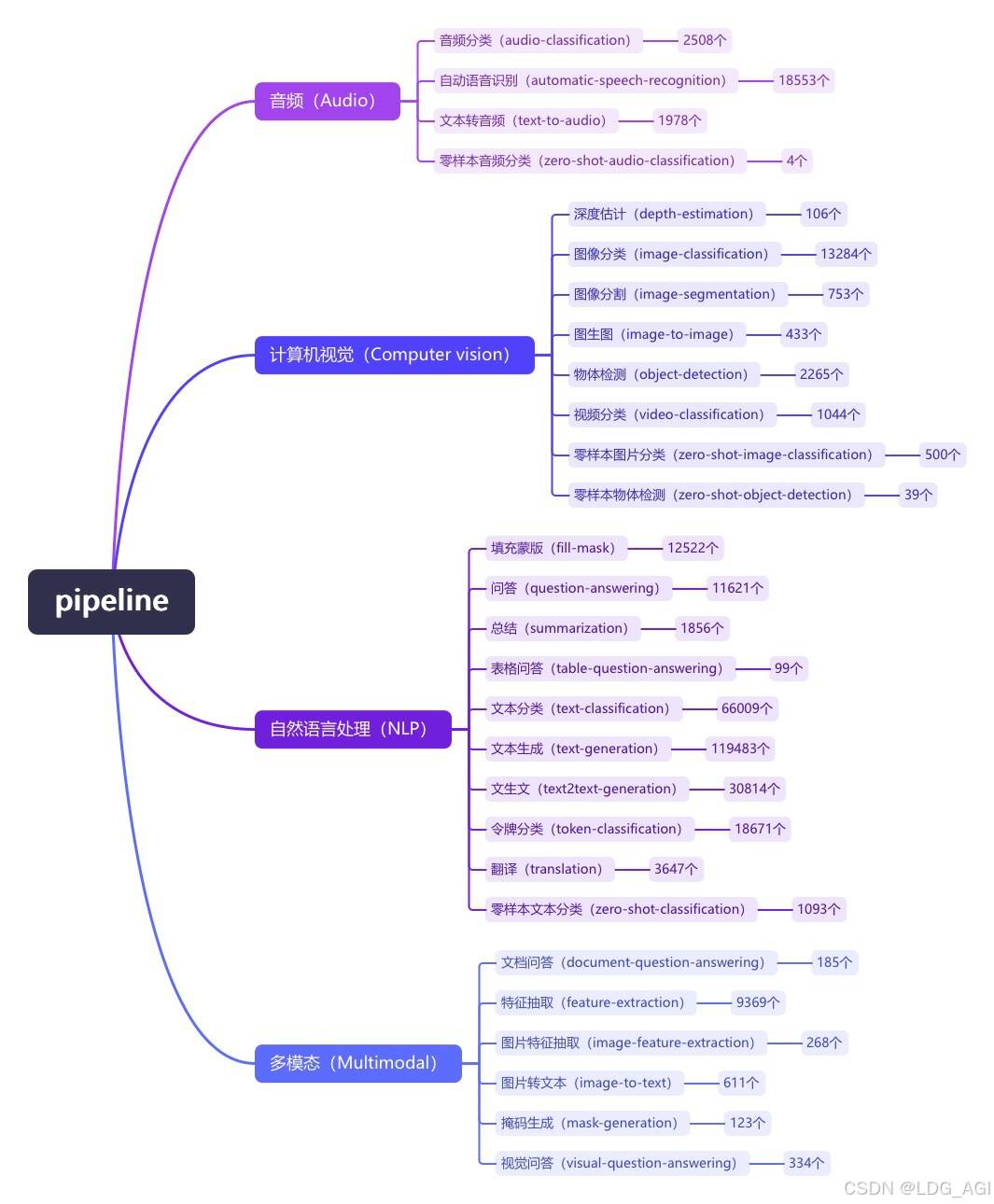
今天介绍NLP自然语言处理的第十篇:零样本文本分类(zero-shot-classification),在huggingface库内有313个零样本文本分类(zero-shot-classification)模型。
零样本文本分类是自然语言处理中的一项任务,其中模型在一组标记的示例上进行训练,但随后能够从以前看不见的类别中对新示例进行分类。
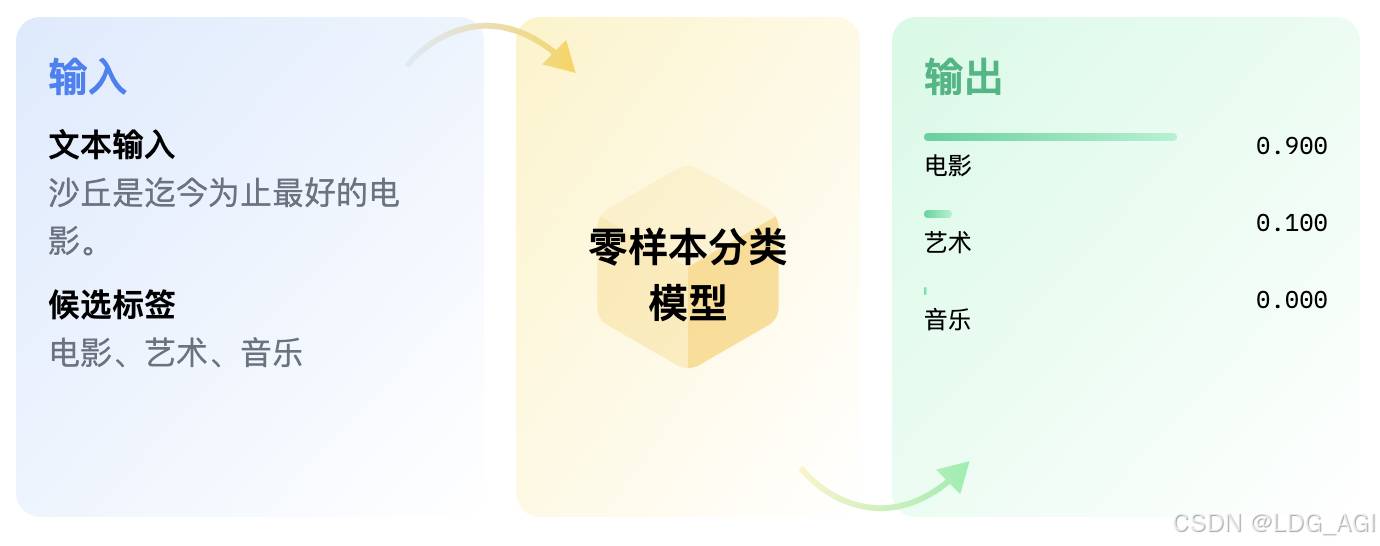
BART,一种用于预训练序列到序列模型的去噪自动编码器。BART 的训练方式是 (1) 使用任意噪声函数破坏文本,以及 (2) 学习模型以重建原始文本。它使用基于标准 Tranformer 的神经机器翻译架构,尽管它很简单,但可以看作是 BERT(由于双向编码器)、GPT(使用从左到右的解码器)和许多其他较新的预训练方案的泛化。
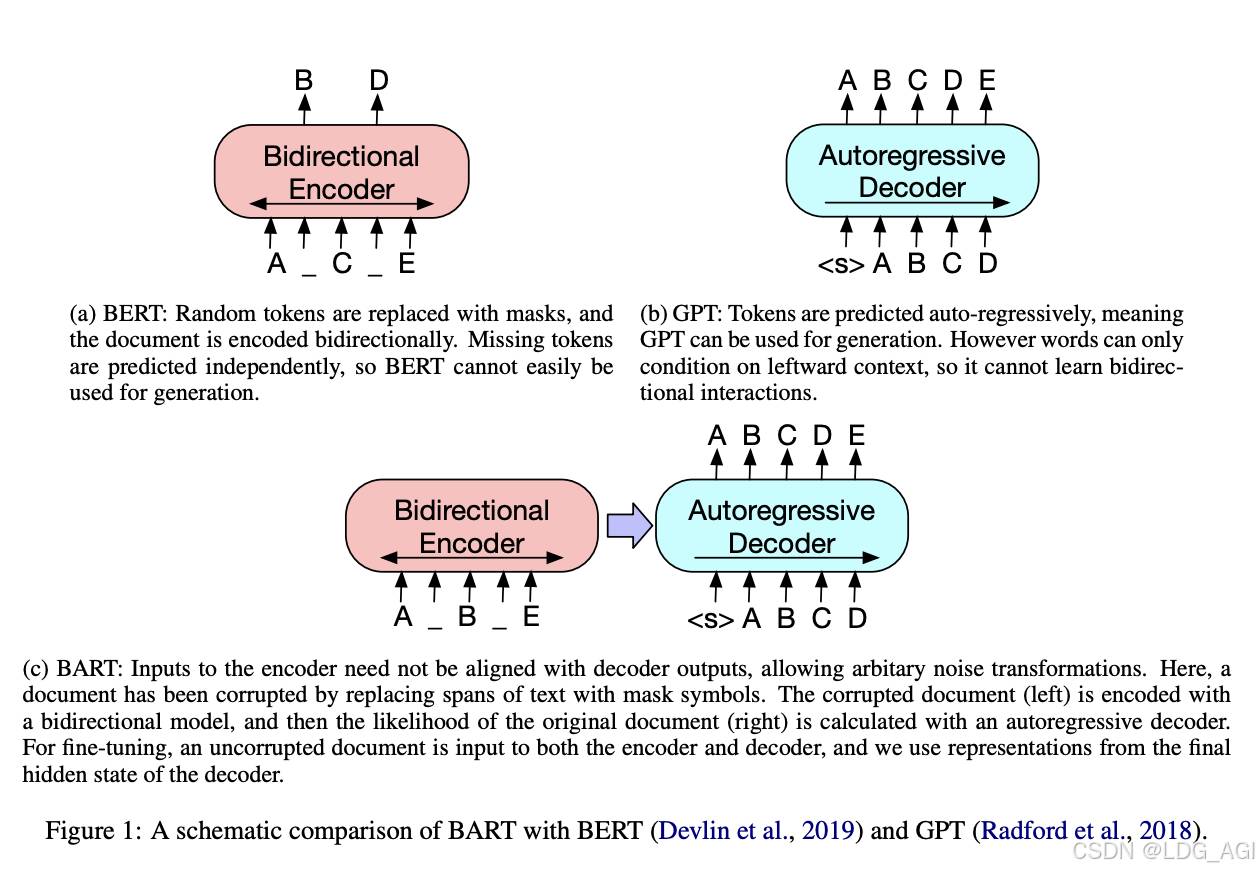
- GPT是一种Auto-Regressive(自回归)的语言模型。它也可以看作是Transformer model的Decoder部分,它的优化目标就是标准的语言模型目标:序列中所有token的联合概率。GPT采用的是自然序列中的从左到右(或者从右到左)的因式分解。
- BERT是一种Auto-Encoding(自编码)的语言模型。它也可以看作是Transformer model的Encoder部分,在输入端随机使用一种特殊的[MASK]token来替换序列中的token,这也可以看作是一种noise,所以BERT也叫Masked Language Model。
- BART吸收了BERT的bidirectional encoder和GPT的left-to-right decoder各自的特点,建立在标准的seq2seq Transformer model的基础之上,这使得它比BERT更适合文本生成的场景;相比GPT,也多了双向上下文语境信息。
- model(PreTrainedModel或TFPreTrainedModel)— 管道将使用其进行预测的模型。 对于 PyTorch,这需要从PreTrainedModel继承;对于 TensorFlow,这需要从TFPreTrainedModel继承。
- tokenizer ( PreTrainedTokenizer ) — 管道将使用其对模型的数据进行编码的 tokenizer。此对象继承自 PreTrainedTokenizer。
- modelcard(
str或ModelCard,可选) — 属于此管道模型的模型卡。- framework(
str,可选)— 要使用的框架,"pt"适用于 PyTorch 或"tf"TensorFlow。必须安装指定的框架。- task(
str,默认为"")— 管道的任务标识符。- num_workers(
int,可选,默认为 8)— 当管道将使用DataLoader(传递数据集时,在 Pytorch 模型的 GPU 上)时,要使用的工作者数量。- batch_size(
int,可选,默认为 1)— 当管道将使用DataLoader(传递数据集时,在 Pytorch 模型的 GPU 上)时,要使用的批次的大小,对于推理来说,这并不总是有益的,请阅读使用管道进行批处理。- args_parser(ArgumentHandler,可选) - 引用负责解析提供的管道参数的对象。
- device(
int,可选,默认为 -1)— CPU/GPU 支持的设备序号。将其设置为 -1 将利用 CPU,设置为正数将在关联的 CUDA 设备 ID 上运行模型。您可以传递本机torch.device或str太- torch_dtype(
str或torch.dtype,可选) - 直接发送model_kwargs(只是一种更简单的快捷方式)以使用此模型的可用精度(torch.float16,,torch.bfloat16...或"auto")- binary_output(
bool,可选,默认为False)——标志指示管道的输出是否应以序列化格式(即 pickle)或原始输出数据(例如文本)进行。
- sequences(
str或List[str])——如果模型输入太大,则要分类的序列将被截断。- candidates_labels(
str或List[str])— 用于将每个序列归类的可能的类标签集。可以是单个标签、逗号分隔的标签字符串或标签列表。- hypothesis_template(
str,可选,默认为"This example is {}.") — 用于将每个标签转换为 NLI 样式假设的模板。此模板必须包含 {} 或类似语法,以便将候选标签插入到模板中。例如,默认模板是 ,"This example is {}."使用候选标签"sports",它将像 一样输入到模型中"<cls> sequence to classify <sep> This example is sports . <sep>"。默认模板在许多情况下效果很好,但根据任务设置尝试使用不同的模板可能是值得的。- multi_label(
bool,可选,默认为False)— 多个候选标签是否可以为真。如果为False,则对分数进行归一化,使得每个序列的标签似然度之和为 1。如果为True,则将标签视为独立,并通过对蕴涵分数与矛盾分数进行 softmax 来对每个候选的概率进行归一化。
- sequence(
str) — 这是输出的序列。- labels(
List[str])——按可能性排序的标签。- scores(
List[float])——每个标签的概率。
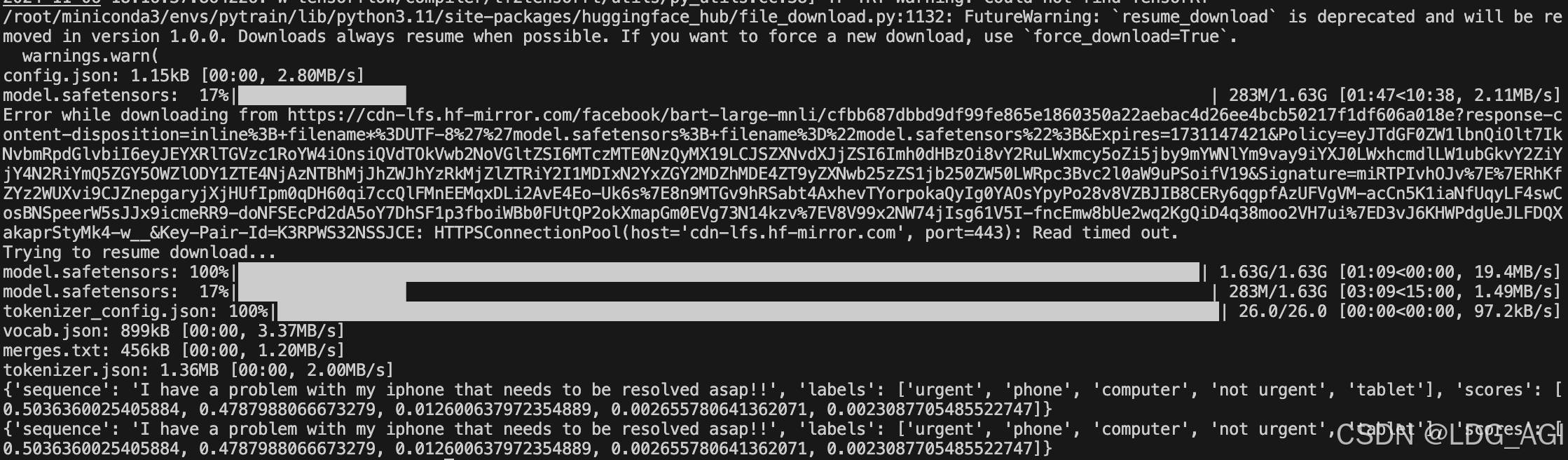
基于pipeline的zero-shot-classification任务,采用bart-large-mnli进行零样本文本分类,代码如下:
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
oracle = pipeline(model="facebook/bart-large-mnli")
output=oracle(
"I have a problem with my iphone that needs to be resolved asap!!",
candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
)
print(output)
oracle(
"I have a problem with my iphone that needs to be resolved asap!!",
candidate_labels=["english", "german"],
)
print(output)执行后,自动下载模型文件并进行识别:
在huggingface上,我们将零样本分类(zero-shot-classification)模型按下载量从高到低排序,总计313个模型,文中facebook的bart排名第一。
本文对transformers之pipeline的零样本文本分类(zero-shot-classification)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用NLP中的零样本文本分类(zero-shot-classification)模型。
期待您的3连+关注,如何还有时间,欢迎阅读我的其他文章:
《Transformers-Pipeline概述》
【人工智能】Transformers之Pipeline(概述):30w+大模型极简应用
《Transformers-Pipeline 第一章:音频(Audio)篇》
【人工智能】Transformers之Pipeline(一):音频分类(audio-classification)
【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)
【人工智能】Transformers之Pipeline(三):文本转音频(text-to-audio/text-to-speech)
【人工智能】Transformers之Pipeline(四):零样本音频分类(zero-shot-audio-classification)
《Transformers-Pipeline 第二章:计算机视觉(CV)篇》
【人工智能】Transformers之Pipeline(五):深度估计(depth-estimation)
【人工智能】Transformers之Pipeline(六):图像分类(image-classification)
【人工智能】Transformers之Pipeline(七):图像分割(image-segmentation)
【人工智能】Transformers之Pipeline(八):图生图(image-to-image)
【人工智能】Transformers之Pipeline(九):物体检测(object-detection)
【人工智能】Transformers之Pipeline(十):视频分类(video-classification)
【人工智能】Transformers之Pipeline(十一):零样本图片分类(zero-shot-image-classification)
【人工智能】Transformers之Pipeline(十二):零样本物体检测(zero-shot-object-detection)
《Transformers-Pipeline 第三章:自然语言处理(NLP)篇》
【人工智能】Transformers之Pipeline(十三):填充蒙版(fill-mask)
【人工智能】Transformers之Pipeline(十四):问答(question-answering)
【人工智能】Transformers之Pipeline(十五):总结(summarization)
【人工智能】Transformers之Pipeline(十六):表格问答(table-question-answering)
【人工智能】Transformers之Pipeline(十七):文本分类(text-classification)
【人工智能】Transformers之Pipeline(十八):文本生成(text-generation)
【人工智能】Transformers之Pipeline(十九):文生文(text2text-generation)
【人工智能】Transformers之Pipeline(二十):令牌分类(token-classification)
【人工智能】Transformers之Pipeline(二十一):翻译(translation)
【人工智能】Transformers之Pipeline(二十二):零样本文本分类(zero-shot-classification)
《Transformers-Pipeline 第四章:多模态(Multimodal)篇》
【人工智能】Transformers之Pipeline(二十三):文档问答(document-question-answering)
【人工智能】Transformers之Pipeline(二十四):特征抽取(feature-extraction)
【人工智能】Transformers之Pipeline(二十五):图片特征抽取(image-feature-extraction)
【人工智能】Transformers之Pipeline(二十六):图片转文本(image-to-text)
【人工智能】Transformers之Pipeline(二十七):掩码生成(mask-generation)
【人工智能】Transformers之Pipeline(二十八):视觉问答(visual-question-answering)
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码