NVIDIA NIM平台是一个专为AI推理设计的微服务套件,具有灵活的使用方式、优化的模型性能、广泛的适配范围和简化的开发流程等优势。它正在被广泛应用于各种AI推理场景,并得到了众多技术合作伙伴的支持和认可。
NVIDIA NIM平台是英伟达公司推出的一款重要的人工智能推理微服务平台。NVIDIA NIM,即NVIDIA推理微服务,是一个易于使用的微服务套件,专为AI推理设计。它的目的是加速生成式AI模型在云、数据中心和工作站上的部署,为开发者提供一个强大、可扩展且安全的平台。
NIM正在被广泛应用于各种AI推理场景,包括构建基本的聊天机器人、AI助手、检索增强生成(RAG)应用程序等。我们可以在自己的平台中集成NIM,以加速生成式AI的部署,这显示了NIM在业界的影响力和应用前景。同时,英伟达为开发者提供了丰富的资源和支持,包括文档、API参考信息和发行说明等,帮助开发者更好地使用NIM平台。
在打开的的页面点击右上角的 Login:
提供邮件,填写密码点击注册成功,如下:
在这个界面我们能看到多种基于 NIM 平台的AI模型,接下来我们将介绍其中之一的大语言模型,构建我们的知识问答系统。
因为需要跑AI相关的代码,是在python的环境下进行的,而服务器的环境刚好是ubuntu的,先安装一下python的环境:
apt-get update
apt-get install python3
apt-get install pip3
完装完成后,使用-V参数查看是否成功:

NVIDIA NIM 微服务作为优化容器提供,旨在加速各种规模的企业的 AI 应用开发,为 AI 技术的快速生产和部署铺平道路。这些微服务集可用于在语音 AI、数据检索、数字生物学、数字人、模拟和大型语言模型(LLMs)中构建和部署 AI 解决方案。
因为在项目中使用了不少python的库,所以,需要先将python的一些AI相关库安装好:
pip install langchain_nvidia_ai_endpoints langchain-community langchain-text-splitters faiss-cpu gradio==3.50.0 setuptools beautifulsoup4

在使用pip安装Python包时,可以指定使用不同的源,这样可以加速下载速度,特别是在一些源在国外的情况。要指定使用的源,可以通过修改pip的配置文件或者在安装命令中直接指定。
在上面的软修的安装完成后,然后我们把下面的代码复制粘贴到一开始创建的 Python 文件中,例如“nim_test.py”:
# -*- coding: utf-8 -*-
# 导入必要的库
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings, ChatNVIDIA
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import chain
import os
import gradio as gr
from datetime import datetime
# Even if you do not know the full answer, generate a one-paragraph hypothetical answer to the below question in Chinese
# 定义假设性回答模板
hyde_template = """Even if you do not know the full answer, generate a one-paragraph hypothetical answer to the below question:
{question}"""
# 定义最终回答模板
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
# 定义函数来处理问题
def process_question(url, api_key, model_name, question):
# 初始化加载器并加载数据
loader = WebBaseLoader(url)
docs = loader.load()
# 设置环境变量
os.environ['NVIDIA_API_KEY'] = api_key
# 初始化嵌入层
embeddings = NVIDIAEmbeddings()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)
retriever = vector.as_retriever()
# 初始化模型
model = ChatNVIDIA(model=model_name)
# 创建提示模板
hyde_prompt = ChatPromptTemplate.from_template(hyde_template)
hyde_query_transformer = hyde_prompt | model | StrOutputParser()
# 定义检索函数
@chain
def hyde_retriever(question):
hypothetical_document = hyde_query_transformer.invoke({"question": question})
return retriever.invoke(hypothetical_document)
# 定义最终回答链
prompt = ChatPromptTemplate.from_template(template)
answer_chain = prompt | model | StrOutputParser()
@chain
def final_chain(question):
documents = hyde_retriever.invoke(question)
response = ""
for s in answer_chain.stream({"question": question, "context": documents}):
response += s
return response
# 调用最终链获取答案
return str(datetime.now())+final_chain.invoke(question)
# 定义可用的模型列表
models = ["mistralai/mistral-7b-instruct-v0.2","meta/llama-3.1-405b-instruct"]
# 启动Gradio应用
iface = gr.Interface(
fn=process_question,
inputs=[
gr.Textbox(label="输入需要学习的网址"),
gr.Textbox(label="NVIDIA API Key"),
gr.Dropdown(models, label="选择语言模型"),
gr.Textbox(label="输入问题")
],
outputs="text",
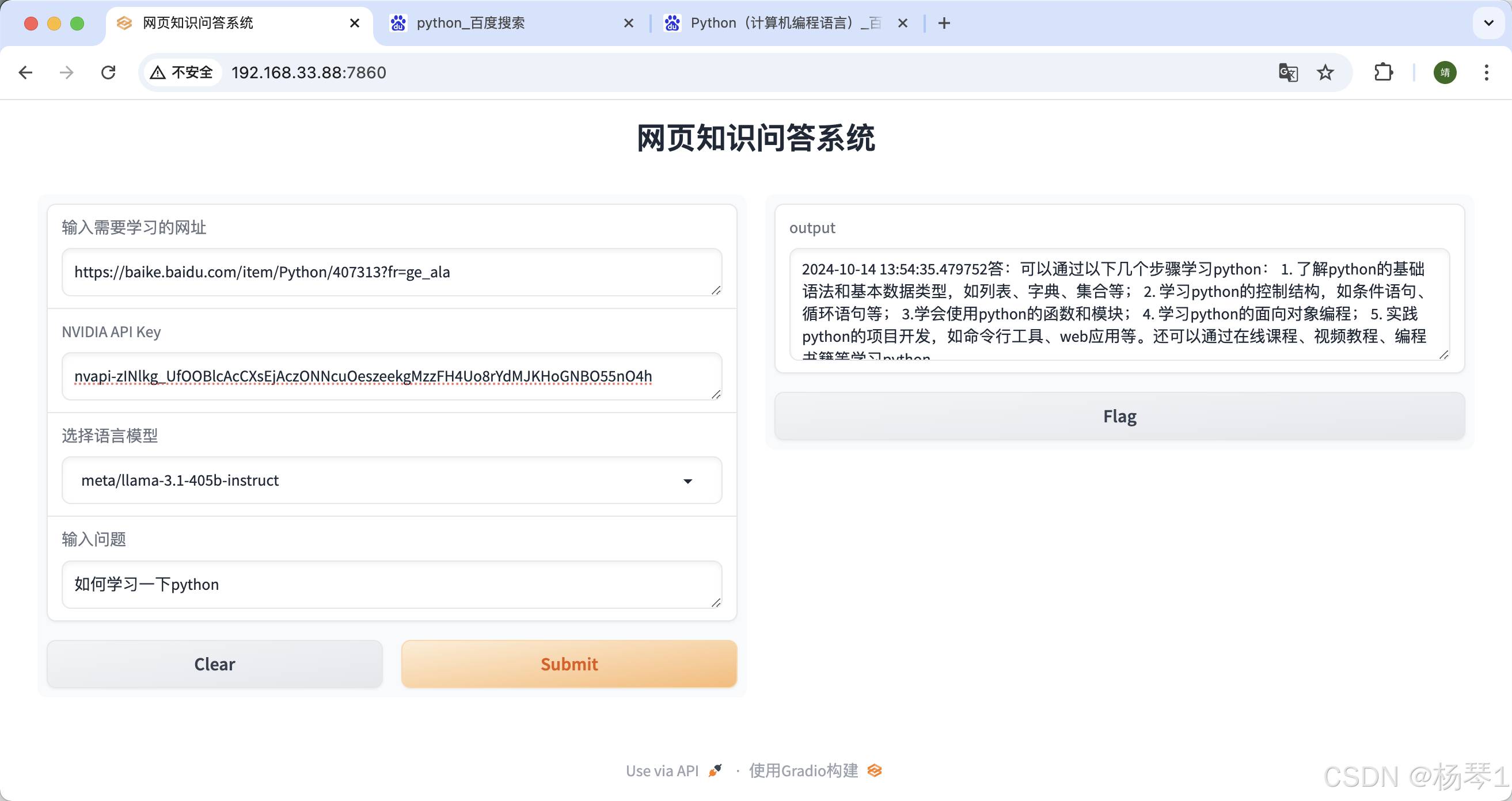
title="网页知识问答系统"
)
# 启动Gradio界面
iface.launch()
上述代码构建了一个基于网页知识的问答系统,并使用了NVIDIA的AI模型进行推理。这个系统的大致工作流程如下:
当用户提出问题时,系统首先使用选定的NVIDIA AI模型生成一个假设性的回答,这个回答被用作检索的查询。
另外,值得注意的是,你的代码中包含了硬编码的部分,如假设性回答模板和最终回答模板。这些部分可能需要根据实际的应用场景进行调整。
总的来说,你的代码实现了一个有趣且实用的应用,即基于网页知识的问答系统。通过整合网页数据、向量检索和AI模型推理,你的系统能够为用户提供相关且准确的回答。

启动之后,发现使用IP地址+端口访问不通,以下为增加Gradio的配置,当把server_name设置为’0.0.0.0’时,局域网内的电脑皆可通过服务器IP访问该服务:
# 启动Gradio应用
iface = gr.Interface(
fn=process_question,
inputs=[
gr.Textbox(label="输入需要学习的网址"),
gr.Textbox(label="NVIDIA API Key"),
gr.Dropdown(models, label="选择语言模型"),
gr.Textbox(label="输入问题")
],
outputs="text",
title="网页知识问答系统"
)
# 增加这一句
iface.launch(server_name='192.168.33.88')
# 启动Gradio界面
iface.launch()
其强大的推理能力和逻辑能力使其成为内容生成、摘要、问答和情感分析任务的理想选择:
# 导入OpenAI库
from openai import OpenAI
# 初始化OpenAI客户端,配置base_url和api_key
# base_url指向NVIDIA的API服务
# api_key是用于身份验证的密钥,如果在NGC外部执行则需要提供
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "$API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC"
)
# 创建聊天完成请求
# 选择使用microsoft的phi-3-mini-4k-instruct模型
# 请求内容是生成一首关于GPU计算奇迹的limerick诗
# 设置生成参数:temperature控制随机性,top_p控制多样性,max_tokens限制最大生成长度,stream设置为True以流式接收结果
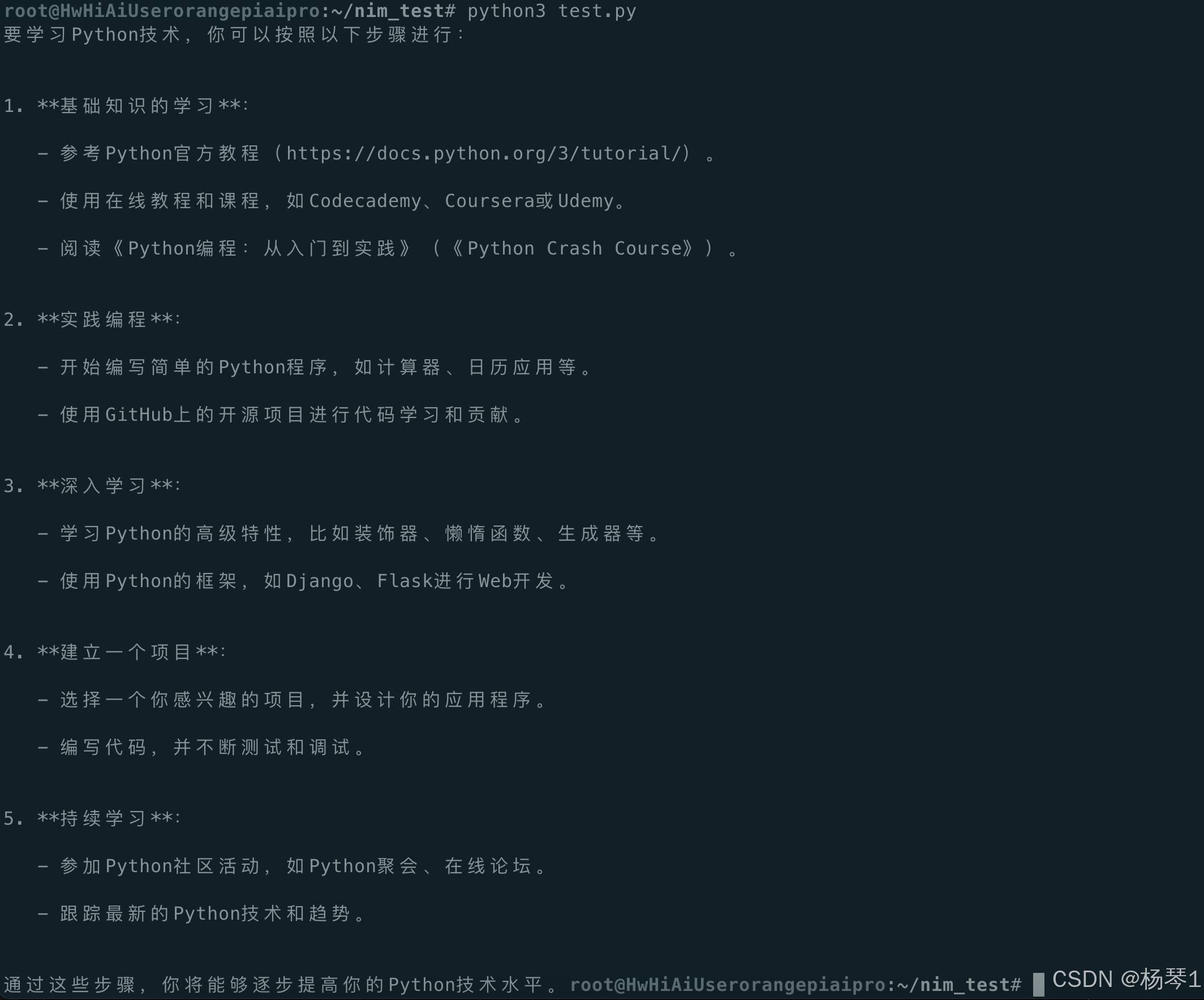
completion = client.chat.completions.create(
model="microsoft/phi-3-mini-4k-instruct",
messages=[{"role":"user","content":"如何学习使用python"}],
temperature=0.2,
top_p=0.7,
max_tokens=1024,
stream=True
)
# 流式处理生成的结果
# 遍历每个返回的块,检查内容是否非空并逐块打印
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码