目录
- 一、Parler-TTS简介
- 1.1、TTS 模型
- 1.2、Parler-TTS
- 二、Parler-TTS复现流程
- 2.1、创建实例
- 2.2、配置代码与环境
- 2.3、配置预训练模型
- 2.4、Parles-TTS使用
Parler-TTS 是一个由 Hugging Face 开源的文本生成语音 (Text-to-Speech, TTS) 模型。它的设计目的是生成高质量的语音输出,支持自然的语调和流畅的语音合成。Parler-TTS 能够将输入的文本转化为逼真的语音,适用于各种语音生成应用场景,如虚拟助理、有声书、语音生成内容等。
代码仓库:https://github.com/huggingface/parler-tts
论文地址:https://arxiv.org/html/2402.01912v1
本篇将解析Parler-TTS原理,并使用丹摩服务器进行部署复现与初步体验。
传统的 TTS 模型在处理语音合成时,通常依赖大规模的语音数据集,并采用人类标注的音素、音节等细粒度信息。然而,这种方式存在标注过程耗时且昂贵和人工标注可能带有主观性和误差的问题
为了解决这些问题,Dan Lyth和Simon King的研究论文Natural language guidance of high-fidelity text-to-speech with synthetic annotations提出使用自然语言的指导信息结合合成标注,使模型更好地理解上下文语境,从而生成更加高保真的语音。
该方法的核心在于用自然语言注释驱动 TTS 模型。即,通过自然语言描述声音属性(如情感、重音、语气等)来指导语音合成。这些描述会生成相应的合成标注,从而使模型能够灵活地根据不同的语境和情感需求生成语音。
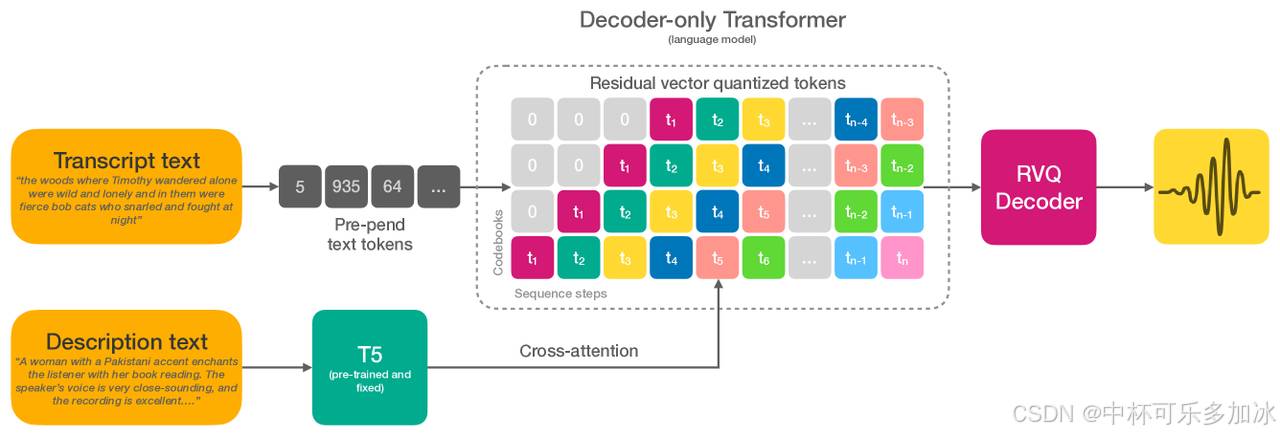
论文提出的模型结构如上所示,主要包括以下模块:
基于这样的原理,Parler-TTS开发了一款轻量级的文本转语音模型,能够生成高质量、自然的声音,模仿特定说话者的风格(如性别、音调、说话风格等)。与其他TTS模型不同,Parler-TTS是一个完全开源的项目,包括数据集、预处理、训练代码和权重,均在宽松的许可下公开发布,鼓励社区在此基础上进一步开发和创新。其主要特点有:
本次实验选择了DAMODEL(丹摩智算)平台,丹摩平台一直致力于提供丰富的算力资源与基础设施助力AI应用的开发、训练、部署。
首先进入丹摩控制台,点击创建实例:
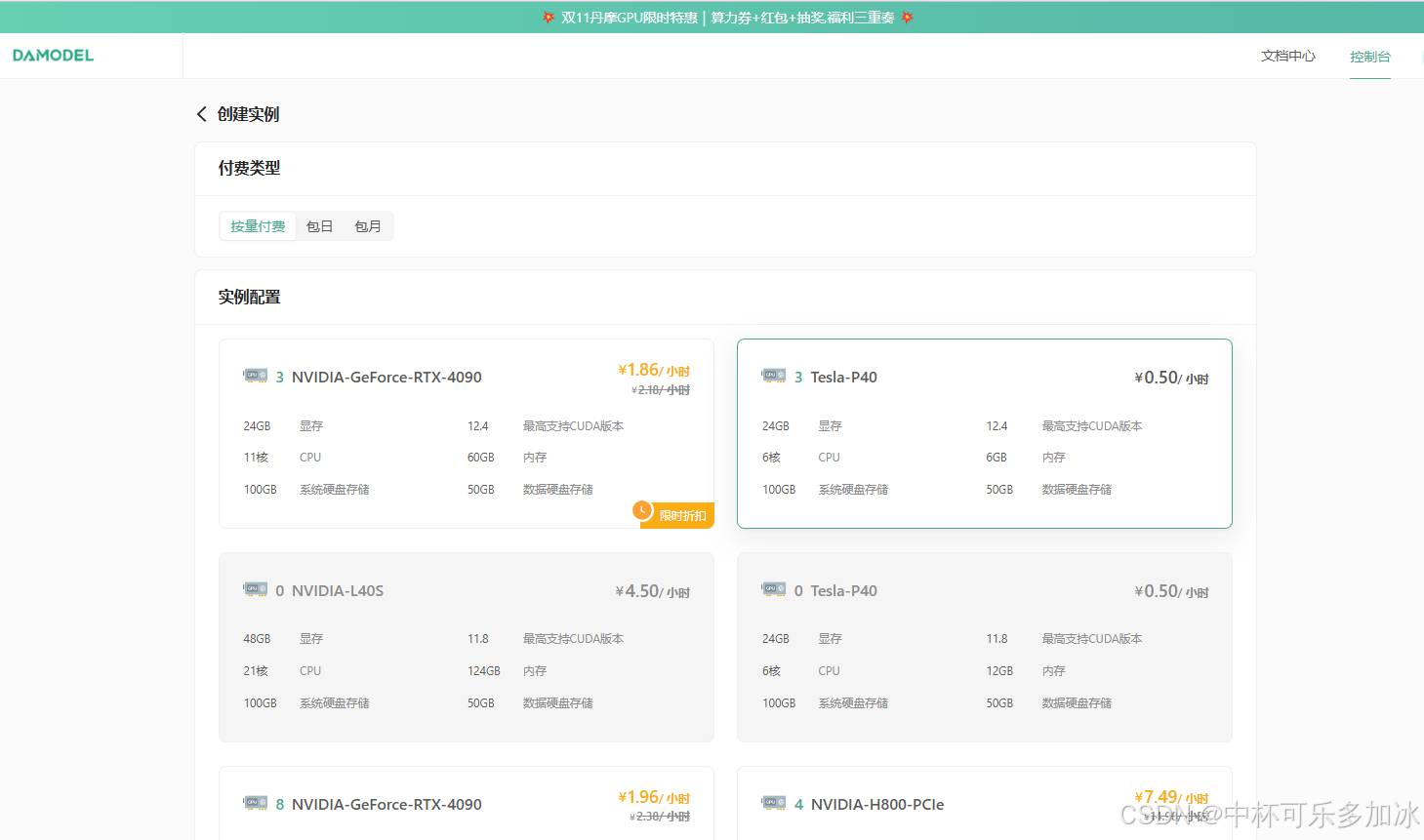
本次实验采用的文本转语音模型为轻量级模型,基本上选择Tesla-P40或者3090就可以满足条件:
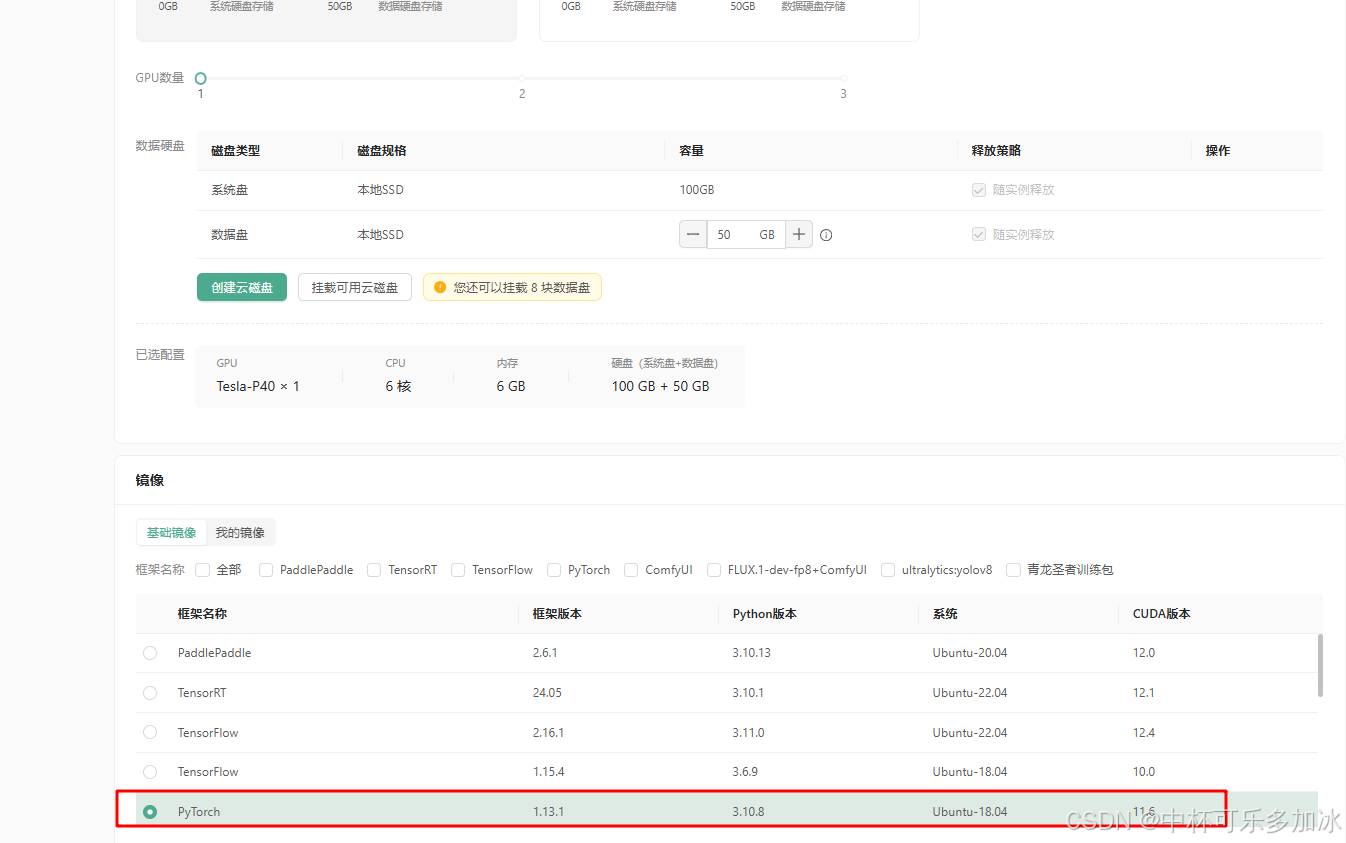
数据硬盘上可以选择默认的50GB,镜像上可以直接选择PyTorch1.13.1、Python3.10.8、CUDA11.6版本:
首先打开Jupyter,在终端输入git clone https://gitee.com/ctllin/parler-tts克隆仓库代码,完整的项目结构如左侧所示:
其次输入pip install git+https://gitee.com/ctllin/parler-tts安装依赖环境:

然后我们在项目目录下新建一个test.py文件,在其中编写以下代码:
from parler_tts import ParlerTTSForConditionalGeneration
from transformers import AutoTokenizer
import soundfile as sf
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = ParlerTTSForConditionalGeneration.from_pretrained("parler-tts/parler_tts_mini_v0.1").to(device)
tokenizer = AutoTokenizer.from_pretrained("parler-tts/parler_tts_mini_v0.1")
prompt = "Hey, how are you doing today?"
description = "A female speaker with a slightly low-pitched voice delivers her words quite expressively, in a very confined sounding environment with clear audio quality. She speaks very fast."
input_ids = tokenizer(description, return_tensors="pt").input_ids.to(device)
prompt_input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
generation = model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
sf.write("parler_tts_out.wav", audio_arr, model.config.sampling_rate)
代码使用 Parler-TTS 模型将带有风格描述的文本输入转换成语音,生成一段语音文件parler_tts_out.wav
配置好代码与环境后,可以输入python test.py进行运行,但是此时一般会碰见以下报错:
OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like parler-tts/parler_tts_mini_v0.1 is not the path to a directory containing a file named config.json.
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
这个报错是因为因为网络原因,from_pretrained 方法在 Hugging Face Hub 上找不到指定的模型文件,模型加载失败,所以我们需要去huggingface上下载预训练模型。
进入https://hf-mirror.com/parler-tts/parler_tts_mini_v0.1/tree/main,可以看到预训练模型的结构如下:
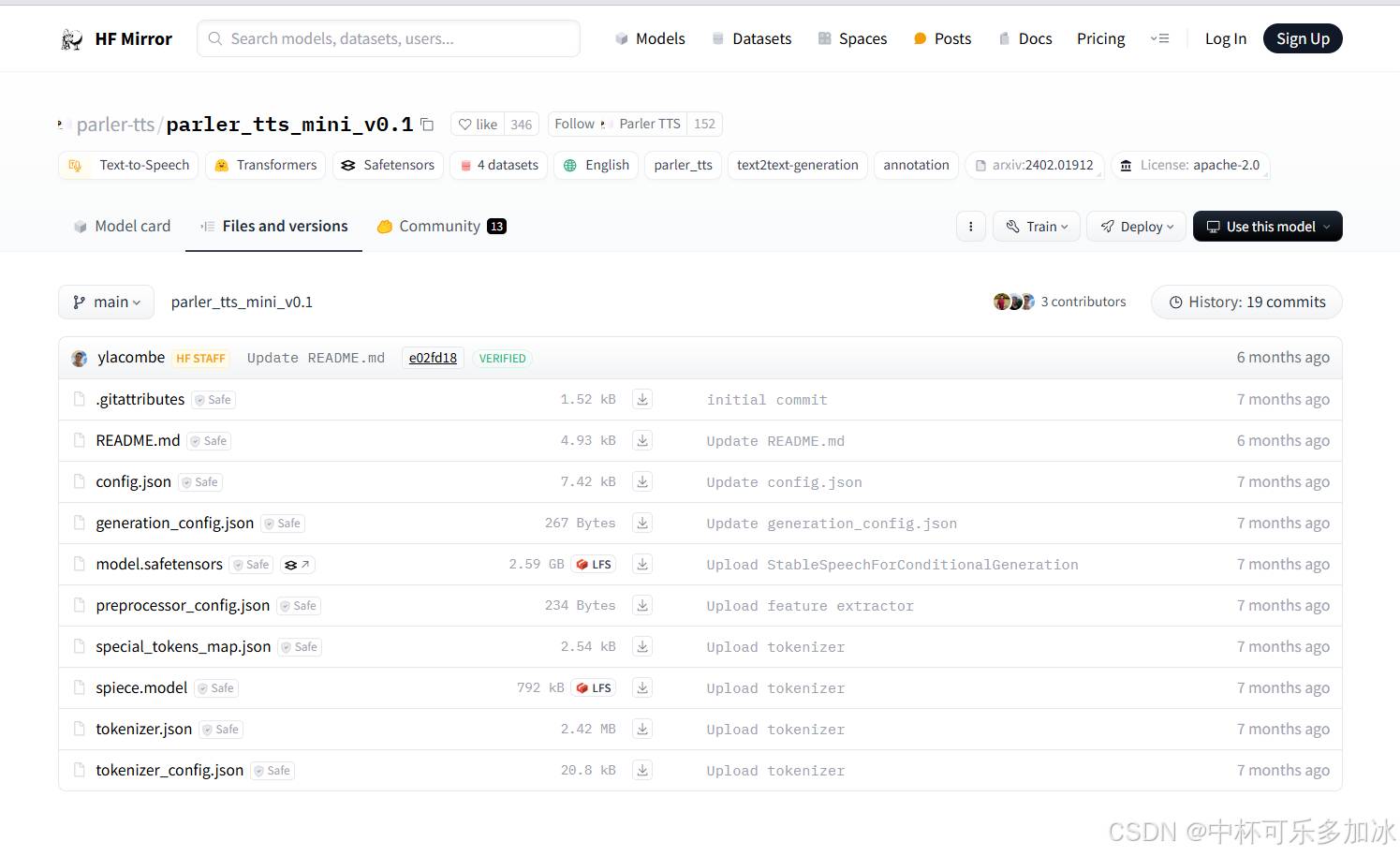
将其全部下载并上传到服务器当中(也可以使用wget命令进行下载)放入到新建的model文件夹里,当然这里仅仅演示miniv0.1模型的效果,该项目后续还推出了large模型以及miniv1.0、1.1版本,可以进行体验。下载完成后,模型结构如下图所示:

并将test.py代码中加载预训练模型的两句改为从本地加载:

cd进入Parler-tts项目,然后终端输入python test.py
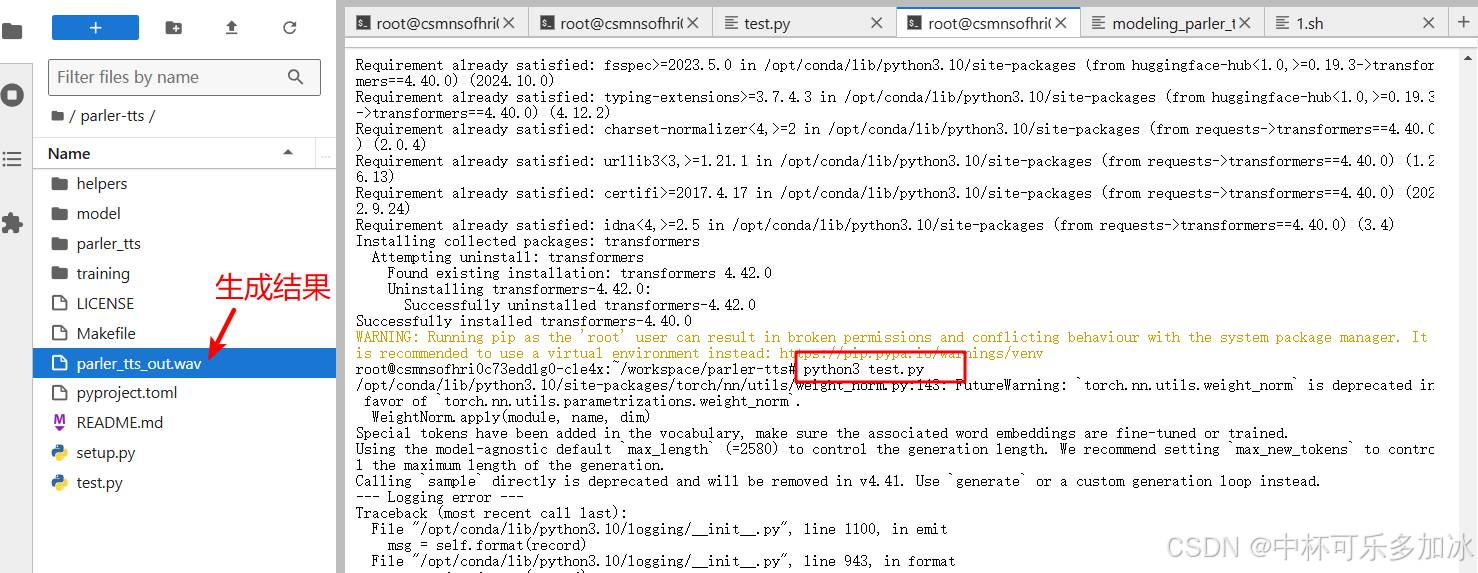
如果遇到ValueError: 'dac' is already used by a Transformers config, pick another name.错误,说明transformers的版本没有安装正确,需要安装transformers4.40.0版本,可以终端输入pip install transformers==4.40.0解决该问题。
项目成功运行后,会生成一个wav的录音文件,可以下载到本地播放,效果非常的不错,而且可以控制音色,看起来有很大的商用价值。当然如果想要生成长语音、别的音色、AI配音讲故事,可以修改test.py代码中的prompt和description:
prompt = "Hey, how are you doing today?"
description = "A female speaker with a slightly low-pitched voice delivers her words quite expressively, in a very confined sounding environment with clear audio quality. She speaks very fast."
另外,其还提供了训练的策略及方法,可以通过引入高质量的语音数据和语音描述来生成更具表现力的语音输出,具体步骤可以查看官方仓库。
最后,感谢丹摩为本文提供算力支持,除了常规的4090显卡和P40显卡,DAMODEL(丹摩智算)还具备A800、H800系列显卡,目前双十一活动火热进行中,值得关注!
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码