黑森林实验室(Black Forest Labs)推出的FLUX.1图像生成模型,凭借120亿参数的庞大规模,正重新定义图像生成技术的标准。这一系列模型不仅为AI工程师提供了强大工具,也为图像生成领域带来了全新的活力。

FLUX.1系列模型包括三个版本,各自具有不同的特点和应用方向:
FLUX.1-Professional:闭源版本,提供行业领先的图像生成能力,特别在图像质量、细节呈现和多样性方面表现突出。它面向高性能需求的企业用户,支持通过API进行定制化访问,适合专业级应用。
FLUX.1-Developer:开源版本,商业用途受限,基于FLUX.1-Professional进行优化。它不仅继承了强大的提示词处理能力,还在效率上做了增强,适合开发者进行技术研究、应用开发和功能扩展。
FLUX.1-Express:开源且可商用,专为个人用户和小型开发设计,采用Apache 2.0许可证。其重点是生成速度和低内存占用,适合在资源有限的环境下使用,满足日常开发需求。
作为AI工程师,FLUX.1系列模型为我提供了一个强大的技术工具,帮助我在图像生成领域实现更高效的研发和应用。
这些模型不仅在性能上表现优异,而且具有灵活的扩展性,能够根据具体需求进行定制。无论是在学术研究还是实际项目中,FLUX.1的高效性和创新性都让我深刻感受到其在推动AI技术前沿发展的巨大潜力。对于我们这些致力于AI技术的工程师来说,FLUX.1无疑是提升工作效率和突破技术瓶颈的重要利器。
FLUX.1-Express凭借其快速生成能力和低资源占用,成为了AI工程师在进行图像生成任务时的理想选择。它能够在极短的时间内生成高质量的图像,同时对计算资源的需求较低,使得开发者能够在不依赖高性能硬件的情况下,快速进行模型训练和部署。这种高效性对于快速迭代和原型设计尤为重要,特别是在资源受限的环境中,FLUX.1-Express的优势更为突出。对于日常的AI应用开发,FLUX.1-Express无疑提供了一个高效、灵活的解决方案。
(1)在终端中执行以下命令克隆ComfyUI代码:
# github官方代码仓库
git clone https://github.com/comfyanonymous/ComfyUI.git
# gitCode-github加速计划代码仓库
git clone https://gitcode.com/gh_mirrors/co/ComfyUI.git
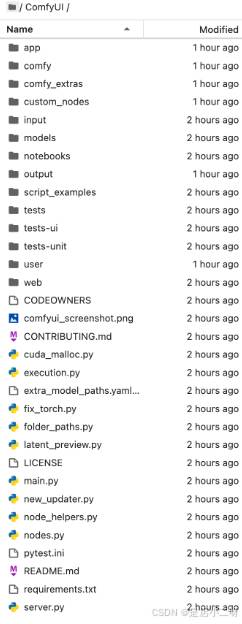
(2)克隆完成后可看到如下目录:
(3)终端进入/root/workspace/ComfyUI目录,执行以下命令,安装ComfyUI需要的依赖:
cd ComfyUI/
pip install -r requirements.txt --ignore-installed
(4)执行以下命令,启动ComfyUI:
python main.py --listen

(5)看到服务成功启动,说明ComfyUI部署成功!
推荐您阅读ComfyUI官方使用FLUX.1示例,以下是基于丹摩平台的部署教程
(1)平台已预制FLUX.1相关资源,您可通过内网高速下载:
# 下载完整FLUX.1-dev模型
wget http://file.s3/damodel-openfile/FLUX.1/FLUX.1-dev.tar
# 下载完整FLUX.1-schnell模型
wget http://file.s3/damodel-openfile/FLUX.1/FLUX.1-dev.tar
# 下载完整Clip模型
wget http://file.s3/damodel-openfile/FLUX.1/flux_text_encoders.tar
(2)此处以FLUX.1-dev为例演示,首先下载完整FLUX.1-dev模型:
wget http://file.s3/damodel-openfile/FLUX.1/FLUX.1-dev.tar
(3)解压文件:
tar -xf FLUX.1-dev.tar
(4)解压后完成后可看到如下目录:
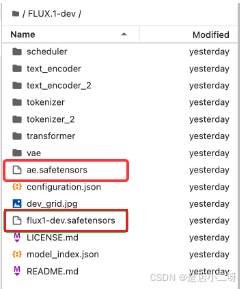
(5)把其中的一些文件移至ComfyUI指定目录:
flux1-dev.safetensors需要移动至/root/workspace/ComfyUI/models/unet/文件夹中ae.safetensors需移动至/root/workspace/ComfyUI/models/vae/文件夹中# 进入解压后的文件夹
cd /root/workspace/FLUX.1-dev
# 移动文件
mv flux1-dev.safetensors /root/workspace/ComfyUI/models/unet/
mv ae.safetensors /root/workspace/ComfyUI/models/vae/
(6)接下来下载完整Clip模型:
# 进入JupyterLab根目录
cd /root/workspace
# 下载文件
wget http://file.s3/damodel-openfile/FLUX.1/flux_text_encoders.tar
(7)解压文件:
tar -xf flux_text_encoders.tar
(8)解压后完成后可看到如下目录:
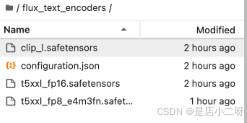
(9)把其中的一些文件移至ComfyUI指定目录:
# 进入解压后的文件夹
cd /root/workspace/flux_text_encoders
# 移动文件
mv clip_l.safetensors /root/workspace/ComfyUI/models/clip/
mv t5xxl_fp16.safetensors /root/workspace/ComfyUI/models/clip/

在丹摩征文活动中,围绕主题“FLUX.1图像生成模型:AI工程师的创新实践”,我们聚焦在FLUX.1图像生成模型的前沿应用与技术创新。本文探讨了AI工程师们如何利用FLUX.1模型推动图像生成技术的变革,通过实践与探索,不断优化模型的生成质量、提高效率,并解决实际应用中遇到的各种挑战。
FLUX.1模型不仅在生成效果上实现了大幅提升,也在细节处理和效率方面展现了其独特优势。AI工程师们在实际应用中发现,通过FLUX.1模型,他们可以生成更具表现力和细节丰富的图像,满足艺术创作、设计和商业应用的多样化需求。此外,FLUX.1的创新算法使得生成过程更加高效,为大规模图像生成提供了可能性。
然而,随着模型生成能力的提升,也带来了伦理、版权、生成质量控制等方面的新挑战。AI工程师们在创新的同时,必须保持对社会责任的清醒认识。如何平衡生成内容的真实性和创新性,如何避免滥用风险,这些都是FLUX.1模型实际应用中必须面对的问题。
通过此次征文活动,我们不仅看到了FLUX.1模型的创新成果,也深刻体会到AI工程师们在创新实践中不断克服技术难题的精神。未来,随着技术和规范的发展,相信FLUX.1将继续推动图像生成领域的进步,为AI应用的可持续发展奠定基础。
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码