前言:
通过前篇《人工智能AI→计算机视觉→机器视觉→深度学习→在ImageNet有限小样本数据集中学习深度模型的识别任务实践》我们可以学到如何对实际生活、工作场景中的字符识别、人脸识别、图像类别进行识别的基于深度学习方法的技术路径实现具体包括:准备数据集制作、创建深度学习网络模型、训练网络模型和保存模型文件、模型测试评估、模型识别数据统计分析,这个开发过程值得熟悉,后续我们基于工程实践的应用开发大多用到,区别之处在于不同应用场景采用模型相应适配和相应数据集的制作即可,必要时候进行模型的主体框架设计、参数设置、或者改进以满足实际应用需求。
在这里我们多做进一步阐述:工程实践的应用场景中识别目标任务,好比是数学场景中的函数求解概念;那么同理前者的<识别类别结果> 等于<深度学习网络模型>在<场景数据集>中的求解,即类比于数学概念<求解值域>等于<数学函数>在<定义域>中的求解;而我们知道函数中的值域是函数在特定定义域才有意义的,脱离定义域谈函数值域无意义,因为相同的函数不同的定义域对应的值域也是不尽相同的。所以我们说到值域就强调是函数在那个具体的定义域里面的值域;同样道理我们说到一个模型的识别结果同样应该想到这个是那个深度学习网络模型在特定的那个场景数据集的识别结果,如果脱离具体应用场景讲模型识别结果是没有意义的,因为同样的网络模型<即函数>在不同的应用场景的数据集<即定义域>其识别结果<即值域>也是不尽相同的。所以我们在工作、生活学习中往往听到说那个模型识别率多少,怎么有的识别数据很可观有的却一般,虽然都是同一型号的网络模型,那就是说具体的应用场景数据集不同使然;所以当听到说识别率多少先不要盲目做判断,我们首先就应该先想到具体对应的场景及其数据集是怎样的,在好的应用场景数据集上识别效果会很客观,在一些苛刻的应用场景数据集上识别效果可能会很一般的客观工程实践情况。这样定义域和函数值域的匹配关系,识别效果和网络模型的数据集的对应关系,用其数学理论进一步阐述了。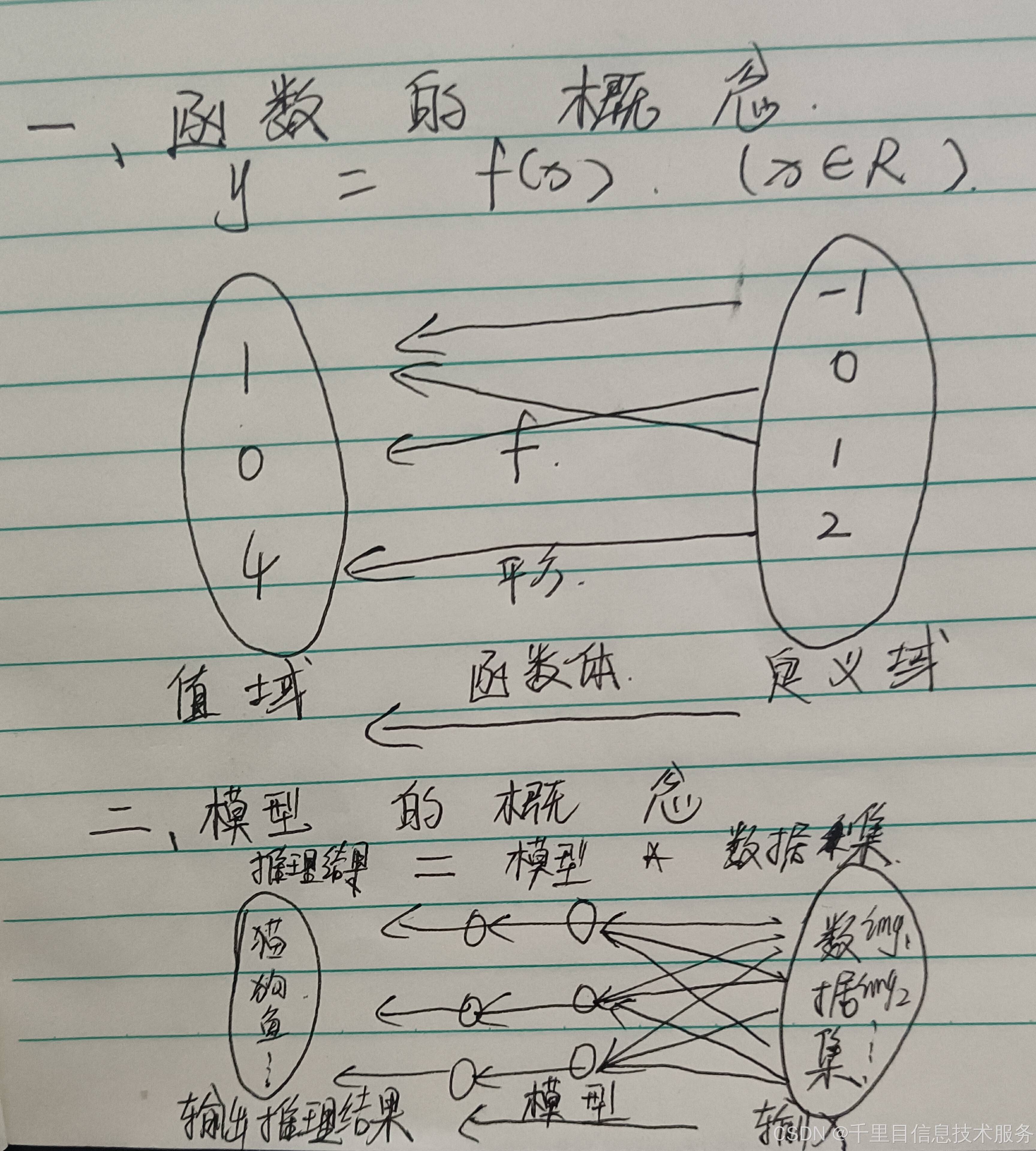
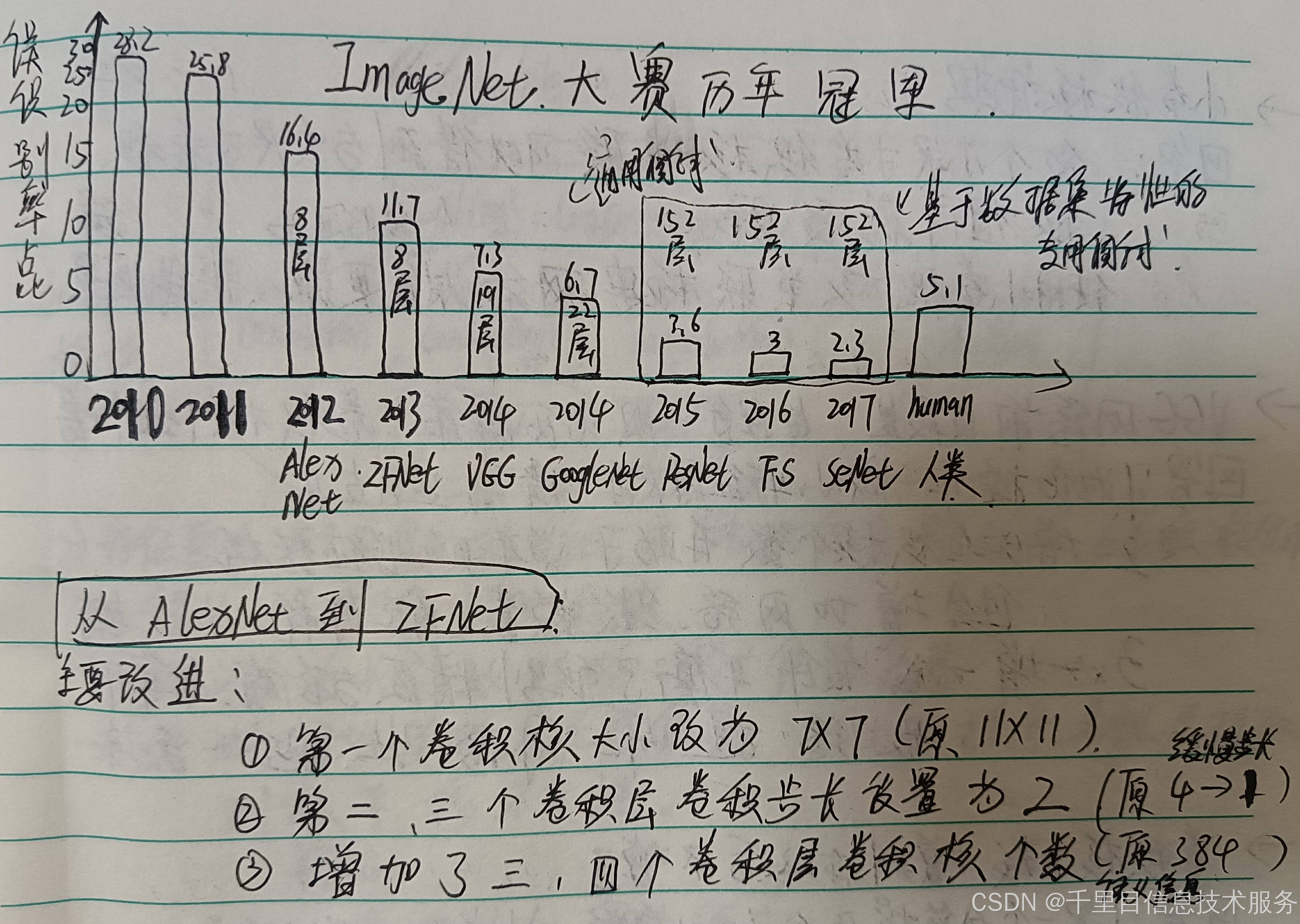
初入该领域的专业同学、工程师、技术工作者、研究人员、或者相关领域涉及这块的从业者可能会听到很多关于深度学习模型及结构的名称的描述词汇、例如LeNet、AlexNet、ZFNet、VGG、GoogleNet、ResNet、FS、SeNet、CNN、RNN、BP、Inception、Transformer,诸多的命名深度学习网络模型是否有种不知从而入手的感觉,那么该帖子《人工智能AI→计算机视觉→机器视觉→深度学习→在ImageNet有限小样本数据集中学习深度模型的识别任务实践二》实践二就我们一起来探明究竟这类模型的结构相同点以及演进后的创新点,并且这样改进的原因和效果,从而通过关键的模型研究洞悉其本质结构特点,从而为后续再接触到新的模型也能够掌握分析其结构和识别效果的评估依据,从而有对其的认知:模型是什么、能用来做那块应用、模型识别的效果能够什么程度;而这就是我们今天学习的任务目标。
1、LeNet模型简介
前篇我们讲述了操作流程,如果我们期望在特定应用场景改进我们模型实现更好的识别效果,那么可在创建深度学习网络模型这块进行研究和钻研,其次是制作数据集层面算力是支撑。那我们就从LeNet→AlexNet→ZFNet→VGG→GoogleNet→ResNet→FS→SeNet开始讲解模型的构成和改进那些点有怎样的识别效果。借鉴我们之前帖子中描述模型AlexNet的方式,描述LeNet其结构原理图及程序实现。
大家可能会说已经学过了AlexNet(2012),为什么还要往回再学LeNet(1987年研究卷积神经网络,1989年首次提出LeNet网络模型雏形,1998年发表LeNet-5论文应用于实践得到验证,真正意义上的卷积神经网络)网络结构呢:原因有两点①LeNet是由LeCun杨立昆等人提出于1998年提出的一种用于手写体字符识别的非常高效的卷积神经网络。当年美国大多数银行和邮局就是用它来识别支票和信封上面的手写数字的。它的识别准确性非常高,并且模型简洁,其开创性的采用了卷积操作来实现特征提取,也是后续各大神经网络的伊始!在2018年,LeCun与Geoffrey Hinton(2024年诺贝尔物理奖获得者,正是其团队的AlexNet网络模型在ImageNet2012获得冠军)和Yoshua Bengio一起获得了图灵奖(被称为“计算机界的诺贝尔奖”),因为他们在深度学习方面的贡献,他们三人有时被称为“深度学习三巨头”。② LeNet在深度学习和卷积神经网络领域是“0—1”的开创性基础研究贡献,而AlexNet属于在此基础上“1—N”的创新突破将原来仅限于手写字符识别的应用扩展到其他更多图像识别领域并且成功率显著提升。从LeNet到Alexnet模型简洁改进明确易于说明清楚和理解,后面更多深层的网络改进原理都可以参考此类方法,具有通识性。
2、LeNet模型结构解析:
LeNet:也称Lenet-5,共5个隐藏层(2个卷积层和3个全连接层,最后一个全链接层为输出层)。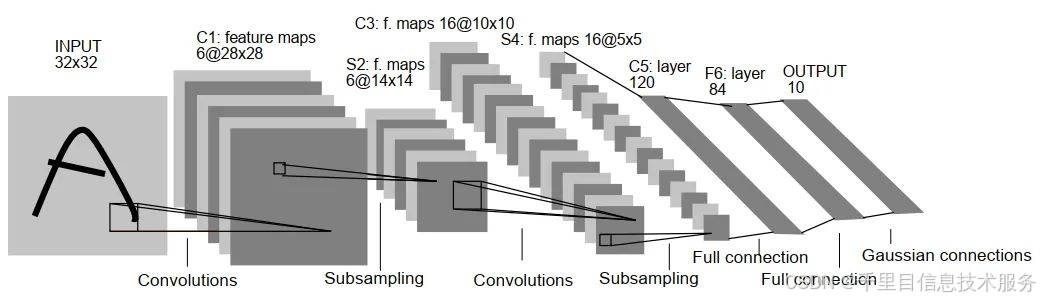
这里我们卷积用C表示,池化用S表示,全连接用FC表示,本工程实践中LeNet网络模型结构为两块:
①初始化init模块网络层设置:input(33232)→C1(3,16,5)→S(2,2)→C2(16,32,5)→S(2,2)→FC1(3255,120)→FC2(120,84)→FC3(84,10)
②forward前向传递模块数据流向:input→C1→reLu激活→S→C2→reLu激活→S→flattern→FC1→reLu激活→FC2→reLu激活→FC3(输出层classNum)
3、LeNet网络模型程序搭建:
程序实现放在文件里:本系列博客中涉及到的模型构建程序都放在文件里,调用相应的模型只需要找到对应模型的调用,然后训练时和推理预测时只需要找到创建工程的和做简单参数设置适配即可,在前篇程序实践部分都有完整源码参考到,后续该系列模型使用讲解都可适用:
#程序开始
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
#卷积C1输入3*32*32,卷积核5*5,输出16特征值
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=5)
#池化S参数设置
self.pool1 = nn.MaxPool2d(2, 2)
#卷积C2层参数设置
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32,kernel_size= 5)
#池化层S参数设置
self.pool2 = nn.MaxPool2d(2, 2)
#全连接层参数设置
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
#前向网络设置,数据流向,卷积、激活、池化连续叠加两次,然后全连接、激活叠加两次,x.view一层,最后输出全连接层就是输出层sofmax
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)#卷积C1、激活relu。输入输出的计算公式参考附图。
x = self.pool1(x) # output(16, 14, 14)#池化
x = F.relu(self.conv2(x)) # output(32, 10, 10)#卷积C2、激活relu
x = self.pool2(x) # output(32, 5, 5)#池化
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)#全连接FC1,激活relu
x = F.relu(self.fc2(x)) # output(84)#全连接FC2,激活relu
x = self.fc3(x) # output(10)#全连接输出层
return x
##程序完成
程序中涉及到如何计算input(3,32,32)图像数据时,如何按照前面设置参数计算该层卷积的输出有相应的计算公式如图所示:

4、LeNet网络模型和ALexNet网络模型的相同点和不同点
通过对LeNet网络结构和程序实现的学习,让我们再结合之前学到的Alexnet网络模型结构和程序实现对比分析我们发现了一些在深度学习领域较为普遍的模型搭建的技巧和原理:
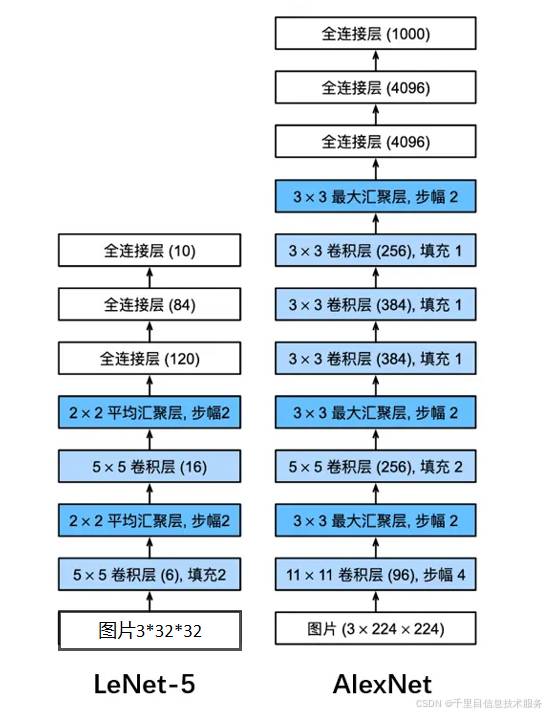
总结采用的实践二中两款模型的区别:相同点和不同点
①LeNet模型和AlexNet模型都是基于卷积、池化、激活函数、前向传递等这些个通用的基础科学原理的积木/轮子模块通过排列、组合、叠
加等的方式组建起来的网络模型,我们学习到这一步也先暂且不去考虑卷积、池化、激活等这些具体积木/轮子里面到底怎样的数学公式和
原理,先侧重知道其在模型中的功能即可,重点跟着脚步梳理出来我们这个模型的整体组成结构,并且熟悉这些结构组成和相互之间的异
同之处。
②ALexNet在LeNet基础上的区别:a、LeNet5层网络模型,Alexnet8层网络,网络层数深度增加,通道数增加,卷积核尺寸设置
b、激活函数采用ReLU函数,减少梯度消失现象,和之前采用的sigmoid相比更有利于训练深层网络模型
c、使用Dropout抑制过拟合(算法模型比数据模型复杂)
d、数据增广,随机加一些预处理方法平移缩放裁剪旋转、翻转或者增减亮度等,扩大训练数据集复杂度
e、使用GPU训练,增强计算能力,重叠池化层缓解过拟合
后记:
到目前为止我们已经完成了开创型卷积神经网络LeNet(1988)和在此基础上应用扩展创新型深度网络模型AlexNet(2012)两款早期具有代表性的深度学习网络模型的结构组成、原理简介、程序实践。大家是否会和笔者一样产生一些感悟:从LeNet(1988)到AlexNet(2012)早起的两款模型的改进从网络层数的5→8层,以及激活函数选用ReLU,采用Dropout等方法防止过拟合等,其实模型本身的改进变动是微小的,但是产生的应用识别效果却是很显著的;而这微小的改进得到大众所认知却是ImageNet2012年在图像识别赛事中正确率远远提升获得冠军后才为众人所看到,用了从1988年到2012年有24年时间的沉淀积累摸索发展才实现的(而且要知道仅仅是LeNet演进的过程:1987年开始研究卷积神经网络CNN,从1989年首次提出网络模型雏形LeNet到不断调试应用于实践并且于1998发表LeNet-5版本网络模型的论文都用了10年时间)。深度学习网络模型的改进是一方面,另一方面借助于ImageNet大规模数据集的学习素材实现了数据集数据量保证,同时同时期能够实现的计算能力的保证,在这三个领域的共同前进发展基础上从而使得ALexNet图像识别效果被发掘。从中也告诉我们在科学技术前进的道路上那些为众人道的伟大的成绩往往都是很好的吸收了前人的知识积累,在此基础上做出来的科学合理的微小的创新从而实现进一步的成绩。 正是有了LeNet和ALexNet开创性的贡献,引出了后续诸多应用和基础领域通用和专用有效的深度学习模型:ZFNet→VGG→GoogleNet→ResNet→FS→SeNet及MobileNet、EfficientNet等,这也是我们续篇应用实践学习的重点,并且真正意义上拓宽了网络模型的深度到更深的量级,正式开启了深度学习网络模型富有创造力的大模型时代。
参考资料:
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码