人工智能(AI)是现代科技的重要领域,其中的算法是实现智能的核心。本文将介绍10种常见的人工智能算法,包括它们的原理、训练方法、优缺点及适用场景。
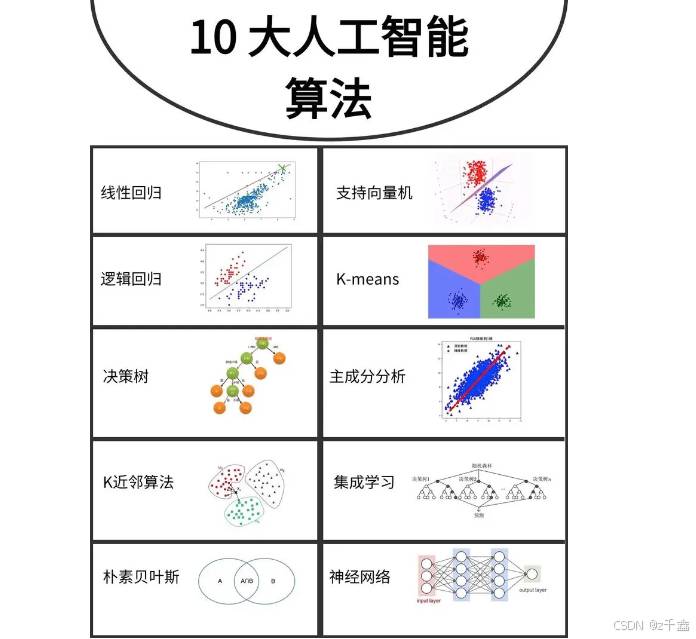
线性回归用于建立自变量(特征)与因变量(目标)之间的线性关系。其目标是寻找最佳拟合直线,使得预测值与实际值之间的误差最小化。
通过最小二乘法来最小化预测值与真实值之间的误差,得到线性回归方程的参数。
适合用于数值预测,如房价、销售额等。
import numpy as np
from sklearn.linear_model import LinearRegression
# 模拟数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 3, 5, 7, 11])
# 创建线性回归模型
model = LinearRegression()
model.fit(X, y)
# 预测
predictions = model.predict(np.array([[6]]))
print(predictions) # 预测6对应的y值
逻辑回归用于二分类问题,通过Sigmoid函数将线性组合的输入映射到0和1之间,输出为事件发生的概率。
使用最大似然估计来优化模型参数,使得预测的概率与实际标签相匹配。
适合用于信用评分、疾病预测等二分类问题。
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# 加载数据
data = load_iris()
X = data.data
y = (data.target == 0).astype(int) # 仅考虑类0与其它类
# 创建逻辑回归模型
model = LogisticRegression()
model.fit(X, y)
# 预测
predictions = model.predict(X)
print(predictions)
决策树通过树状结构进行决策,从根节点到叶节点的路径表示分类规则。
使用信息增益或基尼指数选择最佳特征进行节点分裂,直到满足停止条件。
适合用于客户分类、信用评分等。
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
# 加载数据
data = load_iris()
X = data.data
y = data.target
# 创建决策树模型
model = DecisionTreeClassifier()
model.fit(X, y)
# 预测
predictions = model.predict(X)
print(predictions)
SVM通过寻找最佳超平面来分隔不同类别的数据点,最大化类间间隔。
使用优化算法找到支持向量和超平面,通常通过拉格朗日乘子法实现。
适合用于文本分类、图像分类等。
from sklearn import datasets
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
# 加载数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 创建SVM模型
model = SVC(kernel='linear')
model.fit(X_train, y_train)
# 预测
predictions = model.predict(X_test)
print(predictions)
k-NN是基于实例的学习方法,通过找到与目标点最近的k个邻居进行分类或回归。
没有显式的训练过程,主要通过计算距离来进行预测。
适合用于推荐系统、图像识别等。
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# 加载数据
data = load_iris()
X = data.data
y = data.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 创建k-NN模型
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
# 预测
predictions = model.predict(X_test)
print(predictions)
随机森林是集成学习方法,通过多棵决策树的投票结果提高分类或回归的准确性。
通过随机抽样和特征选择构建多棵决策树,最终通过投票或平均得到结果。
适合用于金融风控、医疗诊断等。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据
data = load_iris()
X = data.data
y = data.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 创建随机森林模型
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# 预测
predictions = model.predict(X_test)
print(predictions)
神经网络模拟人脑结构,由多个神经元组成,通过激活函数非线性组合输入特征。
使用反向传播算法和梯度下降法优化网络参数,以最小化损失函数。
适合用于图像识别、自然语言处理等。
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
# 模拟数据
X = np.random.rand(100, 10)
y = np.random.rand(100, 1)
# 创建神经网络模型
model = Sequential()
model.add(Dense(10, input_dim=10, activation='relu'))
model.add(Dense(1, activation='linear'))
# 编译模型
model.compile(loss='mean_squared_error', optimizer='adam')
# 训练模型
model.fit(X, y, epochs=100, batch_size=10)
# 预测
predictions = model.predict(np.random.rand(1, 10))
print(predictions)
CNN特别适合图像处理,通过卷积层提取特征,池化层降低维度。
使用反向传播算法优化卷积核和全连接层的权重。
适合用于图像分类、目标检测等。
import tensorflow as tf
from tensorflow.keras import layers, models
# 创建卷积神经网络模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
RNN适合处理序列数据,具有记忆能力,能捕捉时间序列中的依赖关系。
使用反向传播算法通过时间(BPTT)更新权重。
适合用于自然语言处理、时间序列预测等。
import numpy as np
from keras.models import Sequential
from keras.layers import SimpleRNN, Dense
# 模拟序列数据
X = np.random.rand(100, 10, 1) # 100个样本,10个时间步,1个特征
y = np.random.rand(100, 1)
# 创建RNN模型
model = Sequential()
model.add(SimpleRNN(50, input_shape=(10, 1)))
model.add(Dense(1))
# 编译模型
model.compile(loss='mean_squared_error', optimizer='adam')
# 训练模型
model.fit(X, y, epochs=100, batch_size=10)
# 预测
predictions = model.predict(np.random.rand(1, 10, 1))
print(predictions)
强化学习通过与环境的交互获得反馈,学习如何采取行动以最大化累积奖励。
使用策略梯度或Q-learning等算法更新策略,使得在当前状态下选择的动作获得的预期奖励最大化。
适合用于游戏AI、机器人控制等。
import numpy as np
class SimpleEnvironment:
def __init__(self):
self.state = 0
def step(self, action):
if action == 1:
self.state += 1
else:
self.state -= 1
reward = 1 if self.state >= 10 else -1
done = self.state >= 10 or self.state <= -10
return self.state, reward, done
# 简单的强化学习示例
env = SimpleEnvironment()
for episode in range(20):
state = env.state
done = False
while not done:
action = np.random.choice([0, 1]) # 随机选择动作
state, reward, done = env.step(action)
print(f"状态: {state}, 奖励: {reward}, 是否结束: {done}")
🔥codemoss_能用AI
【无限GPT4.omini】
【拒绝爬梯】
【上百种AI工作流落地场景】
【主流大模型集聚地:GPT-4o-Mini、GPT-3.5 Turbo、GPT-4 Turbo、GPT-4o、GPT-o1、Claude-3.5-Sonnet、Gemini Pro、月之暗面、文心一言 4.0、通易千问 Plus等众多模型】
🔥传送门:https://www.nyai.chat/chat?invite=nyai_1141439&fromChannel=csdn
以上介绍了10种常见的人工智能算法及其原理、训练方法、优缺点和使用场景。每种算法在不同的应用场景下都有其优势和劣势,选择合适的算法是实现有效模型的关键。希望本文能为您的学习和实际应用提供帮助。
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码