
🌟个人主页:落叶
🌟当前专栏:机器学习专栏
目录
线性回归(Linear Regression)
基本概念
数学模型
优缺点
利用Python实现线性回归
逻辑回归(Logistic Regression)
3.2. 数学模型
优缺点
Python实现逻辑回归
支持向量机(Support Vector Machine, SVM)
基本概念
4.2. 数学模型
4.3. 优缺点
Python实现向量机
决策树(Decision Tree)
. 基本概念
5.2. 数学模型
5.3. 优缺点
随机森林(Random Forest)
基本概念
6.2. 数学模型
6.3. 优缺点
代码解释
7.1. 数据生成与预处理
7.2. 模型训练与评估
8. 总结
完整代码
摘要:监督学习(Supervised Learning)是机器学习的重要组成部分,旨在通过学习带有标签的训练数据来构建预测模型。本文将深入探讨五种经典的监督学习算法:线性回归(Linear Regression)、逻辑回归(Logistic Regression)、支持向量机(Support Vector Machine, SVM)、决策树(Decision Tree)和随机森林(Random Forest)。每种算法都将从基本概念、数学原理、优缺点以及Python代码实现等方面进行详细讲解,并通过实际案例帮助读者更好地理解这些算法的工作原理和应用场景。
监督学习是机器学习的一个核心领域,其目标是学习输入特征(特征变量)与输出标签(目标变量)之间的映射关系,以便对新的、未标记的数据进行准确的预测或分类。监督学习主要分为两类任务:
- 回归问题:预测连续型目标变量,如房价预测、股票价格预测等。
- 分类问题:预测离散型目标变量,如垃圾邮件识别、图像分类等。
本文将详细介绍五种经典的监督学习算法:线性回归、逻辑回归、支持向量机、决策树和随机森林。每种算法都将从基本概念、数学原理、优缺点以及Python代码实现等方面进行详细讲解,并通过实际案例帮助读者更好地理解这些算法的工作原理和应用场景。
线性回归是监督学习中用于处理回归问题的一种基本算法。它通过线性组合输入特征来预测目标变量的连续值。线性回归假设目标变量与输入特征之间存在线性关系。
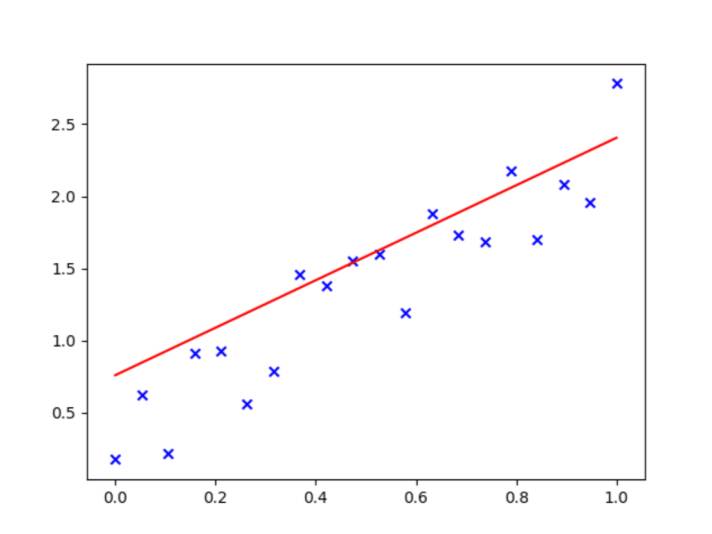
- 线性模型:
- 目标:最小化预测值与真实值之间的误差。常用的损失函数是均方误差(Mean Squared Error, MSE):
- 优化算法:使用最小二乘法(Ordinary Least Squares, OLS)或梯度下降法(Gradient Descent)来求解模型参数。
优点:
- 模型简单,易于理解和解释。
- 计算效率高,适用于大规模数据集。
- 适用于线性可分的数据。
缺点:
- 只能处理线性关系,对非线性关系效果不佳。
- 对异常值敏感。
- 容易欠拟合。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV, RandomizedSearchCV
from sklearn.linear_model import Ridge, Lasso
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
# 生成示例数据
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义参数范围
param_grid = {'alpha': [0.1, 1.0, 10.0, 100.0]}
# 网格搜索Ridge回归
ridge = Ridge()
grid_search = GridSearchCV(ridge, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳交叉验证得分: {grid_search.best_score_}")
# 预测
y_pred_ridge = grid_search.predict(X_test)
# 评估
mse_ridge = mean_squared_error(y_test, y_pred_ridge)
r2_ridge = r2_score(y_test, y_pred_ridge)
print(f"Ridge回归均方误差: {mse_ridge}")
print(f"Ridge回归R^2得分: {r2_ridge}")
# 随机搜索Lasso回归
param_dist = {'alpha': np.logspace(-4, 0, 50)}
lasso = Lasso()
random_search = RandomizedSearchCV(lasso, param_distributions=param_dist, n_iter=20, cv=5, random_state=42, scoring='neg_mean_squared_error')
random_search.fit(X_train, y_train)
print(f"最佳参数: {random_search.best_params_}")
print(f"最佳交叉验证得分: {random_search.best_score_}")
# 预测
y_pred_lasso = random_search.predict(X_test)
# 评估
mse_lasso = mean_squared_error(y_test, y_pred_lasso)
r2_lasso = r2_score(y_test, y_pred_lasso)
print(f"Lasso回归均方误差: {mse_lasso}")
print(f"Lasso回归R^2得分: {r2_lasso}")逻辑回归是一种用于分类问题的线性模型,主要用于处理二分类问题。它通过线性组合输入特征,并使用逻辑函数(Sigmoid函数)将线性输出映射到一个概率值,表示样本属于某一类别的可能性。
线性组合:
Sigmoid函数:
损失函数(交叉熵损失):
优化算法:梯度下降法
优点:
- 模型简单,易于理解和解释。
- 计算效率高,适用于大规模数据集。
- 可以输出概率值,方便进行概率解释和阈值调整。
缺点:
- 只能处理线性可分问题,对非线性问题效果不佳。
- 对异常值和多重共线性敏感。
- 容易欠拟合或过拟合,需要进行正则化处理。
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, accuracy_score
# 定义参数范围
param_grid = {'C': [0.01, 0.1, 1.0, 10.0, 100.0],
'penalty': ['l1', 'l2']}
# 网格搜索逻辑回归
log_reg = LogisticRegression(solver='liblinear')
grid_search_log = GridSearchCV(log_reg, param_grid, cv=5, scoring='accuracy')
grid_search_log.fit(X_train, y_train)
print(f"最佳参数: {grid_search_log.best_params_}")
print(f"最佳交叉验证得分: {grid_search_log.best_score_}")
# 预测
y_pred_log = grid_search_log.predict(X_test)
# 评估
print("逻辑回归分类报告:")
print(classification_report(y_test, y_pred_log))
print(f"准确率: {accuracy_score(y_test, y_pred_log)}")d)}")
支持向量机是一种用于分类和回归的监督学习算法。对于二分类问题,SVM通过寻找一个最佳的超平面将不同类别的样本分开,并最大化类别之间的间隔。
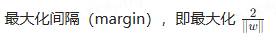
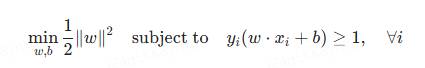
优点:
- 在高维空间中表现良好。
- 使用核函数可以处理非线性可分问题。
- 适用于小样本数据集。
缺点:
- 对参数和核函数的选择敏感。
- 计算复杂度高,尤其是大规模数据集。
from sklearn.tree import DecisionTreeClassifier
# 定义参数范围
param_grid_tree = {'max_depth': [3, 5, 7, 9, None],
'criterion': ['gini', 'entropy'],
'min_samples_split': [2, 5, 10]}
# 网格搜索决策树
tree = DecisionTreeClassifier(random_state=42)
grid_search_tree = GridSearchCV(tree, param_grid_tree, cv=5, scoring='accuracy')
grid_search_tree.fit(X_train, y_train)
print(f"最佳参数: {grid_search_tree.best_params_}")
print(f"最佳交叉验证得分: {grid_search_tree.best_score_}")
# 预测
y_pred_tree = grid_search_tree.predict(X_test)
# 评估
print("决策树分类报告:")
print(classification_report(y_test, y_pred_tree))
print(f"决策树准确率: {accuracy_score(y_test, y_pred_tree)}")决策树是一种用于分类和回归的模型。它通过递归地分割数据集,构建一个树状结构,每个节点表示一个特征上的测试,每个分支表示测试的结果,最终的叶子节点表示类别或预测值。
优点:
- 模型易于理解和解释。
- 不需要特征缩放。
- 可以处理非线性关系。
缺点:
- 容易过拟合,尤其是树深度较大时。
- 对数据中的噪声和异常值敏感。
- 不稳定,数据变化可能导致树结构变化。
from sklearn.tree import DecisionTreeClassifier
# 定义参数范围
param_grid_tree = {'max_depth': [3, 5, 7, 9, None],
'criterion': ['gini', 'entropy'],
'min_samples_split': [2, 5, 10]}
# 网格搜索决策树
tree = DecisionTreeClassifier(random_state=42)
grid_search_tree = GridSearchCV(tree, param_grid_tree, cv=5, scoring='accuracy')
grid_search_tree.fit(X_train, y_train)
print(f"最佳参数: {grid_search_tree.best_params_}")
print(f"最佳交叉验证得分: {grid_search_tree.best_score_}")
# 预测
y_pred_tree = grid_search_tree.predict(X_test)
# 评估
print("决策树分类报告:")
print(classification_report(y_test, y_pred_tree))
print(f"决策树准确率: {accuracy_score(y_test, y_pred_tree)}")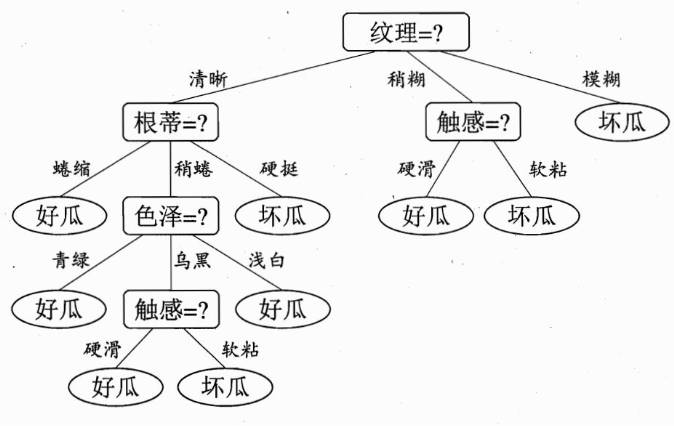
上面的图片可以直观的表达决策树的逻辑。选择好瓜的时候,我们首先要判断一个西瓜的纹理,如果纹理很模糊,那么这个挂一定是坏瓜;如果这个瓜的纹理稍微模糊,就去判断这个西瓜的触感怎么样。如果这个瓜的纹理比较清晰,那么接下来我们可以通过观察这个瓜的各个部分比如根蒂、色泽以及触感去一步一步判断一个瓜的好坏。这个就是决策树在分类问题中非常典型的例子。当决策树用于回归问题的时候,每个叶子节点就是一个一个实数值。
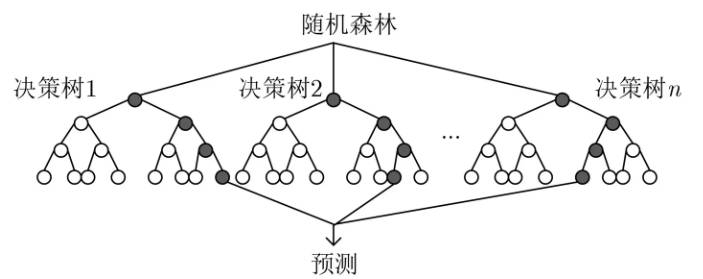
随机森林是一种集成学习算法,它通过构建多个决策树并结合它们的预测结果来提高模型的准确性和鲁棒性。
优点:
- 有效防止过拟合。
- 鲁棒性强,对噪声和异常值不敏感。
- 适用于大规模数据集。
缺点:
- 模型复杂度高,训练时间长。
- 难以解释,尤其是树的数量较多时。
from sklearn.ensemble import RandomForestClassifier
# 定义参数范围
param_grid_forest = {'n_estimators': [50, 100, 200],
'max_depth': [3, 5, 7, 9, None],
'criterion': ['gini', 'entropy']}
# 网格搜索随机森林
forest = RandomForestClassifier(random_state=42)
grid_search_forest = GridSearchCV(forest, param_grid_forest, cv=5, scoring='accuracy')
grid_search_forest.fit(X_train, y_train)
print(f"最佳参数: {grid_search_forest.best_params_}")
print(f"最佳交叉验证得分: {grid_search_forest.best_score_}")
# 预测
y_pred_forest = grid_search_forest.predict(X_test)
# 评估
print("随机森林分类报告:")
print(classification_report(y_test, y_pred_forest))
print(f"随机森林准确率: {accuracy_score(y_test, y_pred_forest)}")线性回归:
- 生成100个样本,每个样本有一个特征。
- 使用线性模型生成目标变量,并添加随机噪声。
- 分割数据集为训练集和测试集。
- 训练线性回归模型,并评估模型性能。
逻辑回归、SVM、决策树、随机森林:
- 使用鸢尾花数据集(Iris dataset)进行二分类。
- 分割数据集为训练集和测试集。
- 标准化处理。
- 训练模型,并评估模型性能。
线性回归:
- 使用
LinearRegression类训练模型。- 评估指标包括均方误差(MSE)和R^2得分。
逻辑回归、SVM、决策树、随机森林:
- 使用
LogisticRegression、SVC、DecisionTreeClassifier、RandomForestClassifier类训练模型。- 评估指标包括分类报告和准确率。
本文详细介绍了五种经典的监督学习算法:线性回归、逻辑回归、支持向量机、决策树和随机森林。每种算法都有其独特的优势和适用场景:
- 线性回归适用于回归问题,模型简单且易于解释。
- 逻辑回归适用于二分类问题,模型简单且易于解释。
- 支持向量机在处理高维数据和非线性可分问题时表现出色。
- 决策树易于理解和解释,但容易过拟合。
- 随机森林通过集成多个决策树,提高了模型的准确性和鲁棒性。
通过理解这些算法的基本概念、数学原理和实现方法,可以更好地应用机器学习技术解决实际问题。
以下是完整的Python代码实现:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import mean_squared_error, r2_score, classification_report, accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
# 线性回归示例
# 生成示例数据
np.random.seed(42)
X_lin = 2 * np.random.rand(100, 1)
y_lin = 4 + 3 * X_lin + np.random.randn(100, 1)
# 分割数据集
X_train_lin, X_test_lin, y_train_lin, y_test_lin = train_test_split(X_lin, y_lin, test_size=0.2, random_state=42)
# 训练线性回归模型
model_lin = LinearRegression()
model_lin.fit(X_train_lin, y_train_lin)
# 预测
y_pred_lin = model_lin.predict(X_test_lin)
# 评估
mse_lin = mean_squared_error(y_test_lin, y_pred_lin)
r2_lin = r2_score(y_test_lin, y_pred_lin)
print("线性回归评估:")
print(f"均方误差: {mse_lin}")
print(f"R^2得分: {r2_lin}")
# 可视化
plt.scatter(X_test_lin, y_test_lin, color='blue', label='真实值')
plt.scatter(X_test_lin, y_pred_lin, color='red', label='预测值')
plt.xlabel('特征')
plt.ylabel('目标')
plt.title('线性回归预测结果')
plt.legend()
plt.show()
# 逻辑回归示例
# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 选择两个类别进行二分类
binary_class_mask = y < 2
X = X[binary_class_mask]
y = y[binary_class_mask]
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 训练逻辑回归模型
model_log = LogisticRegression()
model_log.fit(X_train, y_train)
# 预测
y_pred_log = model_log.predict(X_test)
# 评估
print("逻辑回归评估:")
print(classification_report(y_test, y_pred_log))
print(f"准确率: {accuracy_score(y_test, y_pred_log)}")
# 支持向量机示例
# 训练SVM模型
model_svm = SVC(kernel='linear', C=1.0)
model_svm.fit(X_train, y_train)
# 预测
y_pred_svm = model_svm.predict(X_test)
# 评估
print("SVM评估:")
print(classification_report(y_test, y_pred_svm))
print(f"SVM准确率: {accuracy_score(y_test, y_pred_svm)}")
# 决策树示例
# 训练决策树模型
model_tree = DecisionTreeClassifier(random_state=42)
model_tree.fit(X_train, y_train)
# 预测
y_pred_tree = model_tree.predict(X_test)
# 评估
print("决策树评估:")
print(classification_report(y_test, y_pred_tree))
print(f"决策树准确率: {accuracy_score(y_test, y_pred_tree)}")
# 随机森林示例
# 训练随机森林模型
model_for版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码