在人工智能领域,我们一直在追求让机器像人类一样思考。然而,即使是最先进的AI,也常常被诟病缺乏“常识”,难以理解复杂问题,更不用说像人类一样进行逻辑推理和解决问题了。最经常的表现就是遇到不会的地方,或者一些人一眼能看出来的地方AI在那里胡扯。
为了解决这个问题,一种名为“思维链(Chain of Thought, COT)”的技术应运而生。COT的核心思想是:将复杂问题分解成一系列简单的子问题,并逐步推理出最终答案。 这就像人类在解决问题时,会先将问题拆解成一个个小步骤,然后一步步推理,最终得出结论。
为了理解COT我们先来看个例子。经典的数strawberry里面的r有几个
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# 模型
model = ChatOpenAI(
model='deepseek-chat',
openai_api_key='sk-xxx',
openai_api_base='https://api.deepseek.com',
max_tokens=4096
)
# 定义一个简单的提示模板
prompt_template = PromptTemplate(
input_variables=["user_input"],
template="用户: {user_input}\nAI:"
)
# 创建一个链,将提示模板与模型连接起来
chain = LLMChain(llm=model, prompt=prompt_template)
# 手动输入一个值并发送给模型
user_input = "strawberry里面有几个r"
# 发送消息给模型并获取响应
response = chain.run(user_input=user_input)
print(f"\n\nAI: {response}\n")
我们得到的结果是比较糟糕的:
AI: 在单词 "strawberry" 中,有两个字母 "r"。

我们开始试着加入cot,让他进行问题的拆解,在进行回答试一下:
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# 模型
model = ChatOpenAI(
model='deepseek-chat',
openai_api_key='sk-xxx',
openai_api_base='https://api.deepseek.com',
max_tokens=4096
)
# 定义一个简单的提示模板
prompt_template = PromptTemplate(
input_variables=["user_input"],
template="用户: {user_input}\nAI:"
)
# 创建一个链,将提示模板与模型连接起来
chain = LLMChain(llm=model, prompt=prompt_template)
# 手动输入一个值并发送给模型
user_input = '''
回答下面问题并注意回答的时候严格按照以下步骤,逐步进行:
1.将单词拆开
2.从左到右一个,一个对比字母是不是,是的话你要记录他的位置,并记住数量加一
3,第2步数出来多少个r直接输出
问题:'strawberry'里面有几个r
'''
# 发送消息给模型并获取响应
response = chain.run(user_input=user_input)
print(f"\n\nAI: {response}\n")
结果很好,llm按照我们的思路去进行了单词拆解,并得到了正确的答案。
AI: 1. 将单词拆开: s, t, r, a, w, b, e, r, r, y
2. 从左到右一个,一个对比字母是不是r:
- 第1个字母是s,不是r
- 第2个字母是t,不是r
- 第3个字母是r,是r,记录位置3,数量加一
- 第4个字母是a,不是r
- 第5个字母是w,不是r
- 第6个字母是b,不是r
- 第7个字母是e,不是r
- 第8个字母是r,是r,记录位置8,数量加一
- 第9个字母是r,是r,记录位置9,数量加一
- 第10个字母是y,不是r
3. 第2步数出来多少个r直接输出: 3

上面提到的例子是我们引导llm解决某个具体的例子,但如果我们不知道用户想问什么,但是又想内置思维链怎么办呢?尝试下像我一样写
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
import json
# 模型
model = ChatOpenAI(
model='deepseek-chat',
openai_api_key='sk-xxx',
openai_api_base='https://api.deepseek.com',
max_tokens=4096
)
# 定义一个简单的提示模板
prompt_template = PromptTemplate(
input_variables=["user_input"],
template="用户: {user_input}\nAI:"
)
# 创建一个链,将提示模板与模型连接起来
chain = LLMChain(llm=model, prompt=prompt_template)
# 手动输入一个值并发送给模型
initial_prompt = '''
你是一个能够逐步解释推理过程的专家AI助手。对于每一步,提供一个描述你在该步骤中所做内容的标题,以及相应的内容。决定是否需要另一步骤或你已准备好给出最终答案,
,且每次推理你仅执行一步等我说继续才能执行下一步。输出以JSON格式响应,包含 ‘title’, ‘content’, 和 ‘next_action’(要么是 ‘continue’,要么是 ‘final_answer’)键值。
为了提高指令遵从性,通过大写字母强调指令的重要性,包括一组提示和最佳实践:
1、尽可能多地使用推理步骤。至少5步,且每次推理你仅执行一步等我说继续才能执行下一步
2、意识到作为语言模型你的限制以及你能做什么和不能做什么。
3、包括探索替代答案。考虑你可能是错误的,如果你的推理是错误的,错误可能在哪里。
4、当你说你在重新检查时,实际上要重新检查,并采用另一种方法来做。不要只是说你在重新检查。
5、至少使用3种方法得出答案。
6、使用最佳实践。
问题如下:周五昨天的后天是周几
'''
# 发送消息给模型并获取响应
response = chain.run(user_input=initial_prompt)
print(f"\n\nAI: {response}\n")
# 清理响应内容,去掉 ```json 和 ```标记
response = response.strip('```json').strip('```').strip()
# 解析初始响应
response_json = json.loads(response)
history = [response_json]
# 循环直到 next_action 为 final_answer
while response_json['next_action'] != 'final_answer':
# 更新用户输入,带上历史记录和初始提示词
user_input = f"{initial_prompt}\n{json.dumps(history)}\n,继续你的下一步推理Z:"
# 发送消息给模型并获取响应
response = chain.run(user_input=user_input)
print(f"\n\nAI: {response}\n")
# 清理响应内容,去掉 ```json 和 ```标记
response = response.strip('```json').strip('```').strip()
# 解析响应
response_json = json.loads(response)
history.append(response_json)
# 确保我们访问的是列表的第一个元素
if isinstance(response_json, list):
response_json = response_json[0]
这样我们就将思维链内置好了,llm可以自己去决定问题拆解或停止思考进行回答。
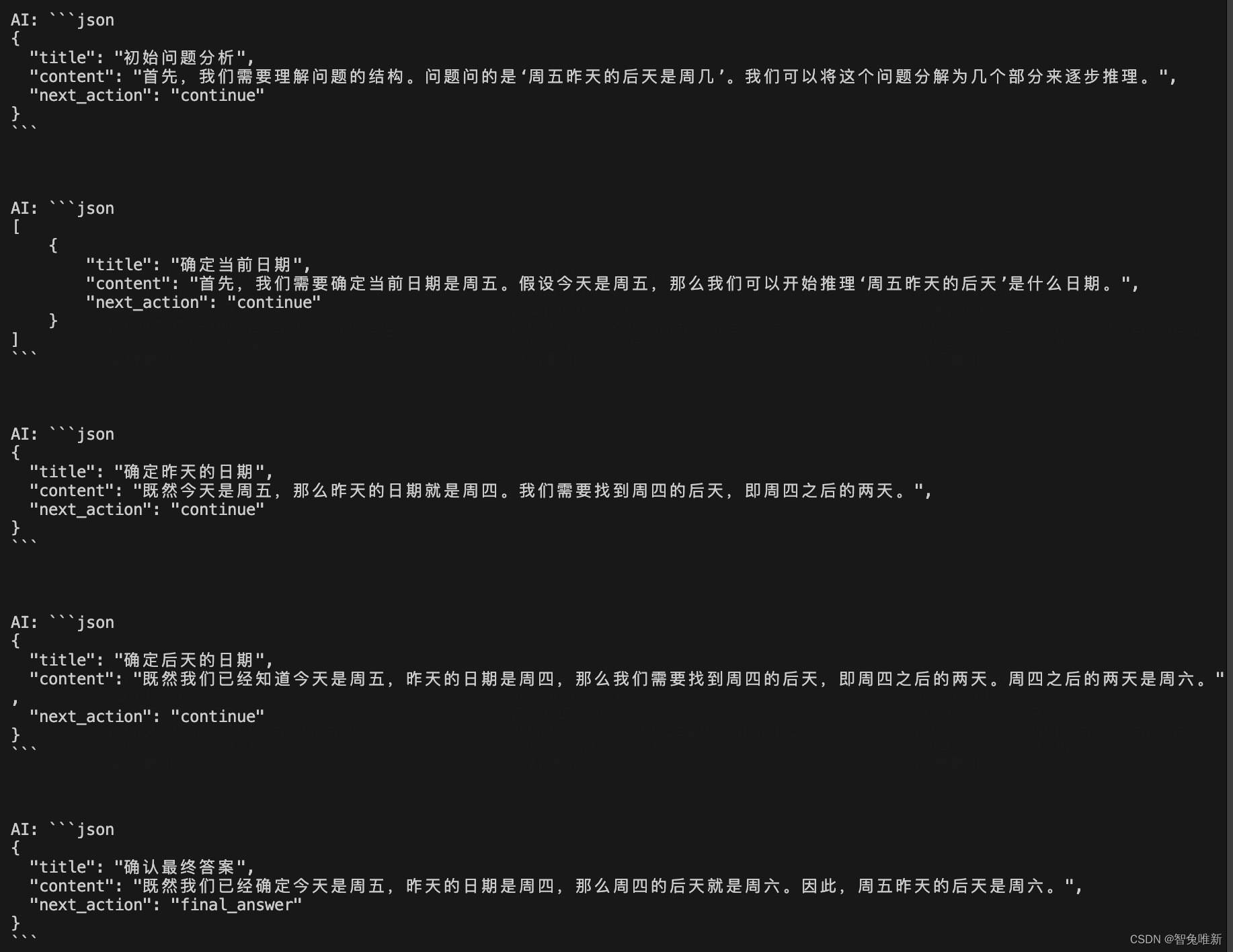
可以看到结果是非常好的,cot对于这种需要多步推理的问题效果尤其的好。
COT作为一种新兴的技术,目前还处于发展初期,但其潜力巨大。未来,随着技术的不断进步,COT有望在以下几个方面取得突破:
更强大的推理能力: 未来的COT模型将能够处理更加复杂、抽象的问题,并进行更加深入的推理。
更强的可解释性: 未来的COT模型将能够提供更加清晰、易懂的推理过程,使得人类可以更好地理解和信任AI的决策。
更广泛的应用场景: 未来的COT模型将能够应用于更多的领域,例如医疗诊断、法律咨询、金融分析等。
COT思维链的出现,为AI的发展开辟了一条新的道路。它让AI学会了像人类一样思考,将复杂问题分解成简单的步骤,并逐步推理出最终答案。希望我的引导会对你产生启发。关于非编码版可查看思维链COT优化Prompt
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码