目录
一、了解CUDA与cuDNN
二、安装CUDA
1. 查看显卡型号与驱动版本(Driver Version)
2. 下载CUDA
3.安装CUDA
4. 验证CUDA是否安装完成
三、安装cuDNN
1.下载cuDNN
2.安装cuDNN
后记:关于cuda v11.6之后版本Samples的编译运行(以v11.8为例)
一、编译与运行
二、文件夹内容简介
20241015记:这几年,大模型的兴起,打开了新时代的大门,想要在这个时代快速地成长和生存,利用好AI进行辅助学习显然已经成为一种大趋势,我们应该抓住一切能加速自己成长的机会,国内的文心一言,豆包等,国外的大模型Chatgpt、Claude等,无一不可以辅助自己编程的学习,这里给大家推荐一个我自己在用的整合Chagpt和Claude的网站(国内可用,站点稳定):传送门
抓住AI时代每一个机会,加速自己成长,提高自己的核心竞争力与自身价值!
为了方便下次找到文章,也方便联系我给大家提供帮助,欢迎大家点赞👍、收藏📂和关注🔔!一起讨论技术问题💻,一起学习成长📚!如果你有任何问题或想法,随时留言,我会尽快回复哦😊!
本篇文章将详细从如何安装CUDA与cuDNN开始,到基本配置结束,帮助大家理清配置流程,文章最后,我将附上我的博客中其他有关CUDA的文章,欢迎大家阅读。
CUDA(Compute Unified Device Architecture)是NVIDIA开发的并行计算平台和编程模型,用于利用NVIDIA GPU的并行计算能力,它允许开发者使用类似于C语言的编程语言编写并行程序,利用GPU的大规模并行计算能力加速各种类型的应用程序,包括科学计算、深度学习、图形渲染等,并提供了一套丰富的API和工具,使开发者能够方便地利用GPU加速计算,包括核心的CUDA Runtime API、CUDA Driver API以及各种辅助工具和库。
cuDNN(CUDA Deep Neural Network library)是NVIDIA专门针对深度学习应用开发的GPU加速库。它提供了一系列高效的深度学习算法的实现,包括卷积神经网络(CNN)、循环神经网络(RNN)等常用网络结构的基本操作,如卷积、池化、归一化、激活函数等。cuDNN针对NVIDIA GPU进行了高度优化,利用GPU的并行计算能力加速深度学习模型的训练和推理过程。通过使用cuDNN,开发者可以轻松地将深度学习模型部署到支持CUDA的NVIDIA GPU上,并获得显著的性能提升。
总的来说,CUDA提供了通用的并行计算平台和编程模型,而cuDNN则是针对深度学习应用进行了优化的GPU加速库,二者结合起来可以实现高效的深度学习模型训练和推理。
①打开终端(win+R输入cmd),输入
nvidia-smi--显卡型号:NVIDIA GeForce RTX 4060
--驱动版本:532.10
大家要了解的是:
1)驱动版本决定了CUDA版本,驱动版本越高,则可安装的CUDA版本越高
2)CUDA向下兼容,我这里是输出的CUDA版本为12.1,并不是意味着我的电脑只能安装12.1版本的CUDA,而是可以安装12.1及以下任何版本的CUDA
如果你想了解更多的驱动与CUDA之间的对应关系,可以查看官网:
CUDA 12.3 Update 2 Release Notes (nvidia.com)
TensorFlow与CUDA
在 Windows 环境中从源代码构建 | TensorFlow
Pytorch与CUDA
Previous PyTorch Versions | PyTorch
①Org Download WEB:
CUDA Toolkit Archive | NVIDIA Developer
②选择你将要安装的版本,我这里选择了11.6.0
在下述界面完成后,点击Download(2.4GB),等待下载完成
这里推荐IDM下载工具,下载速度很快
①双击安装程序
②直接点击【OK】即可,不必修改路径(如果你的C盘没有空间了,记得修改路径)
该窗口为暂时解压缩路径,一旦安装程序完成,该临时文件夹会被清理,但是,提取过程会占用文件夹的存储空间,需要足够的空间来存放解压后的文件。
点击【OK】后等待即可
③点击【同意并继续】
④选择【自定义】,点击【下一步】
⑤组件选择问题
1)Other components与Driver components
当前版本即为我的本地版本,新版本即为CUDA安装时将要替代版本
可以看到,我的版本均大于等于新版本,不必再勾选
如果你希望进行更新,那么你可以自行选择
2)CUDA
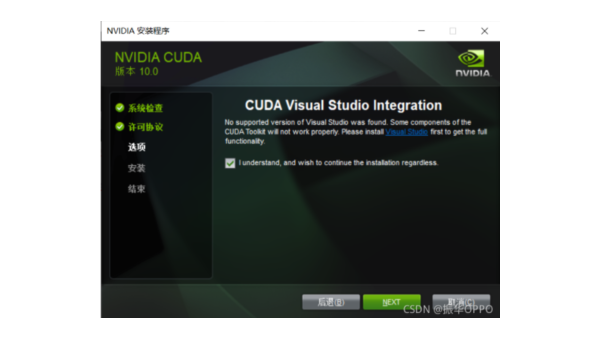
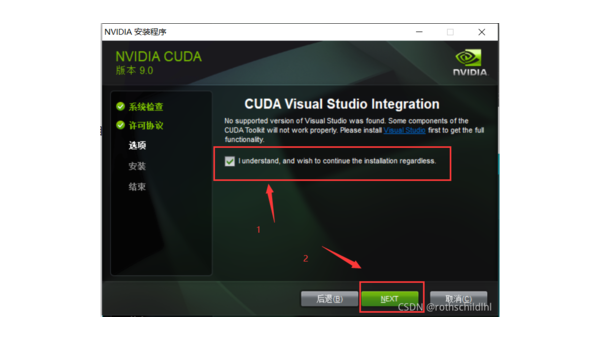
在这里,你可以看到Visual Studio Integration
如果你的设备上已经安装了VS,那么勾选上
反之,要取消勾选,否则在后续的安装过程会报错
2024/10/21记,注意:在cuda v11.6之后(v11.7开始),cuda Toolkits不再集成Samples文件夹,该文件夹中包含许多示例代码,对cuda的安装成功与否没有影响,感兴趣的读者请查阅文章最后部分,我将对Samples如何运行进行详细赘述。
⑥点击下一步,点击浏览修改安装位置,点击【下一步】
在另一个盘中新建目录结构如下(E:\Data_cuda中):
├─Data
│ └─NVIDIA Corporation
│ └─CUDA Samples
│ └─v11.6
└─Files
└─NVIDIA GPU Computing Toolkit
└─CUDA
└─v11.6
⑦等待安装
⑧点击下一步
⑨安装完成,点击【关闭】
在新打开的cmd窗口中输入:
nvcc -V如上图,即表示安装完成!
①Org Download WEB:
Log in | NVIDIA Developer
注意:需要提前注册账号才可以登录
②这里选择版本是注意for CUDA xx.x,如果你的CUDA是11版本就选11,12版本就选12
③点开后选择【Local Install for Windows】下载
④解压下载文件
文件结构如下:
①复制以下三个文件夹
②将文件夹粘贴至如下路径:
path to your cudaFolder/Files/NVIDIA GPU Computing Toolkit/CUDA/v11.6
3.验证cuDNN是否安装成功
①在下述文件夹右键,打开终端
path to your cudaFolder/Files/NVIDIA GPU Computing Toolkit/CUDA/v11.6/extras/demo_suite
②输入:
.\deviceQuery.exe得到PASS即代表安装成功
输入:
.\bandwidthTest.exe得到PASS即代表安装成功
转载请标明出处!
如果还有问题,欢迎在评论区留言或私信
作者:BQ
主页:bqcode.blog.csdn.net
qq群:958124241
Learn Together!
1.进行源码的下载
方法一:
①进入下述网址,点击Tag,切换至11.8
NVIDIA/cuda-samples at v11.8
②开始下载源码
方法二:
利用Git将该项目下载至本地,命令如下:
git clone --branch v11.8 --single-branch https://github.com/NVIDIA/cuda-samples.git我已将该项目放至网盘,网络不好的同学可在网盘下载:
点击获取链接地址
2.文件夹中可以看到三个“.sln”文件,使用对应的VS版本打开即可
等待项目加载:
加载完成后可以看到:
3.随便点进一个文件的某个项目,以4_CUDA_Libraries下的batchCUBLAS为例,进行以下步骤:
①在batchCUBLAS.cpp末尾处的exit(nTotalErrors == 0 ? EXIT_SUCCESS : EXIT_FAILURE);前一行添加:
system("pause");②右键batchCUBLAS,点击【生成】
可以看到,其生成的可执行文件(exe)放在了如下位置:
②进入该文件夹,双击该可执行文件,可以看到如下输出:
batchCUBLAS Starting...
GPU Device 0: "Ampere" with compute capability 8.6
==== Running single kernels ====
Testing sgemm
#### args: ta=0 tb=0 m=128 n=128 k=128 alpha = (0xbf800000, -1) beta= (0x40000000, 2)
#### args: lda=128 ldb=128 ldc=128
^^^^ elapsed = 0.00196190 sec GFLOPS=2.13788
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=128 n=128 k=128 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0)
#### args: lda=128 ldb=128 ldc=128
^^^^ elapsed = 0.00003720 sec GFLOPS=112.75
@@@@ dgemm test OK
==== Running N=10 without streams ====
Testing sgemm
#### args: ta=0 tb=0 m=128 n=128 k=128 alpha = (0xbf800000, -1) beta= (0x00000000, 0)
#### args: lda=128 ldb=128 ldc=128
^^^^ elapsed = 0.00008710 sec GFLOPS=481.55
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=128 n=128 k=128 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=128 ldb=128 ldc=128
^^^^ elapsed = 0.00068830 sec GFLOPS=60.9371
@@@@ dgemm test OK
==== Running N=10 with streams ====
Testing sgemm
#### args: ta=0 tb=0 m=128 n=128 k=128 alpha = (0x40000000, 2) beta= (0x40000000, 2)
#### args: lda=128 ldb=128 ldc=128
^^^^ elapsed = 0.00007860 sec GFLOPS=533.626
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=128 n=128 k=128 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=128 ldb=128 ldc=128
^^^^ elapsed = 0.00029690 sec GFLOPS=141.27
@@@@ dgemm test OK
==== Running N=10 batched ====
Testing sgemm
#### args: ta=0 tb=0 m=128 n=128 k=128 alpha = (0x3f800000, 1) beta= (0xbf800000, -1)
#### args: lda=128 ldb=128 ldc=128
^^^^ elapsed = 0.00016050 sec GFLOPS=261.327
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=128 n=128 k=128 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2)
#### args: lda=128 ldb=128 ldc=128
^^^^ elapsed = 0.00075190 sec GFLOPS=55.7827
@@@@ dgemm test OK
Test Summary
0 error(s)
请按任意键继续. . .至此,Samples手动编译并运行示例讲解结束,如有问题,可在评论去进行提问,或可加我的技术交流群,欢迎来访!
在每个文件夹中,存放各类项目,0-6分别存放的项目类型为:
0_Introduction:
1_Utilities:
2_Concepts_and_Techniques:
3_CUDA_Features:
4_CUDA_Libraries:
5_Domain_Specific:
6_Performance:
创作不易,欢迎大家订阅📮、点赞👍、收藏📂与关注🔔,你的鼓励和支持将是我创作的最大动力💪!
转载请注明出处
作者:BQ
主页:bqcode.blog.csdn.net
公众号:BQ经验书
Learn Together!
CUDA文章如下,点击链接直达:
【CUDA代码实践01】Clion配置远程Linux服务器实现CUDA编程_clion cuda-CSDN博客
【CUDA代码实践02】矩阵加法运算程序_cuda实现矩阵加法-CSDN博客
【CUDA代码实践03】m维网格n维线程块对二维矩阵的索引_二维线程·-CSDN博客
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码