大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
目标检测任务已经不是一个新鲜事了,但是多模态大模型作目标检测任务并不多见,本文详细记录swfit微调interVL2-8B多模态大模型进行目标检测的过程,旨在让更多人了解多模态大模型微调技术、共享微调经验。
并不是所有开源多模态大模型都有目标检测能力。
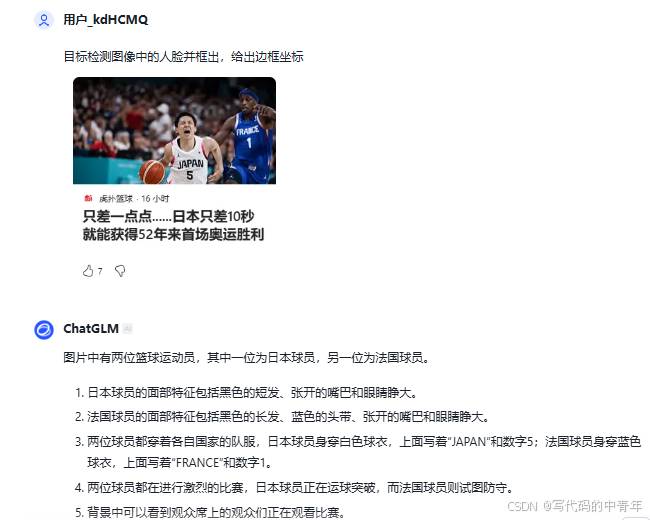
如图所示,哪怕是闭源模型,也并都不具备目标检测能力。
经调研,我们选用interVL2-8B模型,在模型性能指标上,该模型胜过interVL1.5-26B的同时,还具备目标检测能力,且与interVL2-26B、40B、70B模型性能差不并没有非常巨大。
其回答格式也很有意思,此处分享:
<ref>zs_code</ref><box>[[476,1221,814,1259]]</box>
本文任务数据集均为自行制作,其中,数据分布如下图:
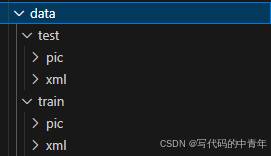
其中,test文件夹用于性能测试,tain文件夹用于模型训练。pic子文件夹表示图像存储路径,xml表示标注存储路径,图像与标注一一对应。
具体内容如下:
图像示例:

对应标注示例
<annotation>
<folder>code_data</folder>
<filename>xxx-本科毕业证.jpg</filename>
<path>C:\Users\12258\Desktop\code_data\xxx-本科毕业证.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>842</width>
<height>596</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>zs_code</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>142</xmin>
<ymin>422</ymin>
<xmax>351</xmax>
<ymax>446</ymax>
</bndbox>
</object>
</annotation>
该数据集使用labelimg手动标注,每张图像为典型毕业证、学位证、学历验证、资质证书影像,只含一个标签名称zs_code。
其中,测试图像30张,训练图像250张。
编写脚本,构建可用于微调训练的数据集jsonl,jsonl配合图像即可完成swift框架下的多模态模型微调。
import os
import random
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
import json
from PIL import Image, ExifTags
import xml.etree.ElementTree as ET
def create_directory(path):
"""Create a new directory at the given path."""
try:
os.makedirs(path, exist_ok=True)
return f"Directory created at {path}"
except Exception as e:
return f"An error occurred: {e}"
def list_files(directory):
"""List all files in the given directory."""
return [file for file in os.listdir(directory) if os.path.isfile(os.path.join(directory, file))]
def list_files_with_absolute_paths(directory):
"""List all files in the given directory with their absolute paths."""
return [os.path.abspath(os.path.join(directory, file)) for file in os.listdir(directory) if os.path.isfile(os.path.join(directory, file))]
def extract_xml_info(xml_file_path):
with open(xml_file_path, 'r',encoding='utf-8') as file:
xml_content = file.read()
# 解析XML内容
root = ET.fromstring(xml_content)
# 初始化一个列表来保存提取的信息
extracted_info = []
# 遍历所有<object>标签
for obj in root.findall('object'):
name = obj.find('name').text
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
# 将提取的信息保存到列表中
extracted_info.append({'name': name, 'xmin': xmin, 'ymin': ymin, 'xmax': xmax, 'ymax': ymax})
name = str(extracted_info[0]['name'])
xmin = str(extracted_info[0]['xmin'])
ymin = str(extracted_info[0]['ymin'])
xmax = str(extracted_info[0]['xmax'])
ymax = str(extracted_info[0]['ymax'])
# 仅仅用于单标注图像
result = f'<ref>{name}</ref><box>[[{xmin},{ymin},{xmax},{ymax}]]</box>'
return result
def get_elements_with_string(lst, target_string):
return [element for element in lst if target_string in element]
train_pic_path = '/home/super/lyq/zsbm_mbjc/data/train/pic'
train_xml_path = '/home/super/lyq/zsbm_mbjc/data/train/xml'
test_pic_path = '/home/super/lyq/zsbm_mbjc/data/test/pic'
test_xml_path = '/home/super/lyq/zsbm_mbjc/data/test/xml'
train_pic_absolute_paths = list_files_with_absolute_paths(train_pic_path)
train_xml_absolute_paths = list_files_with_absolute_paths(train_xml_path)
test_pic_absolute_paths = list_files_with_absolute_paths(test_pic_path)
test_xml_absolute_paths = list_files_with_absolute_paths(test_xml_path)
train_pic_paths = list_files(train_pic_path)
train_xml_paths = list_files(train_xml_path)
test_pic_paths = list_files(test_pic_path)
test_xml_paths = list_files(test_xml_path)
dataset = []
for train_pic_absolute_path in train_pic_absolute_paths:# 图像路径
mid_dict = {}
file_head = train_pic_absolute_path.split('/')[-1].split('.')[0]
# print(file_head,train_pic_absolute_path)
xml_path = get_elements_with_string(train_xml_absolute_paths,file_head)[0]
# print(xml_path)
xml_info = extract_xml_info(xml_path) # response
mid_dict = {
'system':'''职位:你是一个面向证书图像的目标检测大师,具备精准识别、定位图像中证书编码的能力。
职能:从毕业证、学历验证报告、证书等图像中检测到证书编码区域并给出边界框。
**注意**:仅以给定格式返回检测结果,不要给出其它任何解释。
**注意**:若图片中没有典型违章场景,返回<ref> class_name </ref><box>[[0, 0, 0, 0]]</box>即可。
''',
'query':'请目标检测图像中的证书编码并给出边界框',
'response':xml_info,
'images':train_pic_absolute_path
}
dataset.append(mid_dict)
# 指定输出文件的名称
output_file = 'train_dataset.jsonl'
# 打开文件并写入JSONL格式的数据
with open(output_file, 'w', encoding='utf-8') as f:
for item in dataset:
# 将字典转换为JSON字符串并写入文件,每个字典占一行
json_string = json.dumps(item,ensure_ascii=False)
f.write(json_string + '\n')
dataset = []
for test_pic_absolute_path in test_pic_absolute_paths:# 图像路径
mid_dict = {}
file_head = test_pic_absolute_path.split('/')[-1].split('.')[0]
xml_path = get_elements_with_string(test_xml_absolute_paths,file_head)[0]
xml_info = extract_xml_info(xml_path) # response
mid_dict = {
'system':'''职位:你是一个面向证书图像的目标检测大师,具备精准识别、定位图像中证书编码的能力。
职能:从毕业证、学历验证报告、证书等图像中检测到证书编码区域并给出边界框。
**注意**:仅以给定格式返回检测结果,不要给出其它任何解释。
**注意**:若图片中没有典型违章场景,返回<ref> class_name </ref><box>[[0, 0, 0, 0]]</box>即可。
''',
'query':'请目标检测图像中的证书编码并给出边界框',
'response':xml_info,
'images':test_pic_absolute_path
}
dataset.append(mid_dict)
# 指定输出文件的名称
output_file = 'test_dataset.jsonl'
# 打开文件并写入JSONL格式的数据
with open(output_file, 'w', encoding='utf-8') as f:
for item in dataset:
# 将字典转换为JSON字符串并写入文件,每个字典占一行
json_string = json.dumps(item,ensure_ascii=False)
f.write(json_string + '\n')
上述代码结果为test_dataset.jsonl和train_dataset.jsonl两个jsonl文件,分别对应train、test文件夹。
test_dataset.jsonl
{"system": "职位:你是一个面向证书图像的目标检测大师,具备精准识别、定位图像中证书编码的能力。\n 职能:从毕业证、学历验证报告、证书等图像中检测到证书编码区域并给出边界框。\n **注意**:仅以给定格式返回检测结果,不要给出其它任何解释。\n **注意**:若图片中没有典型违章场景,返回<ref> class_name </ref><box>[[0, 0, 0, 0]]</box>即可。\n ", "query": "请目标检测图像中的证书编码并给出边界框", "response": "<ref>zs_code</ref><box>[[67,761,302,798]]</box>", "images": "/home/super/lyq/zsbm_mbjc/data/train/pic/xxx-专科毕业证.jpg"}
{"system": "职位:你是一个面向证书图像的目标检测大师,具备精准识别、定位图像中证书编码的能力。\n 职能:从毕业证、学历验证报告、证书等图像中检测到证书编码区域并给出边界框。\n **注意**:仅以给定格式返回检测结果,不要给出其它任何解释。\n **注意**:若图片中没有典型违章场景,返回<ref> class_name </ref><box>[[0, 0, 0, 0]]</box>即可。\n ", "query": "请目标检测图像中的证书编码并给出边界框", "response": "<ref>zs_code</ref><box>[[455,1272,1083,1356]]</box>", "images": "/home/super/lyq/zsbm_mbjc/data/train/pic/xxx-本科毕业证.jpg"}
{"system": "职位:你是一个面向证书图像的目标检测大师,具备精准识别、定位图像中证书编码的能力。\n 职能:从毕业证、学历验证报告、证书等图像中检测到证书编码区域并给出边界框。\n **注意**:仅以给定格式返回检测结果,不要给出其它任何解释。\n **注意**:若图片中没有典型违章场景,返回<ref> class_name </ref><box>[[0, 0, 0, 0]]</box>即可。\n ", "query": "请目标检测图像中的证书编码并给出边界框", "response": "<ref>zs_code</ref><box>[[90,484,329,508]]</box>", "images": "/home/super/lyq/zsbm_mbjc/data/train/pic/xxx-本科毕业证.jpg"}
其中内容大概如上,人名已脱敏。
数据集于swift框架进行注册:
可参考我的历史文章
https://blog.csdn.net/qq_43128256/article/details/140314241
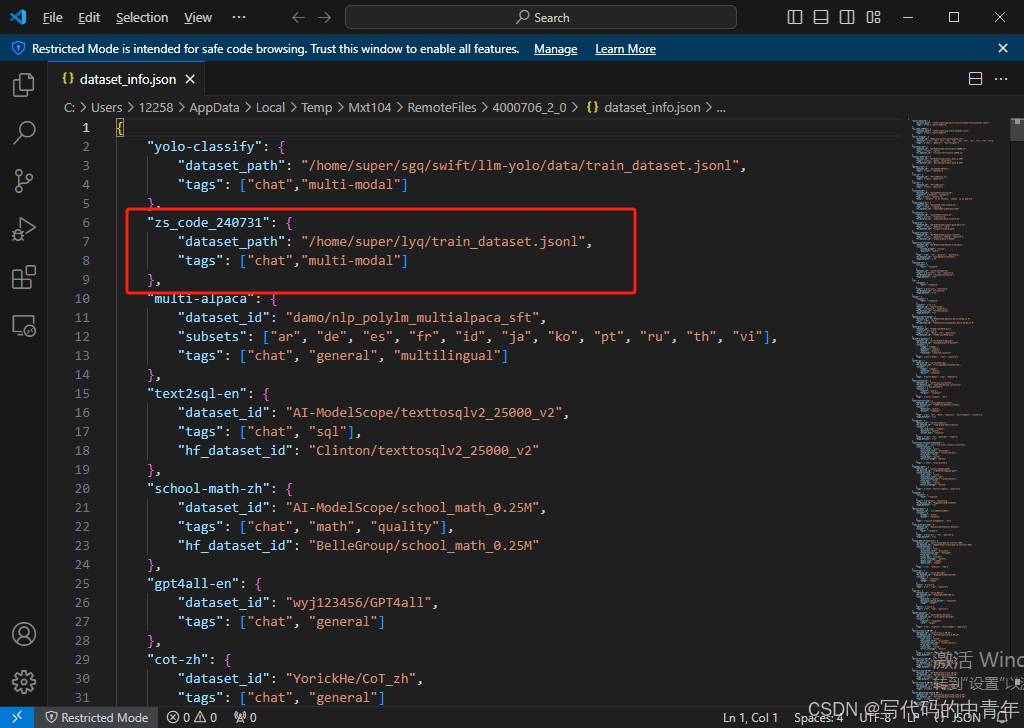
本文不再采取UI,纯指令如下:
CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_id_or_path /data/hfd/InternVL2-8B \
--template_type internvl2 \
--dataset /home/super/lyq/train_dataset.jsonl \
--lora_target_modules ALL \
--lora_lr_ratio 16.0 \
--lora_rank 16 \
--learning_rate 1e-4 \
--num_train_epochs 5 \
--use_flash_attn True \
--gradient_accumulation_steps 4 \
--batch_size 2 \
--eval_steps 50 \
--save_steps 500 \
--neftune_noise_alpha 5 \
--model_type internvl2-8b \
--device_max_memory 15GB 15GB 15GB 15GB \
--output_dir /home/super/sgq/swift/llm-yolo/detection2/v1 \
--logging_dir /home/super/sgq/swift/llm-yolo/detection2/v1/runs
其中需注意:
–model_id_or_path /data/hfd/InternVL2-8B
该参数为模型路径
–dataset /home/super/lyq/train_dataset.jsonl
该参数为微调数据集
–num_train_epochs 5
该参数为训练轮次,视情况调整
–use_flash_attn True
加速项,服务器未配置可不选
–output_dir /home/super/sgq/swift/llm-yolo/detection2/v1
为训练结果保存路径,结果包含微调训练参数和精度损失记录等
–logging_dir /home/super/sgq/swift/llm-yolo/detection2/v1/runs
为tensorboard查看结果内容存储路径
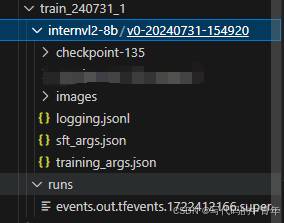
结果如上,其中checkpoint-135为训练后的lora权重;images为训练曲线;其他文件为训练参数。

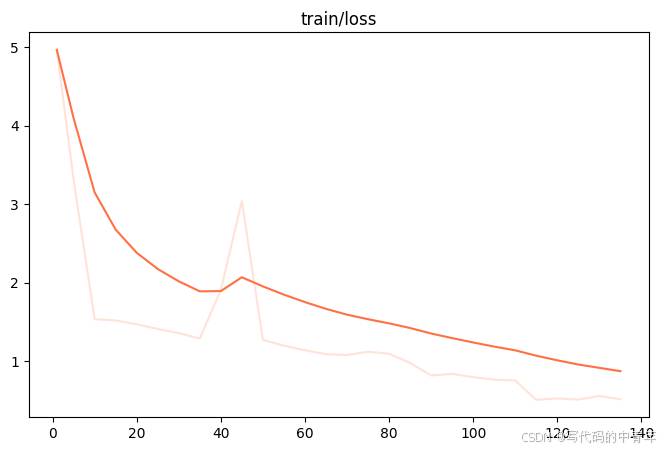
CUDA_VISIBLE_DEVICES=0,1,2,3 swift export --ckpt_dir '/home/super/lyq/zsbm_mbjc/train_240731_1/internvl2-8b/v0-20240731-154920/checkpoint-135' --merge_lora true
生成合并模型:
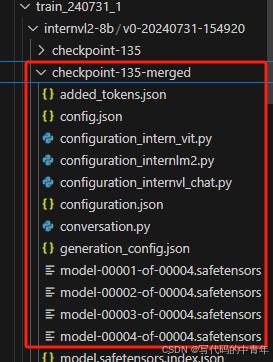
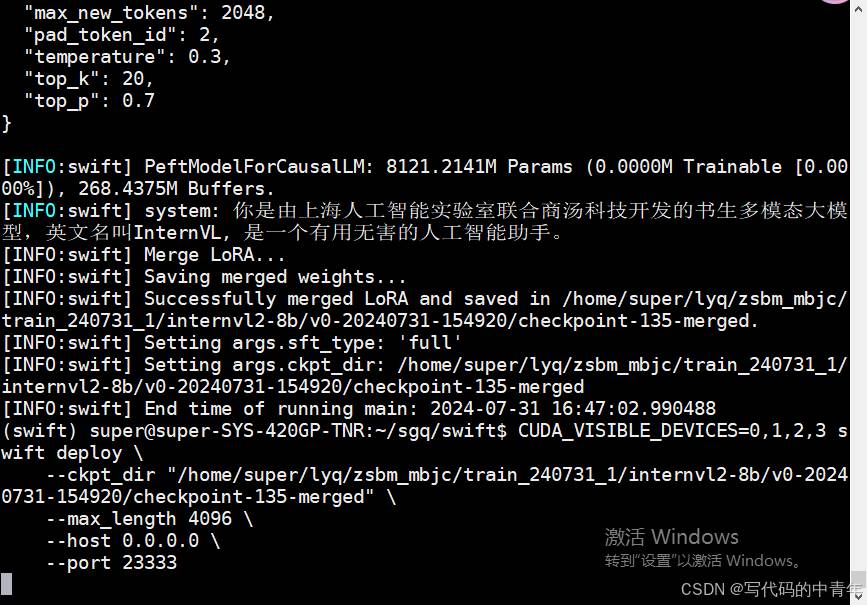
api_ask.py
from openai import OpenAI
import base64
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://172.20.32.127:23333/v1')
model_name = client.models.list().data[0].id
#图片转base64函数
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
#原图片转base64
def get_response(input_image_path):
base64_image = encode_image(input_image_path)
response = client.chat.completions.create(
model=model_name,
messages=[
{
"role": "system",
"content": '''职位:你是一个面向证书图像的目标检测大师,具备精准识别、定位图像中证书编码的能力。
职能:从毕业证、学历验证报告、证书等图像中检测到证书编码区域并给出边界框。
**注意**:仅以给定格式返回检测结果,不要给出其它任何解释。
**注意**:若图片中没有典型违章场景,返回<ref> class_name </ref><box>[[0, 0, 0, 0]]</box>即可。
'''
},
{
"role": "user",
"content":[
{
"type": "text",
"text": '请目标检测图像中的证书编码并给出边界框'
},
{
"type": "image_url",
"image_url":{
"url":f"data:image/jpeg;base64,{base64_image}"
# "url": 'https://i-blog.csdnimg.cn/direct/253ad27104b7466792511f78e9f636a9.png'
}
},
]
}
],
temperature=0.8,
top_p=0.8)
return response.choices[0].message.content
get_llm_response.py
import json
import api_ask as llm_api
def read_jsonl(file_path):
"""
Read a JSONL file and return a list of dictionaries.
:param file_path: Absolute path of the JSONL file to be read.
:return: List of dictionaries representing the JSON objects in the file.
"""
data = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
data.append(json.loads(line))
return data
data = read_jsonl('/home/super/lyq/test_dataset.jsonl')
result = []
for single_data in data:
img_path = single_data['images']
single_result = llm_api.get_response(img_path)
print(single_result)
result.append({'images':img_path,'response':single_result})
import pandas as pd
pd.DataFrame(result).to_excel('llm_response.xlsx',index=False)
结果如下图:
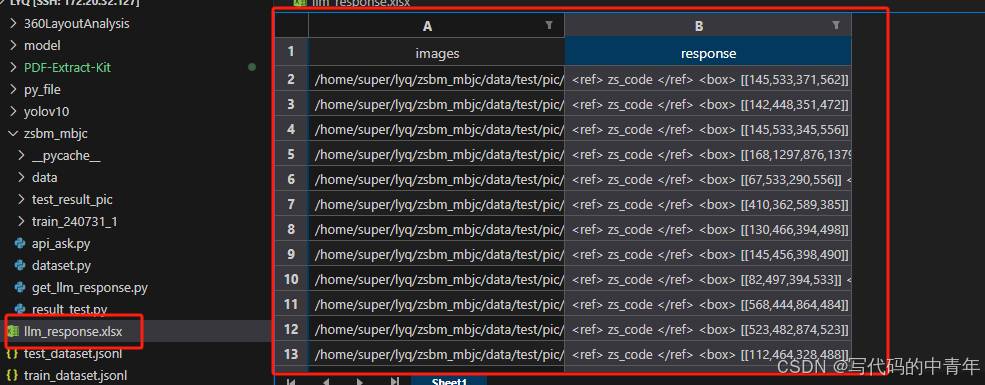
result_test.py
import pandas as pd
from PIL import Image, ImageDraw
import re
import json
from PIL import Image, ExifTags
# 添加这个函数来处理图片方向
def correct_image_orientation(image):
try:
for orientation in ExifTags.TAGS.keys():
if ExifTags.TAGS[orientation] == 'Orientation':
break
exif = dict(image._getexif().items())
if exif[orientation] == 3:
image = image.rotate(180, expand=True)
elif exif[orientation] == 6:
image = image.rotate(270, expand=True)
elif exif[orientation] == 8:
image = image.rotate(90, expand=True)
except (AttributeError, KeyError, IndexError):
# 如果没有EXIF信息,就不做任何处理
pass
return image
def draw_rectangle(image_path, coordinates, output_path):
"""
在图像上标出矩形框。
:param image_path: 图像的路径
:param coordinates: 包含矩形框坐标的列表,格式为 [x1, y1, x2, y2]
:param output_path: 输出图像的路径
"""
# 打开图像
with Image.open(image_path) as img:
img = correct_image_orientation(img)
img = correct_image_orientation(img)
# 创建一个可以在给定图像上绘图的对象
draw = ImageDraw.Draw(img)
# 计算矩形的左上角和右下角坐标
x1, y1, x2, y2 = coordinates
# 在图像上绘制矩形
draw.rectangle([x1, y1, x2, y2], outline="red", width=2)
# 保存修改后的图像
img.save(output_path)
def extract_string(s):
"""
从给定的字符串中提取方括号内的内容。
:param s: 包含方括号的字符串
:return: 提取出的字符串
"""
# 使用正则表达式匹配方括号内的内容
match = re.search(r'\[(.*?)\]', s)
if match:
# 提取匹配的内容
extracted_str = match.group(0)
return eval(extracted_str+']')
else:
return None
def read_jsonl(file_path):
"""
读取JSONL文件并返回一个包含所有条目的列表。
:param file_path: JSONL文件的路径
:return: 包含JSON对象的列表
"""
data = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
data.append(json.loads(line))
return data
data = pd.read_excel('/home/super/lyq/llm_response.xlsx')
images = data['images'].tolist()
responses = data['response'].tolist()
n = len(images)
print(images)
for index in range(n):
print(images[index])
img_path = images[index]
zuobiao = extract_string(responses[index])
draw_rectangle(img_path,zuobiao[0],'/home/super/lyq/zsbm_mbjc/test_result_pic'+'/'+img_path.split('/')[-1])
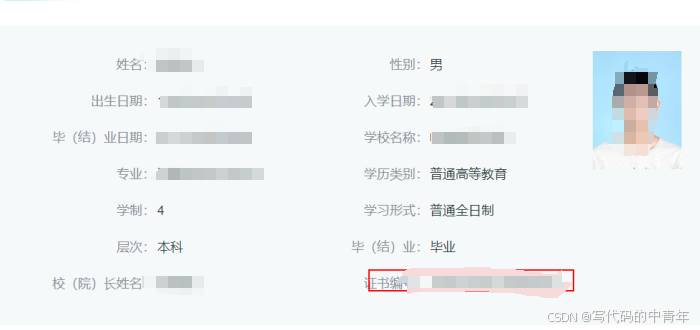
实际上,interVL2-8B多模态大模型在该任务上微调后的表现并不好。与此同时,我们还就电力巡检场景进行了微调测试,精度达到了80左右,其实也比较一般,综合来看,大模型其实并不那么擅长目标检测。
此处引申一个结论,大模型在分类任务上表现则好得多,且提升精度微调是必要的。
最近做了实验,测试集微调前精度57%,微调后97%,不过面向的是单轮问答。
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码