随着深度学习、大数据、人工智能、AI等技术领域的不断发展,机器学习是目前最火热的人工智能分支之一,是使用大量数据训练计算机程序,以实现智能决策、语音识别、图像处理等任务。各行各业都在积极探索这些技术的应用。特别是在深度学习领域,英伟达(NVIDIA)作为国内主流的深度学习框架,为这些技术的落地提供了强大的支持, 怎么样结合自身公司业务打造一个AI智能平台呢?
【可以来看看我在B站录的一个视屏】:
【NVIDIA NIM黑客松训练营】基于英伟达(NVIDIA) NIM 平台应用助力电商企业AI海报文案和AI客服最佳实践落地【NVIDIA NIM黑客松训练营
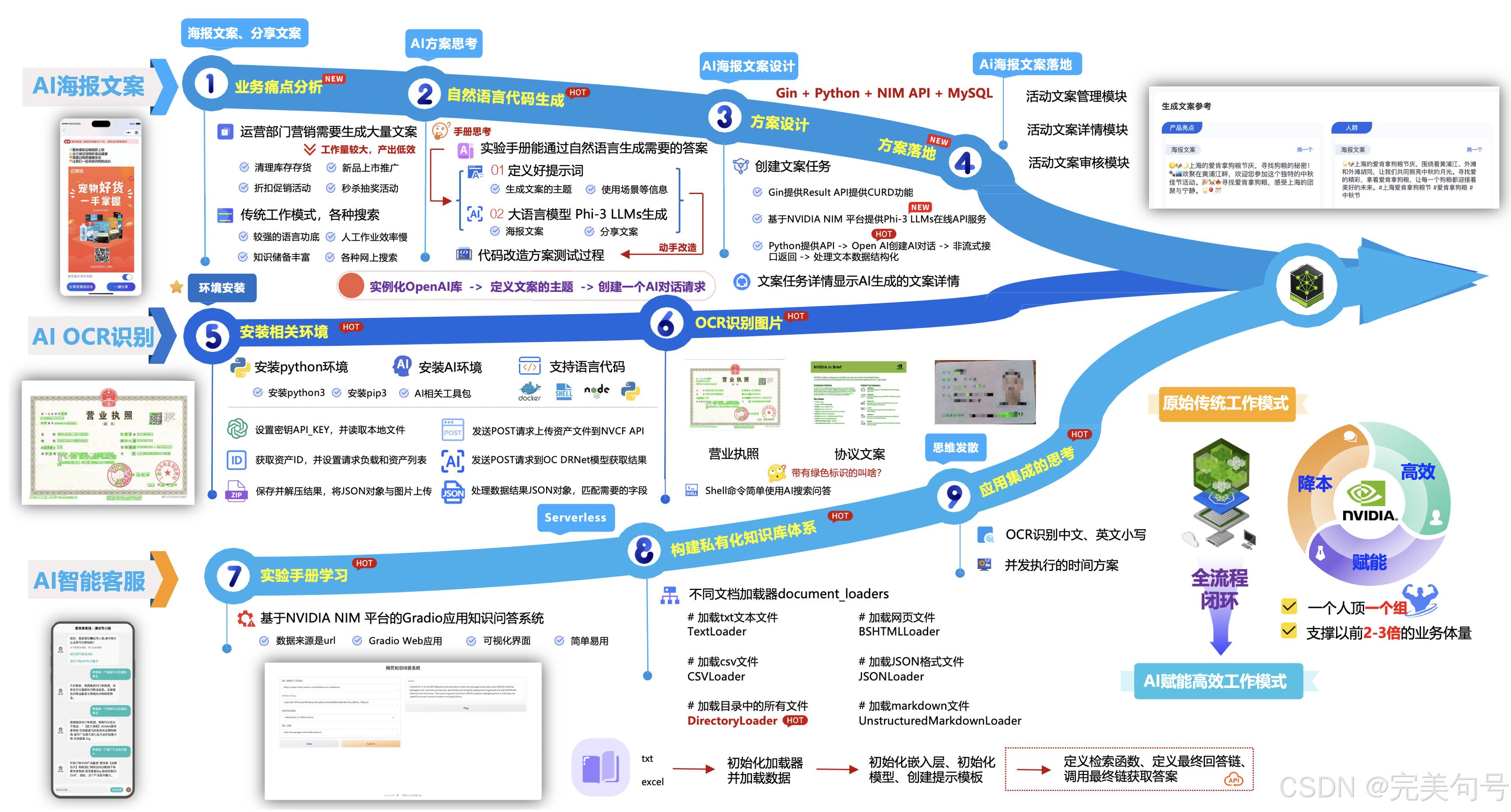
通过基于NVIDIA NIM 平台大语言模型 Phi-3 LLMs来进行提示词文案解析再生成相关内容,可以通过AI生成海报与分享文案提高文案编辑人员的效率,降低人力成本。
结合基于NVIDIA NIM 平台大的光学字符检测OCDRNet,提供的开箱即用的AI 大模型,降低数据使用门槛,业务人员通过自然语言AI对话即可完成围绕业务指标的分析和洞察,对话内容可保存成文档用于工作汇报,或创建仪表盘进行持续的数据变化跟踪,大幅提升工作效率。

结合基于NVIDIA NIM 平台llama-3_1的AI大模型,通过结合自己的私有知识库和自然语言处理等先进技术,实现与客户之间的自然语言交互,从而提供高效、便捷的客户服务。可以快速响应客户请求,有效解决客户问题,提升服务效率,同时,帮助企业实现自动化办公,降低运营成本。
作者也是经过了以上几个阶段的软件开发阶段历程,从最早期在学校和刚入行时,使用的Web时代编程(PHP LNMP环境)、到后面使用云时代分布式编程,到如今的AI时代,传统编程是人类程序员手动编写代码来实现特定的功能,而机器学习是通过让计算机程序从数据中学习,自动地提取特征和规律来实现功能。

那么,在实际的工作中如何快速的让开发人员实现AI的功能呢?
今天给大家推荐的一款,【NVIDIA NIM】提供了强大的工具和灵活的部署选项,让生成式 AI 模型的开发和应用变得更加高效和便捷。无论您是初学者小白还是资深开发者老鸟,都可以使用NIM 都能轻松应对 AI 推理的复杂挑战,加速创新与落地,助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用。
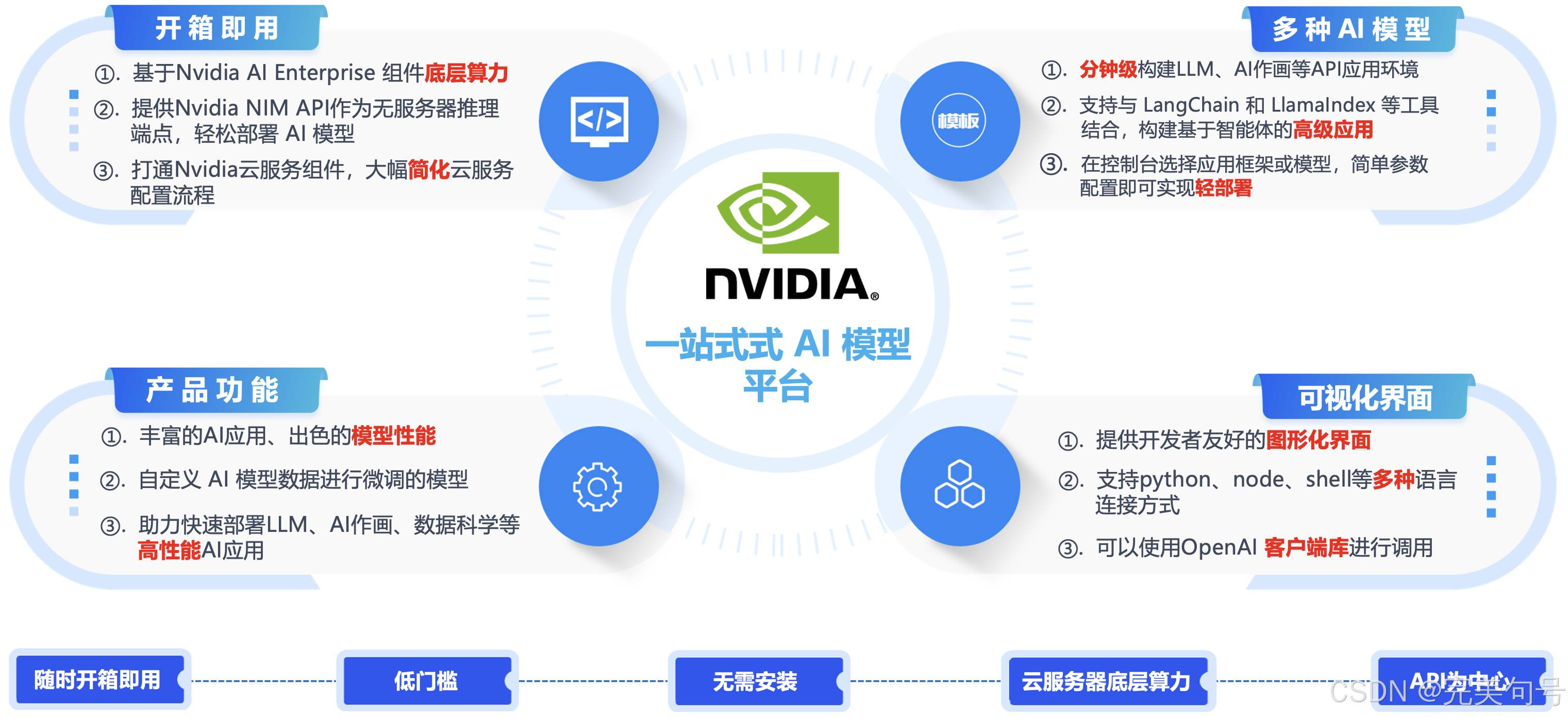
NIM(Nvidia Inference Microservices)是 NVIDIA专为生成式 AI 模型推理设计的产品,它提供了丰富的API和预训练模型,使得开发者能够快速地构建和训练深度学习模型。同时,还支持分布式训练,能够充分利用多GPU和多节点的计算资源,提高模型的训练效率。
文案内容可以帮助企业更好地推广品牌和产品,还可以帮助企业更好地说明自己的产品和服务,为潜在客户提供解决方案,从而吸引更多的客户,促进企业的发展,文案在企业社交媒体运营中具有不可或缺的作用。
互联网产品的核心点就是流量为王,为了配合公司运营活动部门,主要负责公司的活动策划与方案落地,高效的激发流量并进行转化,经常需要使用小程序中的海报功能用于业务推广,而且活动的类型也比较繁杂,比如说库存清理、新品上市、阶梯式折扣、促销活动、秒杀活动等等。
但是,想要写好海报文案和分享文案需要很多的技巧,以确保信息清晰、吸引人,并能有效传达意图。同时,也需要花费大量的时间来思考,通常运营人员需要大量百度一些文案来参考,非常的耗费时间、人力、资源。

【实验手册思维发散】:
通过对《基于NVIDIA NIM 平台的知识问答系统实验手册》的学习,发现能够通过给出一个网页的地址来源,即可以自然语言AI生成需要分析出需要的结果,那么是不是可以通过一些提示词来给AI来生成所需要的海报、分享的文案呢?顺着这个思路,马上把实验手册Demo的示例改改来实现一下,思路是如下:
Phi-3 LLMs是一个轻量级 具有强大的数学和逻辑推理能力大语言模型,其强大的推理能力和逻辑能力使其成为内容生成、摘要、问答和情感分析任务的理想选择。
在查看手册提示的示例代码时,发现主要逻辑还是在OpenAI和client.chat.completions.create这二块代码逻辑上,经过对代码的研究和不断的优化相关提示词的实践过程,最终,改造为以下的代码逻辑后,即可通过大语言模型 Phi-3 LLMs生成了一些符合要求的文案(是一个持续迭代优化提示词的过程):
# 导入OpenAI库
from openai import OpenAI
# 初始化OpenAI客户端,配置base_url和api_key
# base_url指向NVIDIA的API服务
# api_key是用于身份验证的key,如果在NGC外部执行则需要提供
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "$API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC"
)
request := “创意主题是上海城市需要进行爱肯拿狗粮的中秋活动,需要生成海报文案,文案需要包括上海的一些地标名称,文案需要包含表情符号”
# 创建聊天完成请求
# 选择使用microsoft的phi-3-mini-4k-instruct模型
# 请求内容是生成一首关于GPU计算奇迹的limerick诗
# 设置生成参数:temperature控制随机性,top_p控制多样性,max_tokens限制最大生成长度,stream设置为True以流式接收结果
completion = client.chat.completions.create(
model="microsoft/phi-3-mini-4k-instruct",
messages=[{"role":"user","content": request}],
temperature=0.2,
top_p=0.7,
max_tokens=1024,
stream=True
)
# 流式处理生成的结果
# 遍历每个返回的块,检查内容是否非空并逐块打印
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
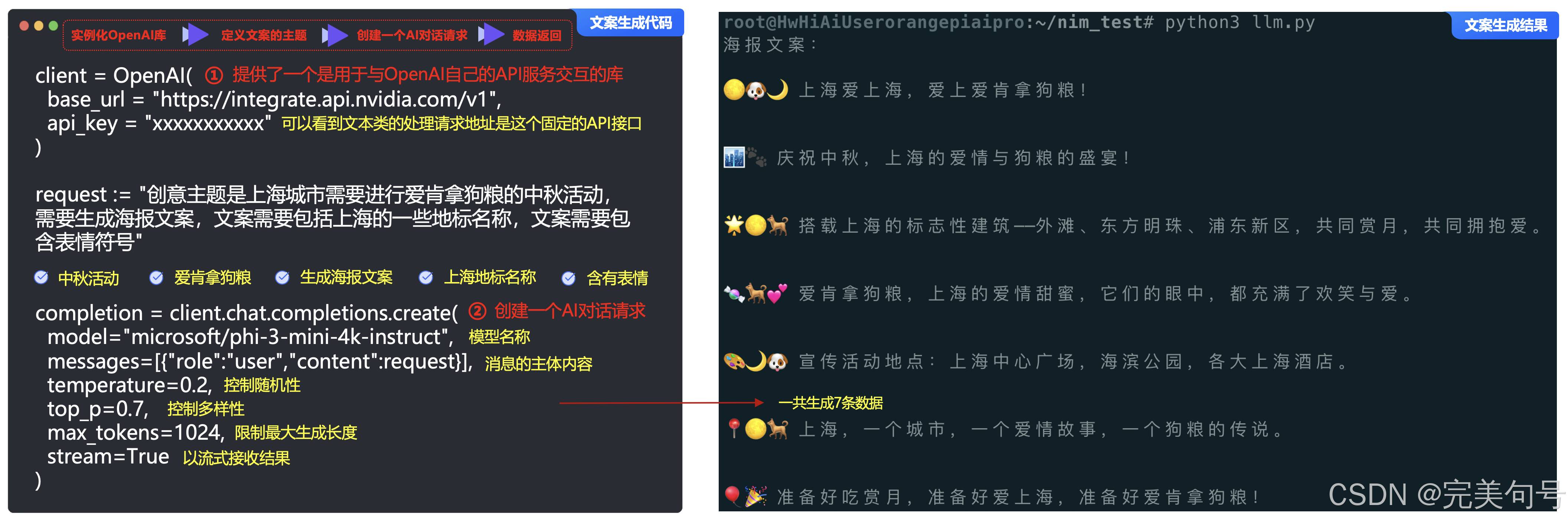
最终在修改手册提供的代码后,通过传入不同的主题提示词来生成不同的文案:
“创意主题是上海城市需要进行爱肯拿狗粮的中秋活动,需要生成海报文案,文案需要包括上海的一些地标名称,文案需要包含表情符号”
上面只是一个简单的Demo演示,如果在生产环境中还是需要不断的优化“tempate” – 即AI中需要用到的Prompt(提示词)。
Prompt在自然语言处理中的应用非常广泛,从简单的问答系统到更复杂的机器翻译和文本生成,甚至包括在法律、金融和医疗领域中的应用。Prompt的设计不仅仅是简单地将问题转换为指令,而且要考虑到上下文、语法和语言风格等多个方面。
【文案生成方案落地】:
NIM生态系统提供了一系列预训练的AI模型,覆盖了多个领域,包括文本处理、语音合成、三维场景创建、机器人技术以及数字生物学等。这些模型作为优化的“容器”,可以快速部署在云端、数据中心或工作站上,极大地加速了AI应用的开发和部署,助力中小企业及开发者快速部署 LLM。

打开(https://build.nvidia.com/microsoft/phi-3-mini-4k)[大语言模型 Phi-3 LLMs]链接可以模型介绍页面,这里支持多种 AI 环境快速部署,如Python、LangChain、Node、Shell、Docker等,使用户可专注业务及应用场景创新。
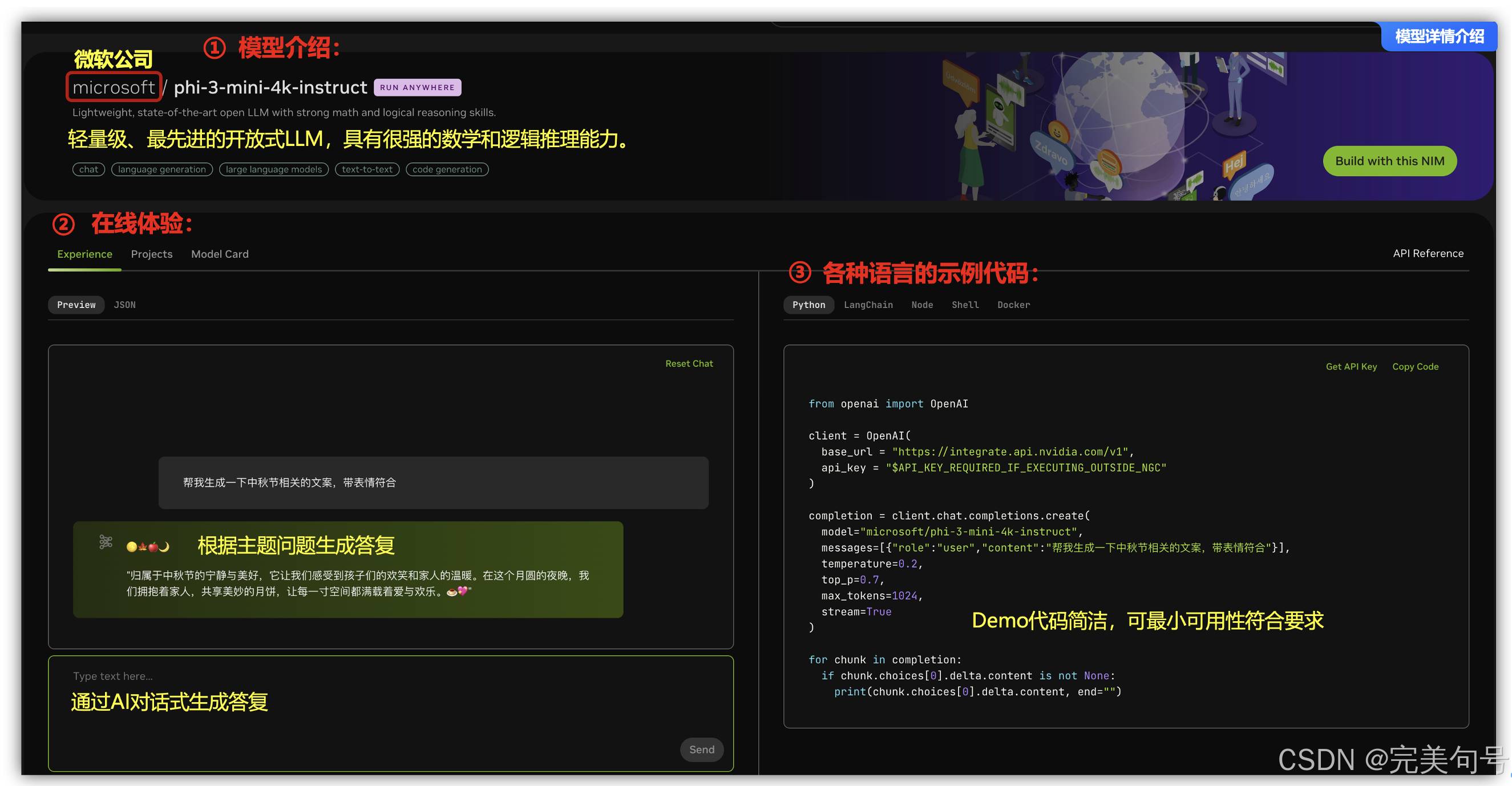
NVIDIA NIM 平台拥有丰富的预装应用,可以将开源社区的前沿模型快速转化为您专有的部署实践,一键拉起,即开即用。直接在找到模型,点击查看详情,就可以显示每个模型的详细资料,比如我们找到大语言模型Phi-3 LLMs等应用的入口,即可得到一个简单易用的API推理服务平台脚本。
Phi-3 LLMs是微软发布的一系列开源AI模型,旨在重新定义小型语言模型(SLMs)的可能性,Phi-3 LLMs是微软推出的一系列高性能、高效且安全的开源AI模型,特别适用于小型语言模型场景。
Phi-3模型以卓越的性能和高效的成本著称,超越了同等大小和稍大一号的模型,在各种语言、推理、编码和数学基准测试中表现优异。该系列包括多个模型,其中Phi-3-mini拥有38亿参数,可在Microsoft Azure AI Studio、Hugging Face和Ollama等平台上使用,与此同时,该项目也支持 OpenAI GPT API 的调用。
在模型的详情中其实已经很明显了,可以在示例代码中,有一个“Get API Key”的按钮,点击后,有一个生成确认的弹框,提示此key验证是否可以尝试具有托管端点的NIM,以启动开发、测试和集成。
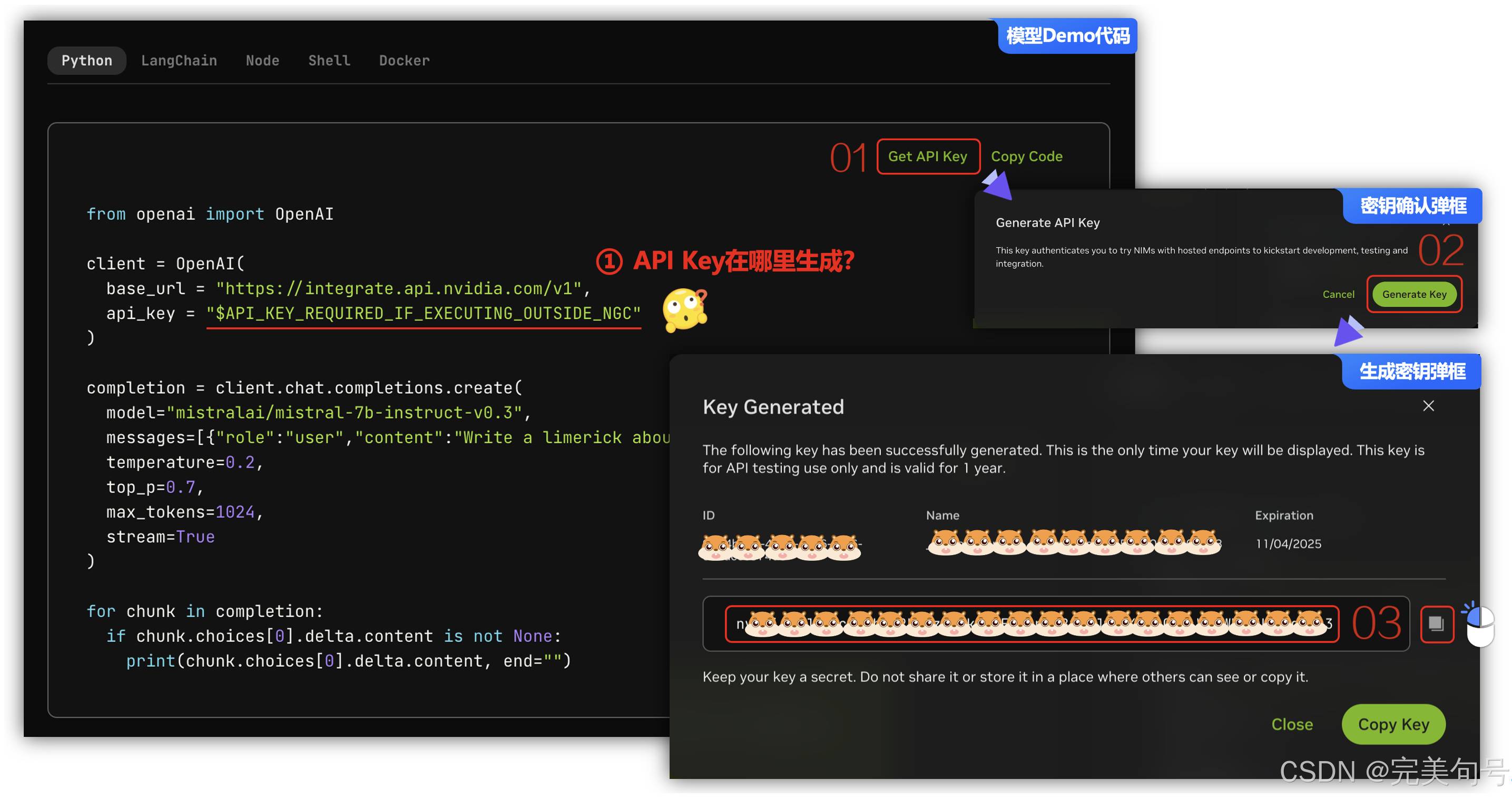
在点击“Generate Key”key后,再给出一个弹框表示已成功生成以下key,这是唯一一次显示key,此key仅供API测试使用,有效期为1年(我们看到有效期是到了2015/11/04号)。所以,最好是保管好key,否则遗失或忘记后只能重新生成用于覆盖重置了。

以上就是如果进行API Key重置后,就会报错,提示:openai.AuthenticationError: Error code: 401 - {‘status’: 401, ‘title’: ‘Unauthorized’, ‘detail’: ‘invalid response from UAM’},表示这个错误表明尝试访问OpenAI的API服务时出现了身份验证问题,HTTP状态码401 Unauthorized意味着服务器认为客户端没有提供正确的认证信息。
Traceback (most recent call last):
File "llm.py", line 16, in <module>
completion = client.chat.completions.create(
File "/usr/local/lib/python3.8/dist-packages/openai/_utils/_utils.py", line 274, in wrapper
return func(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/openai/resources/chat/completions.py", line 704, in create
return self._post(
File "/usr/local/lib/python3.8/dist-packages/openai/_base_client.py", line 1270, in post
return cast(ResponseT, self.request(cast_to, opts, stream=stream, stream_cls=stream_cls))
File "/usr/local/lib/python3.8/dist-packages/openai/_base_client.py", line 947, in request
return self._request(
File "/usr/local/lib/python3.8/dist-packages/openai/_base_client.py", line 1051, in _request
raise self._make_status_error_from_response(err.response) from None
openai.AuthenticationError: Error code: 401 - {'status': 401, 'title': 'Unauthorized', 'detail': 'invalid response from UAM'}
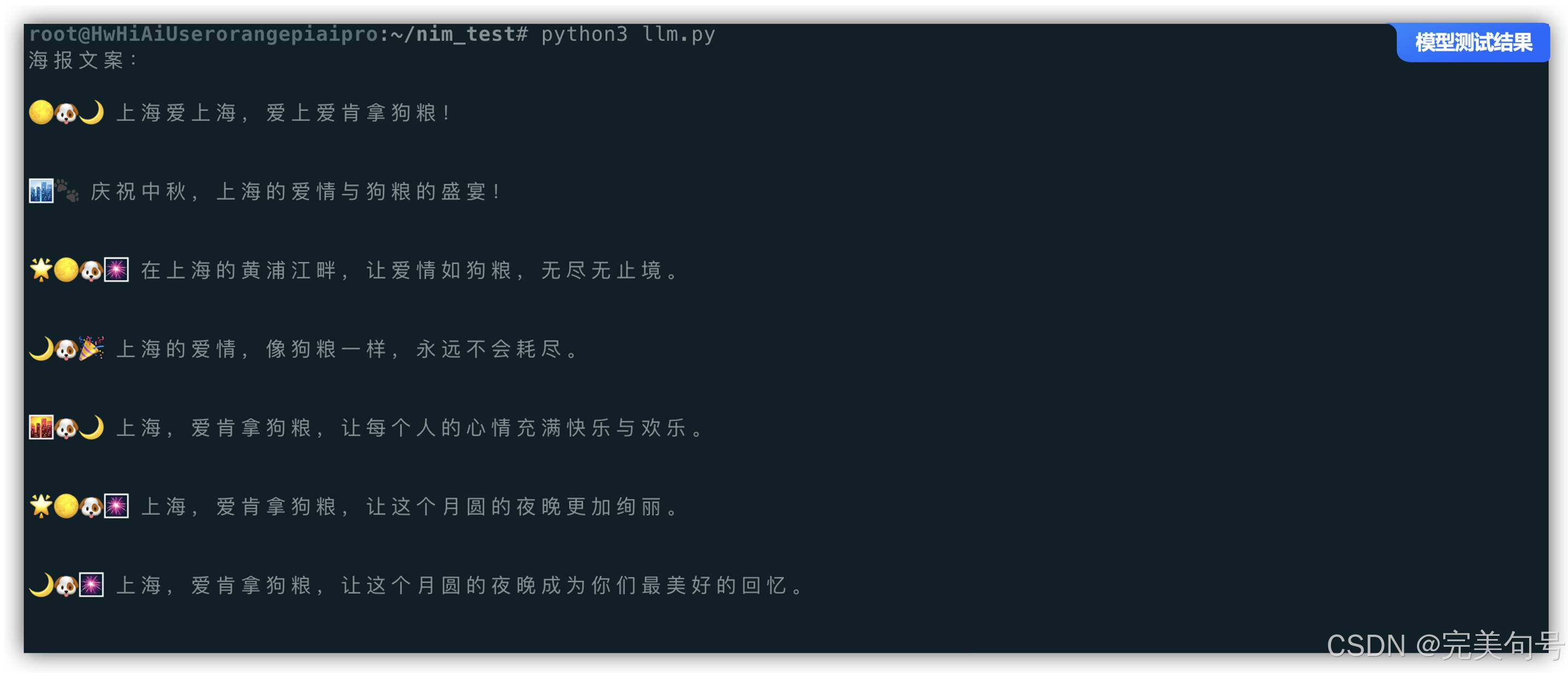
接下来经过输入不同的主题文案,来优化模型,得到更为贴近符合要求的文案,经过一些测试后,可以看到使用代码可以帮我们生成需要的文案格式代码,而且还有带表情符号的文案。
上面已经部署了大语言模型 Phi-3 LLMs,现在根据活动主表,生成不同的任务,这些任务是有任务流程的,比如说文案环节就是编辑文案和确认文案,到了设计就是根据文案的内容,进行海报的设计,确认海报的内容,最终是项目人员确定发布。

相关Gin的代码,需要请求python的服务提供的NIM的Phi-3 LLMs大语言模型的API服务,从而拿到AI生成的文案结果,将结果塞入MySQL数据库中进行存储,后续针对不符合的AI数据:
// 目标URL和POST数据
url := "https://xxxxxxx.com"
postData := []byte(`{"request": subjectMessage }`)
// 发送POST请求
resp, err := http.Post(url, "application/json", bytes.NewBuffer(postData))
if err != nil {
panic(err)
}
defer resp.Body.Close()
// 检查HTTP状态码
if resp.StatusCode == http.StatusOK {
// 读取响应体
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
panic(err)
}
// 解析响应数据
var response NIMResponseData
err = json.Unmarshal(body, &response)
if err != nil {
panic(err)
}
// 检查返回码是否为20000
if NIMResponseData.Code == 20000 {
// 创建数据库记录
record := TaskDetails{
ID: Task.ID,
PosterText: NIMResponseData.Result,
}
// 将记录保存到数据库
db.Create(&record)
fmt.Println("Record saved to database")
} else {
fmt.Printf("Response code is not 200, it's %d\n", response.Code)
}
} else {
fmt.Printf("HTTP request failed with status code %d\n", resp.StatusCode)
}
以下为Python提供的相关代码,因为我们的代码是API接口的形式,所以,不能使用传统的流式是数据以连续的数据流形式输出,而不是一次性生成完整的结构化数据。需要将stream参数改为False,再接收数据。

以下为返回的数据:
ChatCompletion(id='cmpl-a1ff1550715342aab70e4274fc86a054', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='🌕🐶🌙上海的爱肯拿狗粮节庆,围绕着黄浦江、外滩和外滩胡同,让我们共同照亮中秋的月光。寻找爱的精彩,拿狗粮的盛宴,让每一个爱的环节都充满欢乐与温馨。#上海爱肯拿狗粮节 #中秋节 #爱情 #精彩 #上海', refusal=None, role='assistant', function_call=None, tool_calls=None), stop_reason=None)], created=1730775633, model='microsoft/phi-3-mini-4k-instruct', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=189, prompt_tokens=96, total_tokens=285, completion_tokens_details=None))
从返回的结果对象数据结构中来看:
# 定义一个API接口,接受POST请求
@app.route('/api/getAiPoster', methods=['POST'])
def getAiPoster():
if not request.is_json:
return jsonify({
"code": "410000",
"message": "参数请求必须为application/json",
"subMessage": None,
"result": "",
"success": True
}), 400
# 解析JSON数据
data = request.json
// AI处理逻辑
completion = client.chat.completions.create(
model="microsoft/phi-3-mini-4k-instruct",
messages=[{"role":"user","content": data['subjectMessage']}],
temperature=0.2,
top_p=0.7,
max_tokens=1024,
stream=False
)
response = {
"code": "200000",
"message": "消息处理成功",
"subMessage": None,
"result": completion.choices[0].message.content,
"success": True
}
return jsonify(response), 200 # 返回JSON响应和状态码200
以下为使用postman工具,可以进行接口的测试,可以通过发送POST请求访问上面python的代码生成的AI海报文案的接口响应。

通过对基于NVIDIA NIM 平台的大语言模型 Phi-3 LLMs结合起来,可以使用AI的文本处理的能力来完成一个AI海报文案、分享文案的实践,从而提高运营文案产出的效率,可以降低人工的成本。
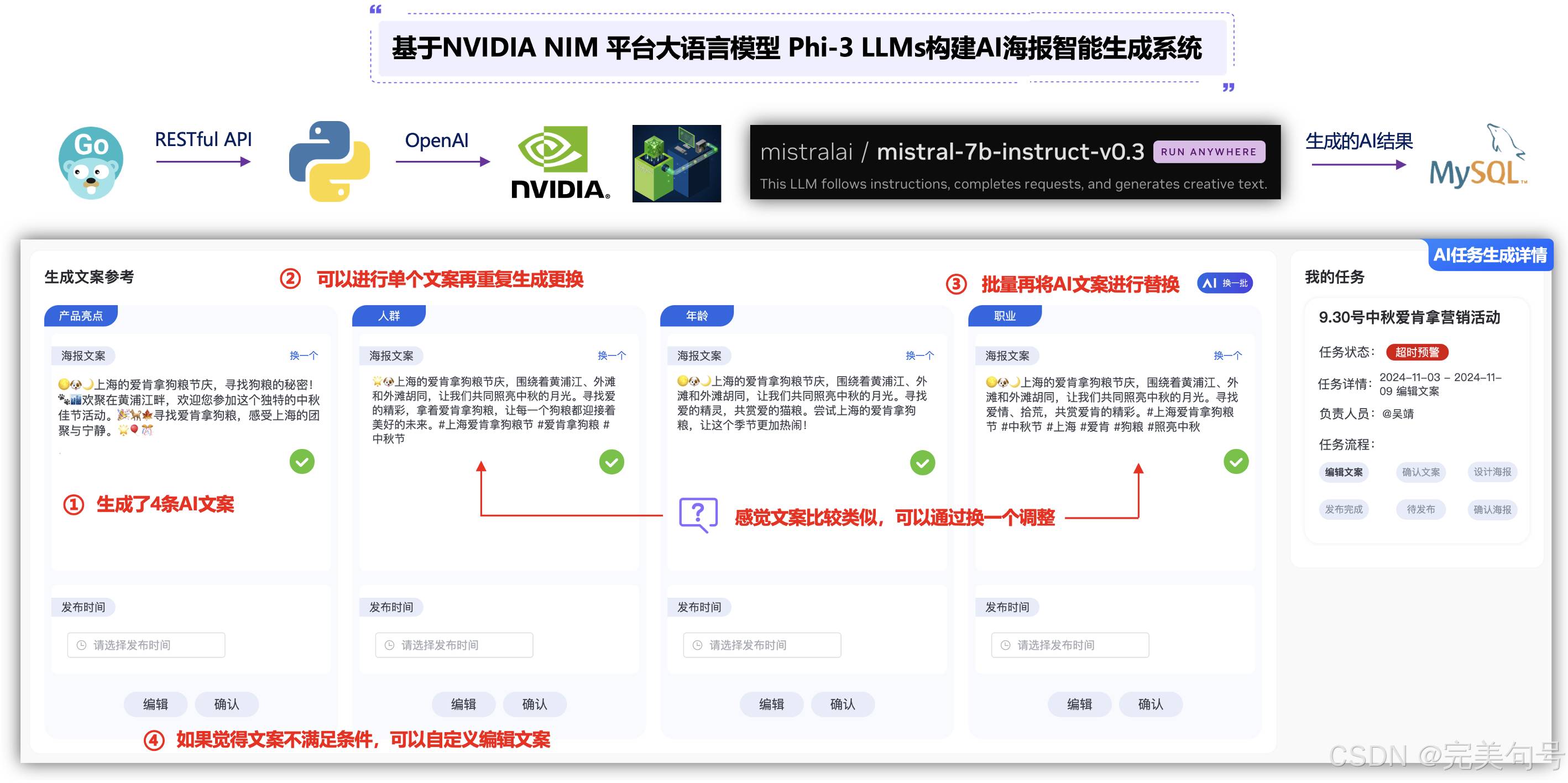
随着图片资源时代的飞速发展,将文字内容转化为图片形式进行发布和存储的做法越来越普遍。大量的文字内容为了更好的排版和表现效果,都采用了图片的形式发布和存储,这为内容的传播和安全性带来了很大的便利,同时也增加了文字识别作业的重复性劳动。
OCR文字AI在线识别工具也逐渐的应运而生,主要是为了帮助用户解决了内容编辑的难题,对于包含大量文字的图片或文档,手动输入既耗时又易出错。OCR工具的出现,大大减轻了这一负担,用户只需上传图片,即可快速获取可编辑的文本内容。
目前OCR技术正在被广泛的运用,刚好接触了基于NVIDIA NIM平台提供的OCDRNet光学字符检测大模型,就是一款运用OCR的技术,可以帮助企业解决一些文字录入业务的痛点,为公司进行增效降本。

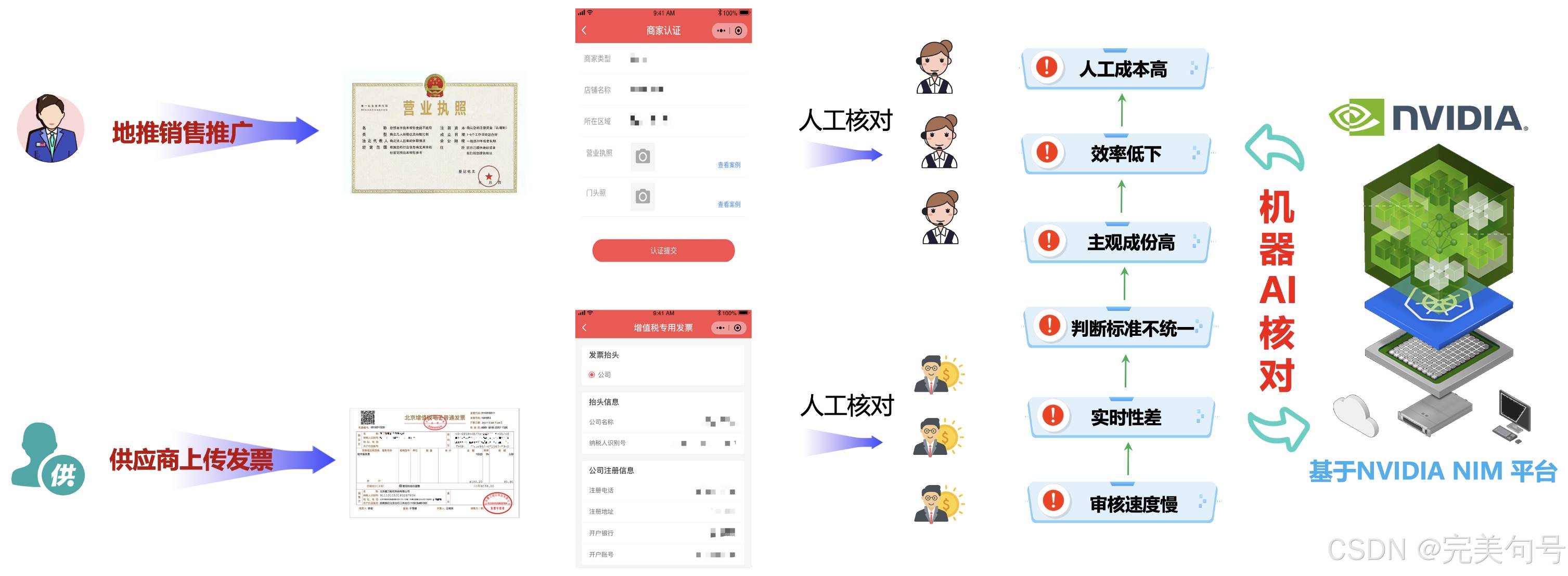
【场景一:】公司地推业务员,需要去宠物店进行登记授权店铺可以销售本公司的产品,也可以为公司拓展客户的目的,公司客服部门专门需要对业务员地推的提交的信息进行审核,同时,也为业务的考核进行评定。
【场景二:】供应商在采购后,需要将开立的发票进行公司交账。
首先项目中需要使用到python3的环境,并且需要使pip包管理工具可以进行安装一些python的库与包,以下为安装命令:
apt install -y python3
apt install -y python3-pip
pip3安装相关的包与库:
pip3 install openai
在安装完成需要的软件完成后,可以使用pip3 list来查看所有的安装过的python包。
根据官方提供(https://build.nvidia.com/nvidia/ocdrnet?snippet_tab=Python)的测试脚本,可以用于光学字符检测和识别的预训练模型,开发者可以选择适合其需求的预训练模型进行光学字符检测和识别,这些模型在准确性、效率和灵活性方面都有所保证,能够助力各种OCR应用场景的实现。
import os
import sys
import uuid
import zipfile
import requests
# NVCF API 的OC DRNet模型端点
nvai_url = "https://ai.api.nvidia.com/v1/cv/nvidia/ocdrnet"
# 授权头,需要API key,如果在NGC之外执行
header_auth = f"Bearer $API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC"
def _upload_asset(input, description):
"""
上传一个资产到NVCF API。
:param input: 要上传的二进制资产
:param description: 资产的描述
:return: 资产ID(UUID对象)
"""
assets_url = "https://api.nvcf.nvidia.com/v2/nvcf/assets"
# 设置请求头
headers = {
"Authorization": header_auth,
"Content-Type": "application/json",
"accept": "application/json",
}
# 设置S3请求头
s3_headers = {
"x-amz-meta-nvcf-asset-description": description,
"content-type": "image/jpeg",
}
# 设置请求负载
payload = {"contentType": "image/jpeg", "description": description}
# 发送POST请求以获取上传URL和资产ID
response = requests.post(assets_url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
asset_url = response.json()["uploadUrl"]
asset_id = response.json()["assetId"]
# 发送PUT请求上传资产
response = requests.put(
asset_url,
data=input,
headers=s3_headers,
timeout=300,
)
response.raise_for_status()
# 返回资产ID
return uuid.UUID(asset_id)
if __name__ == "__main__":
"""
上传一张自选图片到NVCF API,并向光学字符检测和识别模型发送请求。
响应保存到本地目录。
注意:必须设置环境变量NGC_PERSONAL_API_KEY。
"""
# 检查命令行参数数量
if len(sys.argv) != 3:
print("Usage: python test.py <image> <output_dir>")
sys.exit(1)
# 上传资产并获取资产ID
asset_id = _upload_asset(open(sys.argv[1], "rb"), "Input Image")
# 设置请求负载
inputs = {"image": f"{asset_id}", "render_label": False}
# 设置资产列表
asset_list = f"{asset_id}"
# 设置请求头
headers = {
"Content-Type": "application/json",
"NVCF-INPUT-ASSET-REFERENCES": asset_list,
"NVCF-FUNCTION-ASSET-IDS": asset_list,
"Authorization": header_auth,
}
# 发送POST请求到OC DRNet模型
response = requests.post(nvai_url, headers=headers, json=inputs)
# 保存响应内容到本地ZIP文件
with open(f"{sys.argv[2]}.zip", "wb") as out:
out.write(response.content)
# 解压ZIP文件到输出目录
with zipfile.ZipFile(f"{sys.argv[2]}.zip", "r") as z:
z.extractall(sys.argv[2])
# 输出保存目录和目录内容
print(f"Output saved to {sys.argv[2]}")
print(os.listdir(sys.argv[2]))
可以直接找到官方提供了一张图片,使用wget下载下来后,我们可以查看一下Demo的代码脚本,使用python执行脚本时,命令为:
python ocr.py 本地图片的地址 下载结果的目录
这个脚本文件执行需要额外携带2个参数:


【小技巧】
因为上面生成的图片带有绿色标识的图片并不知道叫什么?可以现学现用直接使用一个shell的命令来得到结果:
curl https://integrate.api.nvidia.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC" \
-d '{
"model": "microsoft/phi-3-mini-4k-instruct",
"messages": [{"role":"user","content":"图片在AI识别显示绿色框框,这种叫什么"}],
"temperature": 0.2,
"top_p": 0.7,
"max_tokens": 1024,
"stream": false // 这里要改为false,不然就是一行一行输入
}'
在AI识别中,如果图片显示了绿色框框,这种叫做“绿色边框”或者“绿色框”。这个术语指的是一种在图像处理或图像标注中常见的元素,用于标注或区分图像中的特定区域,图片在AI识别时显示绿色框框,这种通常被称为“矩形参考线”或“矩形框”。这种绿色框框用于标记图像中的特定区域,通常用于目标检测、物体识别等任务中。

import json
import pymysql
# 连接到MySQL数据库
host = 'localhost' # 数据库主机名
port = 3306 # 数据库端口
user = 'your_username' # 数据库用户名
password = 'your_password' # 数据库密码
database = 'your_database' # 数据库名称
connection = pymysql.connect(host=host, port=port, user=user, password=password, database=database)
cursor = connection.cursor()
fileName = "40fc1704-307e-496b-903d-1c9b8d3f166c.response"
# 打开文件并读取数据
with open(fileName, 'r', encoding='utf-8') as file:
data = json.dump(file)
# 提取所有label
labels = [item['label'] for item in data['metadata']]
# 创建SQL INSERT语句并执行
for item in data:
fileNameField = fileName
sourceContent = data
labelContent = json.dump(labels)
# 构建SQL INSERT语句
sql = "INSERT INTO files (file_name, source_content, label_content) VALUES (%s, %s, %s)"
cursor.execute(sql, (fileNameField, sourceContent, labelContent))
# 提交事务
connection.commit()
# 关闭游标和连接
cursor.close()
connection.close()
print("数据已成功插入MySQL数据库!")

再通过提取的Label字段数据源可以将身份证号匹配出来,再进行业务代码逻辑的编写,这里由于涉及到企业内部的代码,将不再展示,逻辑就是循环去匹配长度为18位的身份证,位数符合要求的话,就将值取出来回填到业务数据表中。
对公司的一个降本节流的策略,做了一个预计的评估,人力的成本约减少20%左右,工作提高的效率在40%以上,做成基础的公共服务,后续有新的业务场景也可以很快的上线。
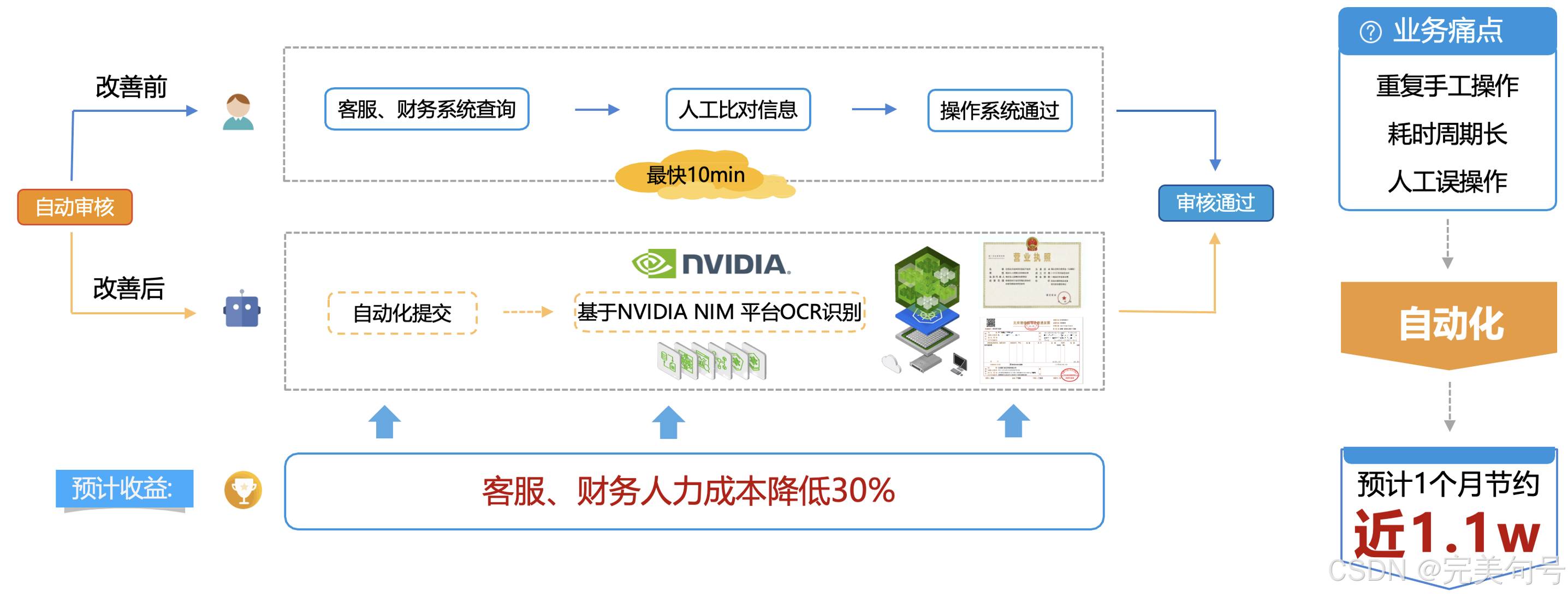
当然,需要根据公司的实际情况进行调研,比如采购的成本如果远远大于人工的成本,可能就需要进行衡量一下。

在信息社会时代,每天会产生大量的票据、表单、证件数据,这些数据想要从人工处理转变到信息电子化,基于基于NVIDIA NIM 平台的OCR文字识别和提取工具是必不可少的效率提升的利器。
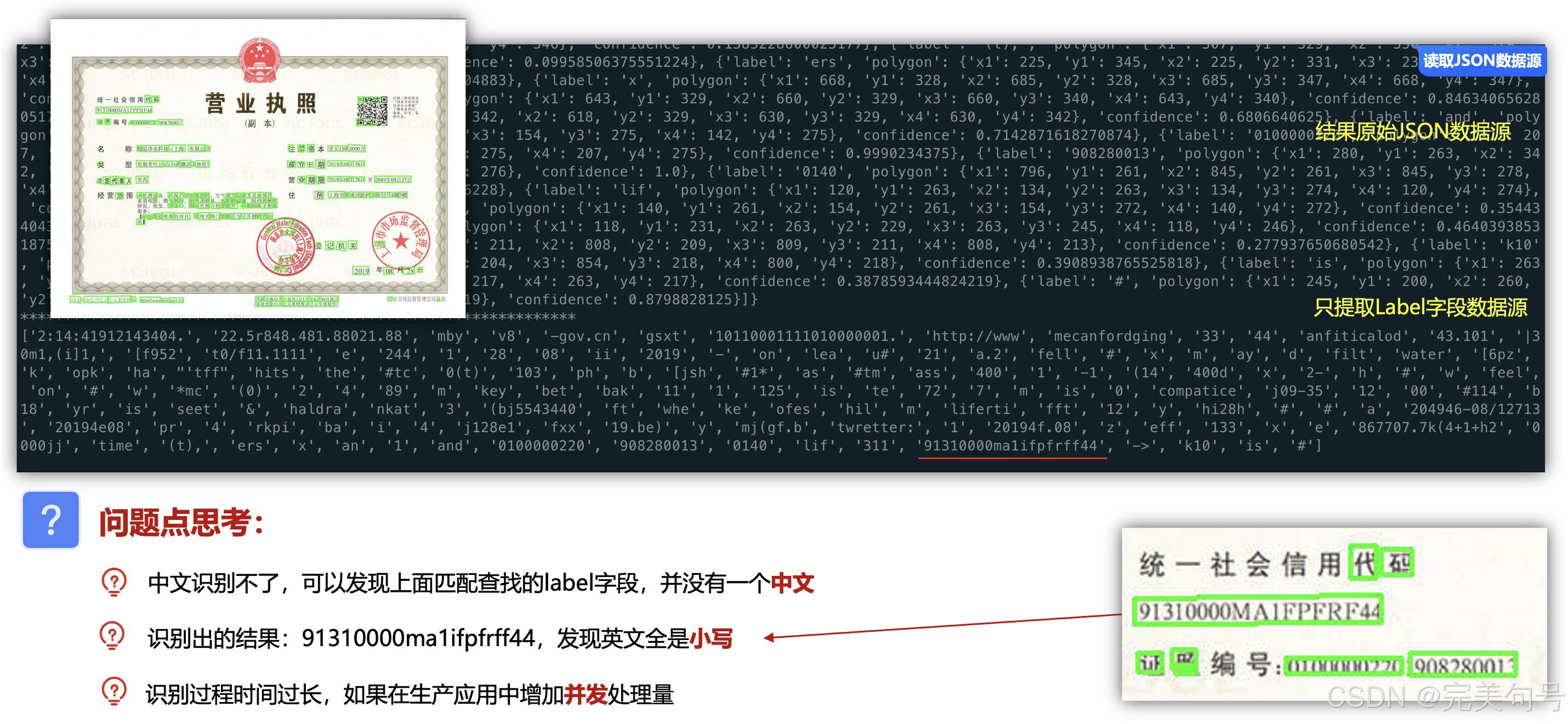
发现问题一:中文识别不了,从营业执照和身份证证件中,可以发现上面匹配查找的label字段,并没有一个中文,或者是参数是没有写对。
发现问题二:识别率还是不是太高,识别出的结果:91310000ma1ifpfrff44,发现英文全是小写,而且有多的字母。
发现问题三:识别过程时间过长,特别是文件比较大的时候,如果在生产应用中增加并发处理量。
绝大多数提供互联网应用的公司都会存在在线客服的岗位,以往客服单位需要招在大量专业人员,经过内部培训一段周期再上岗作业,往往会存在一些问题:
| 序号 | 分类 | 描述 |
|---|---|---|
| 1 | 人工座席高强负荷运转 | 人工座席无法应对高峰期海量访客,造成服务响应缓慢、排队等待过长及服务专业性不足等各种情况 |
| 2 | 核心数据外泄风险 | 人工座席能够触及的客户资料数据覆盖面广,部分敏感业务数据存在暴露风险,可能导致数据信息外泄 |
| 3 | 7*24服务 | 很多时候,客服人员在下班或者休假的时候,还要频繁工作,导致客服工作时长久 |
| 4 | 业务“Serverless化服务” | 当遇到业务比较忙时,需要招大量的人力来支撑业务发展,当业务低谷期,又需要减员来保证公司的正常支出 |
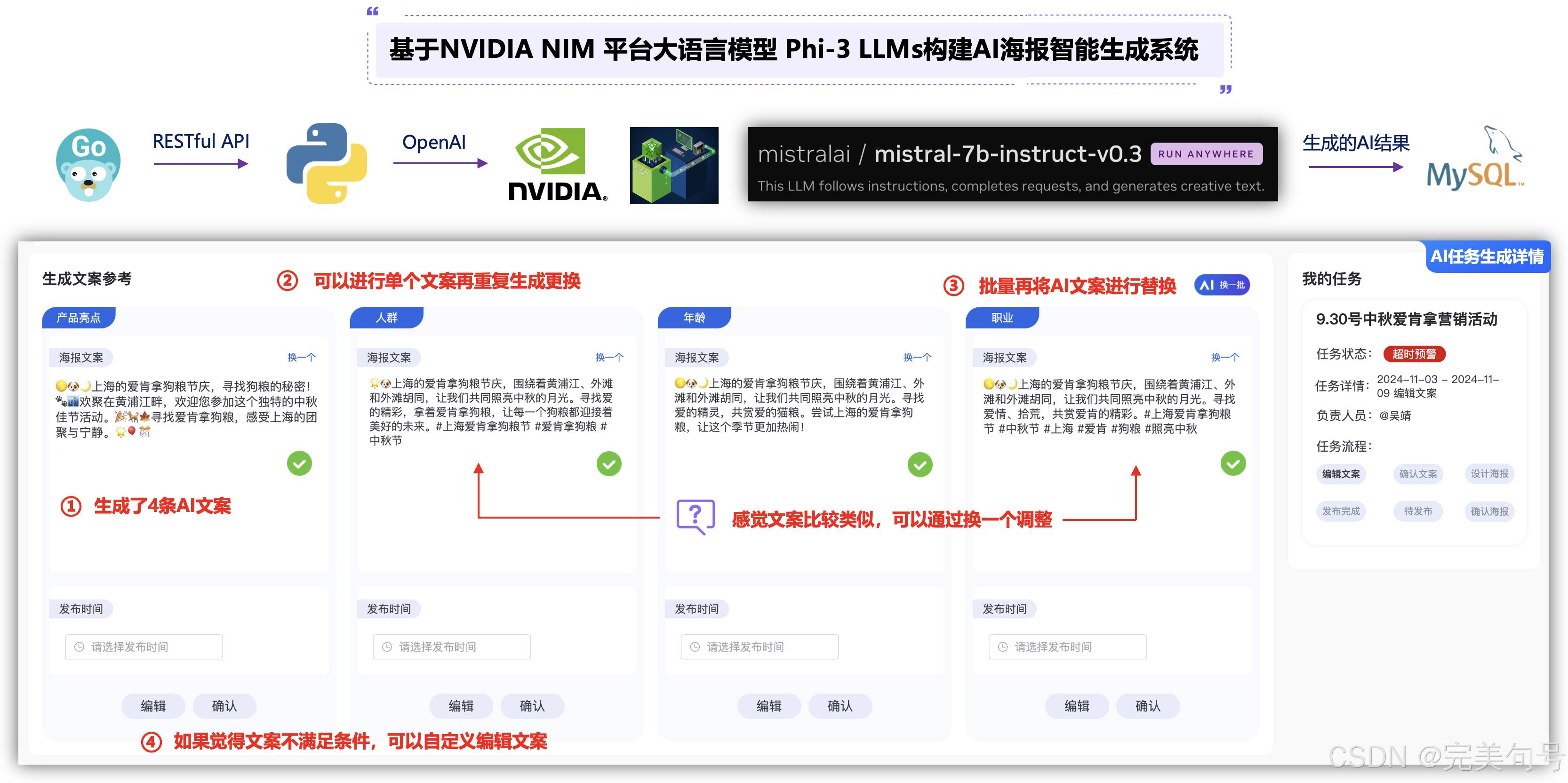
通过使用基于NVIDIA NIM 平台的llama-3_1-405b-instruct大模型实现AI智能客服系统,可以有效的通过AI的技术,为客户提供交互式服务的智能客服系统。这种系统通过自然语言处理技术、语音识别技术、机器学习技术等,能够理解客户的需求、回答客户的问题、提供解决方案等。

# -*- coding: utf-8 -*-
# 导入必要的库
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings, ChatNVIDIA
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import chain
import os
from datetime import datetime
# Even if you do not know the full answer, generate a one-paragraph hypothetical answer to the below question in Chinese
# 定义假设性回答模板
hyde_template = """Even if you do not know the full answer, generate a one-paragraph hypothetical answer to the below question:
{question}"""
# 定义最终回答模板
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
# 定义函数来处理问题
def process_question(api_key, model_name, question):
# 初始化加载器并加载数据
loader = DirectoryLoader(path="./data")
docs = loader.load()
# 初始化嵌入层
embeddings = NVIDIAEmbeddings()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)
retriever = vector.as_retriever()
# 初始化模型
model = ChatNVIDIA(model=model_name)
# 创建提示模板
hyde_prompt = ChatPromptTemplate.from_template(hyde_template)
hyde_query_transformer = hyde_prompt | model | StrOutputParser()
# 定义检索函数
@chain
def hyde_retriever(question):
hypothetical_document = hyde_query_transformer.invoke({"question": question})
return retriever.invoke(hypothetical_document)
# 定义最终回答链
prompt = ChatPromptTemplate.from_template(template)
answer_chain = prompt | model | StrOutputParser()
@chain
def final_chain(question):
documents = hyde_retriever.invoke(question)
response = ""
for s in answer_chain.stream({"question": question, "context": documents}):
response += s
return response
# 调用最终链获取答案
return str(datetime.now())+final_chain.invoke(question)
if __name__ == "__main__":
# 设置环境变量
os.environ['NVIDIA_API_KEY'] = "xxxxxxx"
try:
nvidia_api_key = os.environ['NVIDIA_API_KEY']
print(f"The NVIDIA API key is: {nvidia_api_key}")
except KeyError:
print("NVIDIA_API_KEY environment variable is not set.")
result = process_question("xxxxxxx", "meta/llama-3.1-405b-instruct", "帮我查一下有多少的商品在售卖")
print(result)
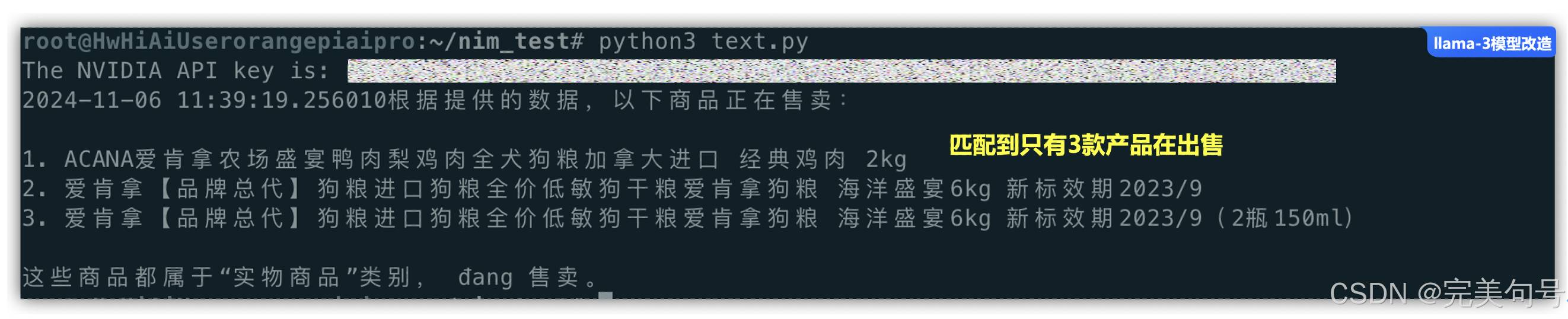
先将代码进行修改,主要的逻辑功能分为3步:
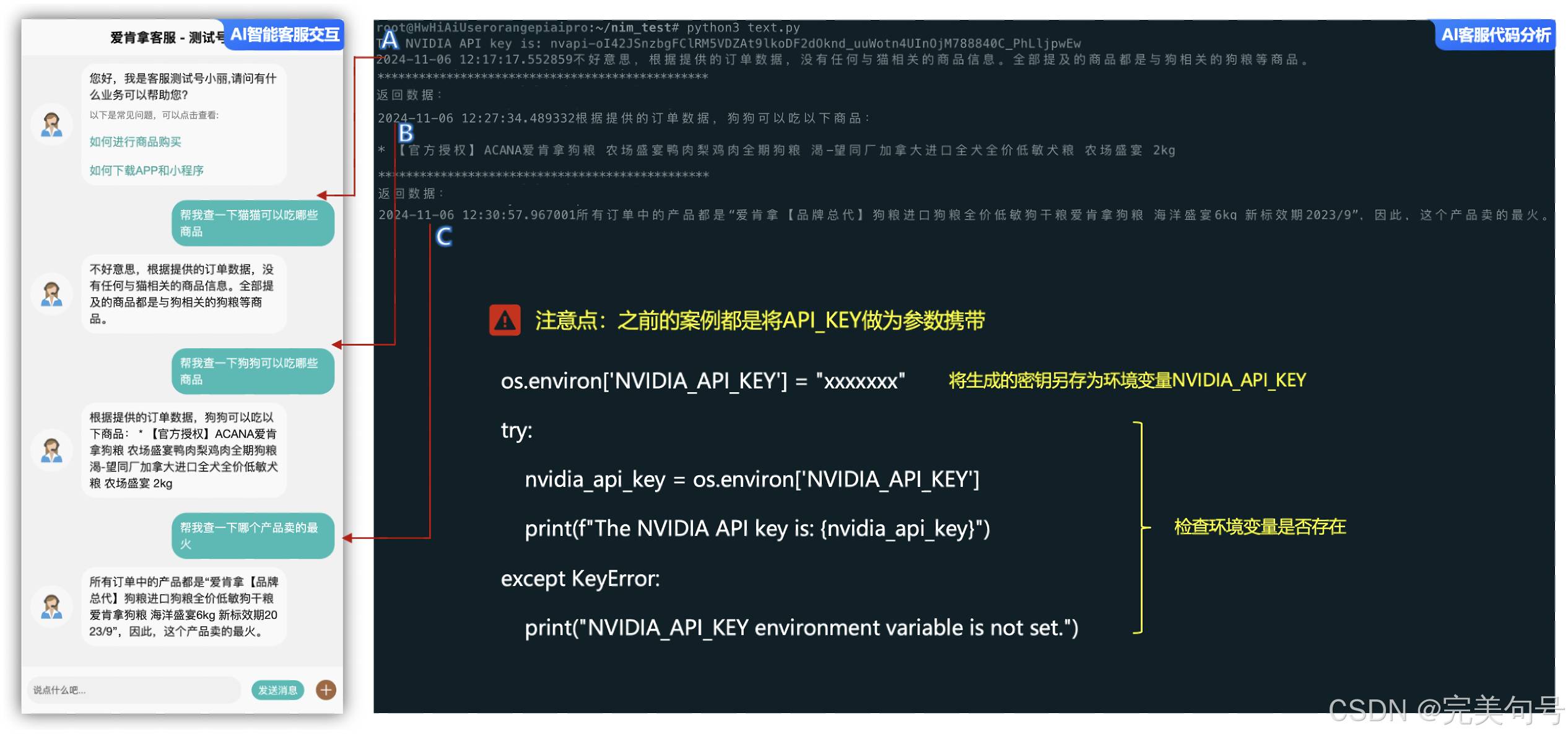
与传统的客户服务相比,基于“基于NVIDIA NIM 平台”应用式AI功能能够利用自然语言提示词进行自动化机器人程序开发,在大语言模型(LLM)的加持下,提升智能化问题解决效率,加速问题的有效处理。
AIGC是一种新的人工智能技术,它的全称是Artificial Intelligence Generative Content,即人工智能生成内容。现阶段AIGC多以单模型应用的形式出现,主要分为文本生成、图像生成、视频生成、音频生成,其中文本生成成为其他内容生成的基础。
通过“基于NVIDIA NIM平台各种AI大模型应用”的手册学习,实践了AI文案、AI OCR识别、AI LLM模型的案例,可以体验到简易部署、便捷维护,减少工作量、步骤繁琐、效率低和时间成本的问题,同时提升系统整体性能和用户体验。
本人在自己搭建与部署ChatGLM2-6B模型项目时,花费了大量的时间摸索,其中还要包括硬件配置比较高,综合考量了一下,可以看出以下的对比,“自己选购部署”与“基于NVIDIA NIM平台生成式AI应用”在以下7点存在业务痛点,“基于NVIDIA NIM平台生成式AI应用”大大的降低了使用的门槛、降低了学习的成本,让更多的企业、开发者能够加入到AI应用的行业中来。
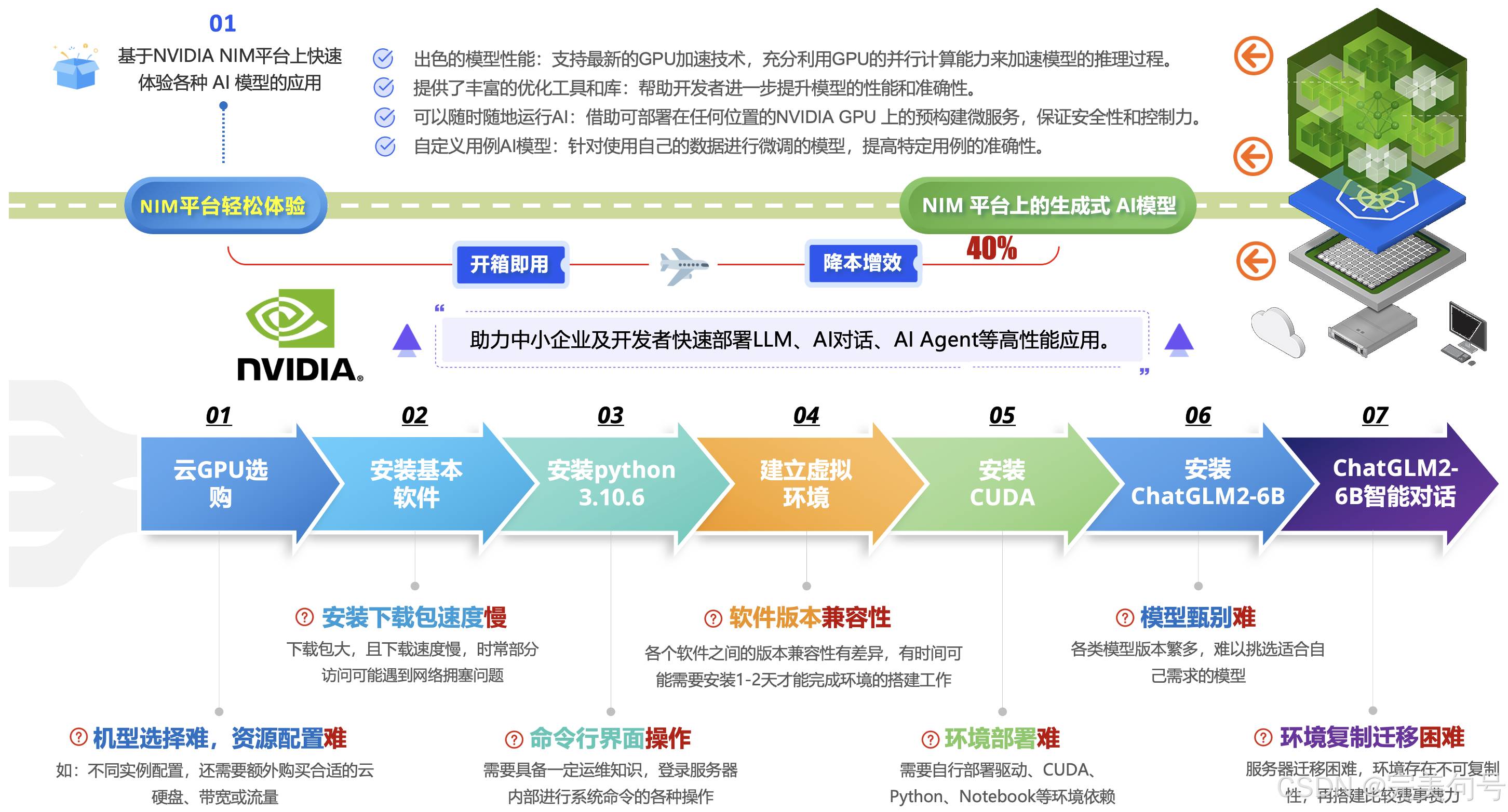
以下为在体验过程中,首先参考手册,然后,针对每个大模型详情页面,互动式交互体验中,以及简单易用API应用(不到15行代码)的实践,个人觉得非常提效的几个点:

同时,在体验AIGC的应用中,可以通过“基于NVIDIA NIM平台”的应用大幅提高内容生成的速度,节省时间和资源,“基于NVIDIA NIM平台生成式AI应用”可以轻松应对大规模的内容生成需求。
| 序号 | 分类 | 描述 |
|---|---|---|
| 1 | 提升生产效率 | “基于NVIDIA NIM平台生成式AI应用”大幅提高生产效率,进一步优化生产流程,提高生产效率。 |
| 2 | 降低运营成本 | “基于NVIDIA NIM平台生成式AI应用”可以降低企业的运营成本,帮助企业做出更加精准的生产决策, 从而降低生产成本,提高数据处理能力和响应速度,进一步降低企业的运营成本。 |
| 3 | 优化资源利用 | “基于NVIDIA NIM平台生成式AI应用”可以帮助企业优化资源利用,可以帮助企业更好地规划生产和资源分配,提高资源利用效率。 |
当然,并非是AI取代了人,而是会用AI对话模型、AI绘画工具的人,替换掉不会驾驭AI工具,传统的作业方式的人。让使用“基于NVIDIA NIM平台生成式AI应用”的在企业中,实现“一个人顶一个组”、“支撑以前2-3倍的业务体量”。
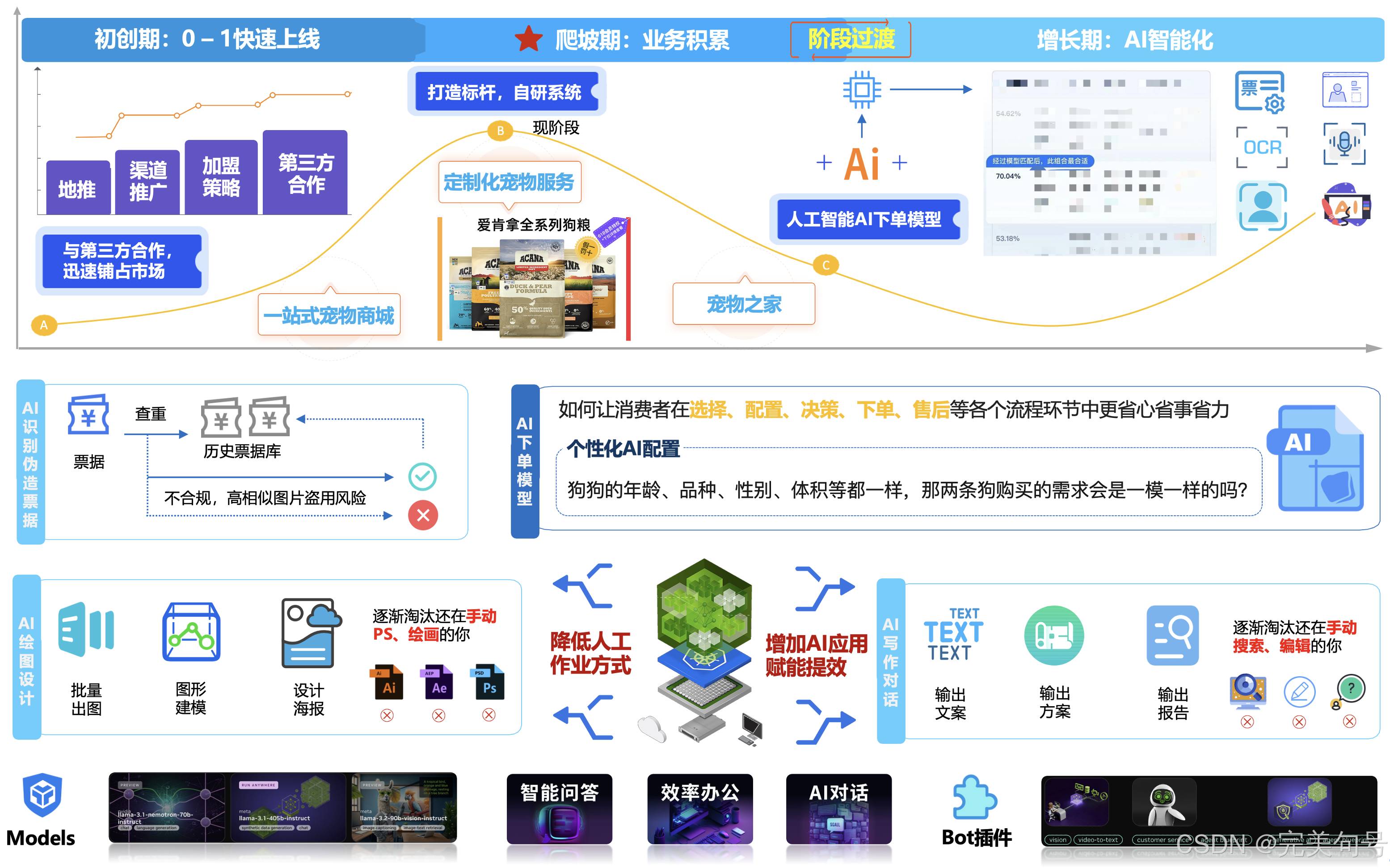
以上是公司经过了初创期、爬坡期,在行业内快速的吸引客户,并且占有一定的业务量,后续在原有的业务基础上,提高市场的竞争力,以及对公司一些CostDown原则的实施,希望能通过更多的AIGC的工具链路,帮助企业实施AI的战略布局,事实上,通过以上对AIGC的一些方案落地,可以看到在原有的人工传统作业方式,通过AIGC的工具体系,来加速业务的处理效率。
NVIDIA公司宣布推出 NIM(NVIDIA 推理微服务),这是一套易于使用的微服务,旨在加速生成式 AI 模型在云、数据中心和工作站上的部署:

版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码