腾讯云双十一活动入口

近年来,随着深度学习的爆炸式发展,AI 模型训练与推理对计算资源的需求大幅增长。传统的 GPU 本地化方案不仅昂贵且扩展性差,无法满足动态需求。腾讯云推出的 HAI 智算服务,以灵活的云端 GPU 服务和高性价比的特性,成为开发者和企业部署高性能 AI 应用的理想选择。
本次测评从产品功能、性能优势、应用场景以及实际案例出发,全面剖析 HAI 智算服务的技术特点和应用潜力。同时,提供丰富的代码示例,帮助开发者快速上手。
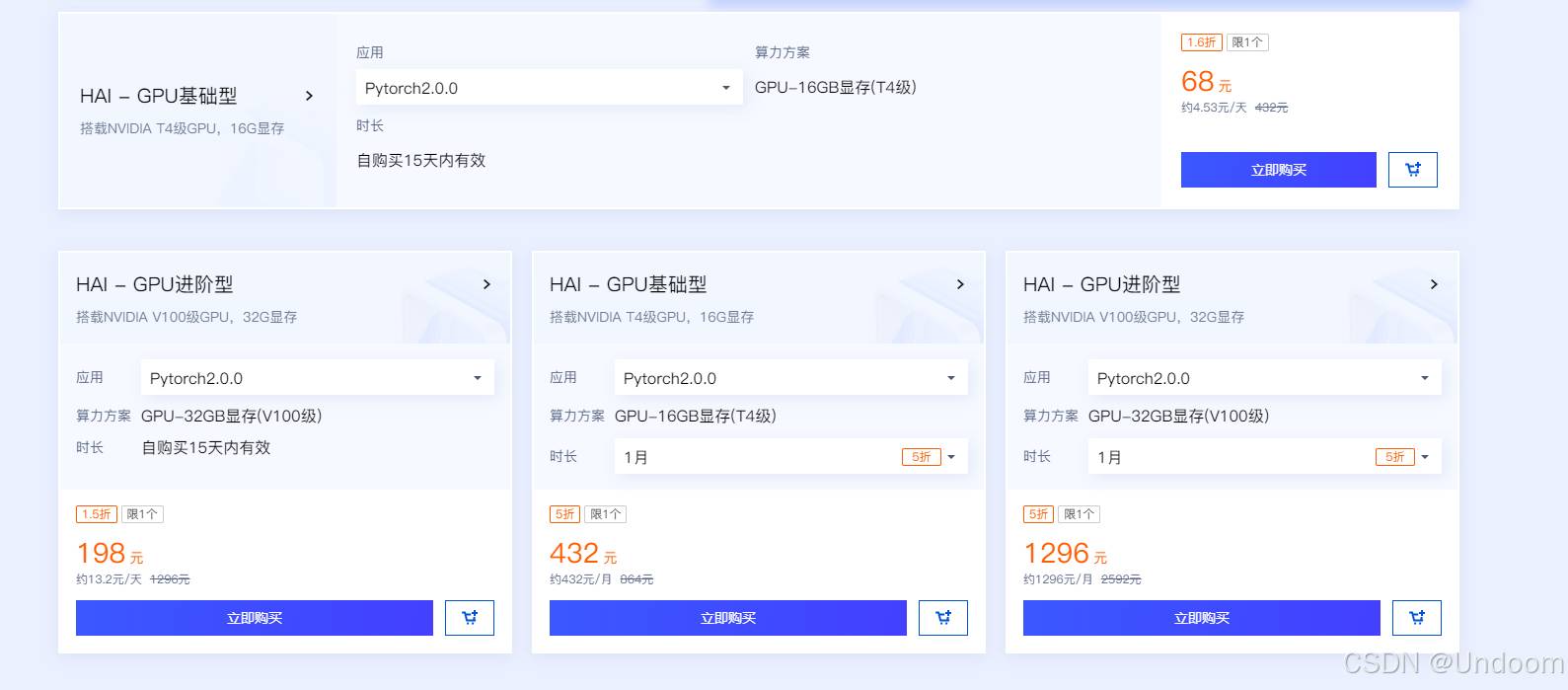
HAI 提供多种 GPU 配置以满足不同用户需求:
用户可以按需选择 GPU 型号、运行时间和计算场景,最大程度节省资源开销。
HAI 内置主流深度学习框架和工具,用户无需自行配置复杂的环境,能够即开即用:
以下代码演示了如何加载并测试 HAI 环境的 GPU 兼容性:
import torch
# 检查 GPU 是否可用
print("CUDA Available:", torch.cuda.is_available())
# 获取当前 GPU 名称
if torch.cuda.is_available():
print("GPU Device Name:", torch.cuda.get_device_name(0))
运行此代码后,用户即可确认是否正确连接 HAI 的高性能 GPU。
HAI 提供内置性能监控工具,可实时查看 GPU 的以下指标:
这些数据可帮助开发者优化模型运行效率,避免算力资源浪费。
HAI 基于腾讯云分布式 GPU 集群,具备弹性扩展能力:
HAI 的底层架构优化了 GPU 的并行计算能力,并针对深度学习场景进行了特别设计:
为了更好地展示 HAI 的性能,我们选择了 NLP 和 CV 两个领域的任务进行测试。
IMDb 数据集包含 5 万条电影评论,目标是将评论分为正面或负面。
在 HAI 控制台选择 V100 32GB GPU,启用 PyTorch 2.0 环境,安装必要的依赖:
pip install transformers datasets scikit-learn
from datasets import load_dataset
from transformers import BertTokenizer
# 加载 IMDb 数据集
dataset = load_dataset("imdb")
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# 数据分词
def preprocess_data(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length', max_length=128)
# 应用分词到数据集
encoded_dataset = dataset.map(preprocess_data, batched=True)
encoded_dataset.set_format(type='torch', columns=['input_ids', 'attention_mask', 'label'])
from transformers import BertForSequenceClassification
from torch.utils.data import DataLoader
import torch
from tqdm import tqdm
# 加载预训练模型
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2).to('cuda')
# 数据加载器
train_loader = DataLoader(encoded_dataset['train'], batch_size=16, shuffle=True)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
# 开始训练
model.train()
for epoch in range(3):
loop = tqdm(train_loader, leave=True)
for batch in loop:
optimizer.zero_grad()
input_ids = batch['input_ids'].to('cuda')
attention_mask = batch['attention_mask'].to('cuda')
labels = batch['label'].to('cuda')
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
loop.set_description(f'Epoch {epoch}')
loop.set_postfix(loss=loss.item())
from sklearn.metrics import accuracy_score
# 测试集推理
model.eval()
predictions, labels = [], []
with torch.no_grad():
for batch in DataLoader(encoded_dataset['test'], batch_size=16):
input_ids = batch['input_ids'].to('cuda')
attention_mask = batch['attention_mask'].to('cuda')
outputs = model(input_ids, attention_mask=attention_mask)
preds = torch.argmax(outputs.logits, axis=-1)
predictions.extend(preds.cpu().numpy())
labels.extend(batch['label'].cpu().numpy())
# 计算准确率
accuracy = accuracy_score(labels, predictions)
print(f"测试集准确率:{accuracy * 100:.2f}%")
CIFAR-10 包含 6 万张 32×32 分辨率的图片,分为 10 类。
import tensorflow as tf
import matplotlib.pyplot as plt
# 加载数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 样本可视化
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(x_train[i])
plt.title(class_names[y_train[i][0]])
plt.axis('off')
plt.show()
from tensorflow.keras.applications import ResNet50
from tensorflow.keras import layers, models
# 加载 ResNet50
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(32, 32, 3))
base_model.trainable = False
# 添加分类头
model = models.Sequential([
base_model,
layers.GlobalAveragePooling2D(),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])
# 编译与训练
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10, batch_size=64)
在以上 NLP 和 CV 的基本场景之外,腾讯云 HAI 智算服务还能够满足更复杂的应用场景,例如分布式训练、多模态学习以及实时推理等。以下是更加深入的技术实践案例。
基于 GPT 模型的文本生成任务(如对话生成、内容创作),需要在大规模数据集上进行微调。单 GPU 显存往往不足以支持完整的训练流程,而分布式训练能够显著提高效率。
transformers 和 deepspeed 工具:pip install transformers deepspeed
以下代码展示了如何使用 DeepSpeed 实现 GPT-2 微调:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
from datasets import load_dataset
import deepspeed
# 加载数据集
dataset = load_dataset("wikitext", "wikitext-2-raw-v1", split='train')
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# 数据预处理
def preprocess_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)
encoded_dataset = dataset.map(preprocess_function, batched=True)
encoded_dataset.set_format(type='torch', columns=['input_ids'])
# 定义模型
model = GPT2LMHeadModel.from_pretrained("gpt2")
model = model.to('cuda')
# DeepSpeed 配置
ds_config = {
"train_micro_batch_size_per_gpu": 8,
"gradient_accumulation_steps": 2,
"fp16": {
"enabled": True
}
}
# 包装模型
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
model_parameters=model.parameters(),
config=ds_config
)
# 开始训练
model_engine.train()
train_loader = torch.utils.data.DataLoader(encoded_dataset, batch_size=8, shuffle=True)
for epoch in range(3):
for batch in train_loader:
input_ids = batch['input_ids'].to('cuda')
loss = model_engine(input_ids, labels=input_ids).loss
model_engine.backward(loss)
model_engine.step()
在电商平台或社交媒体中,图文匹配任务是一个重要的应用场景。例如,判断商品图片与文本描述是否匹配。这需要同时处理图片和文本两种模态的数据。
使用 CLIP(Contrastive Language–Image Pretraining)模型,同时输入图片和文本,实现特征对齐。
from PIL import Image
import torch
from transformers import CLIPProcessor, CLIPModel
# 加载 CLIP 模型和预处理工具
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32").to('cuda')
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 示例图片和文本
image = Image.open("example.jpg")
text = ["This is a picture of a cat", "This is a picture of a dog"]
# 数据预处理
inputs = processor(text=text, images=image, return_tensors="pt", padding=True).to('cuda')
# 前向计算
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
# 输出匹配概率
print("匹配概率:", probs)
许多实际业务需要将模型部署为实时推理服务,例如在线推荐系统或智能客服。
选择 T4 GPU 实例,并安装 FastAPI 和相关工具:
pip install fastapi uvicorn
以下代码展示了一个简单的在线推理服务:
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# 加载模型
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name).to('cuda')
app = FastAPI()
@app.post("/predict/")
async def predict(request: Request):
data = await request.json()
text = data['text']
# 文本处理与推理
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True).to('cuda')
outputs = model(**inputs)
prediction = torch.argmax(outputs.logits, dim=-1).item()
return {"prediction": prediction}
运行以下命令启动服务:
uvicorn main:app --host 0.0.0.0 --port 8000
通过 HTTP 请求发送文本进行测试:
import requests
response = requests.post("http://127.0.0.1:8000/predict/", json={"text": "I love this product!"})
print(response.json())
通过一系列测试用例可以看出,腾讯云 HAI 智算服务在高性能计算场景中表现优异,其核心优势包括:
未来展望:
HAI 智算服务无疑是推动 AI 计算走向普及的重要力量,其广阔的应用潜力将随着技术迭代进一步释放!
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码