目录
云计算
计算类技术
网络类技术
存储类技术
计算云服务
弹性云服务器(ECS)
裸金属服务器(BMS)
镜像服务(IMS)
弹性伸缩服务(AS)
云容器引擎(CCE)
网络云服务
虚拟私有云(VPC)
弹性负载均衡(ELB)
NAT网关
存储云服务
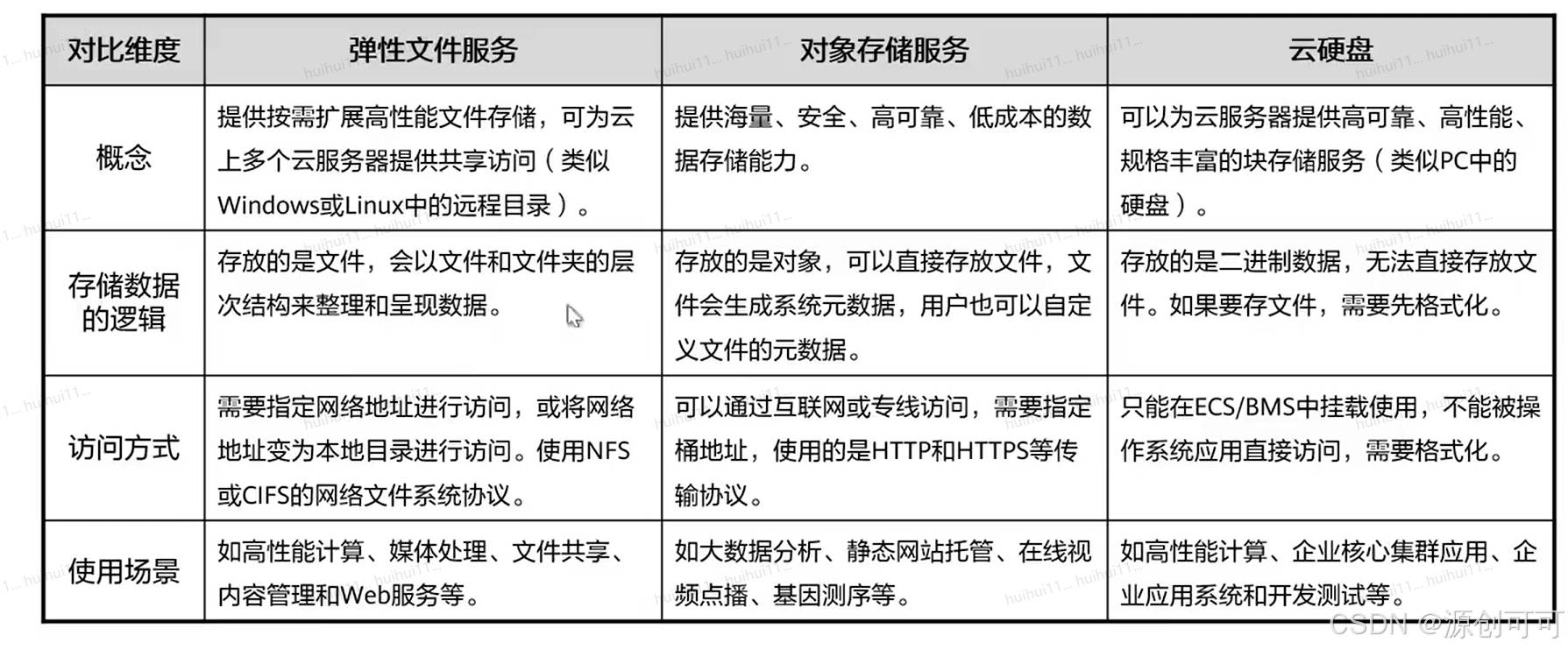
云硬盘(EVS)
对象存储服务(OBS)
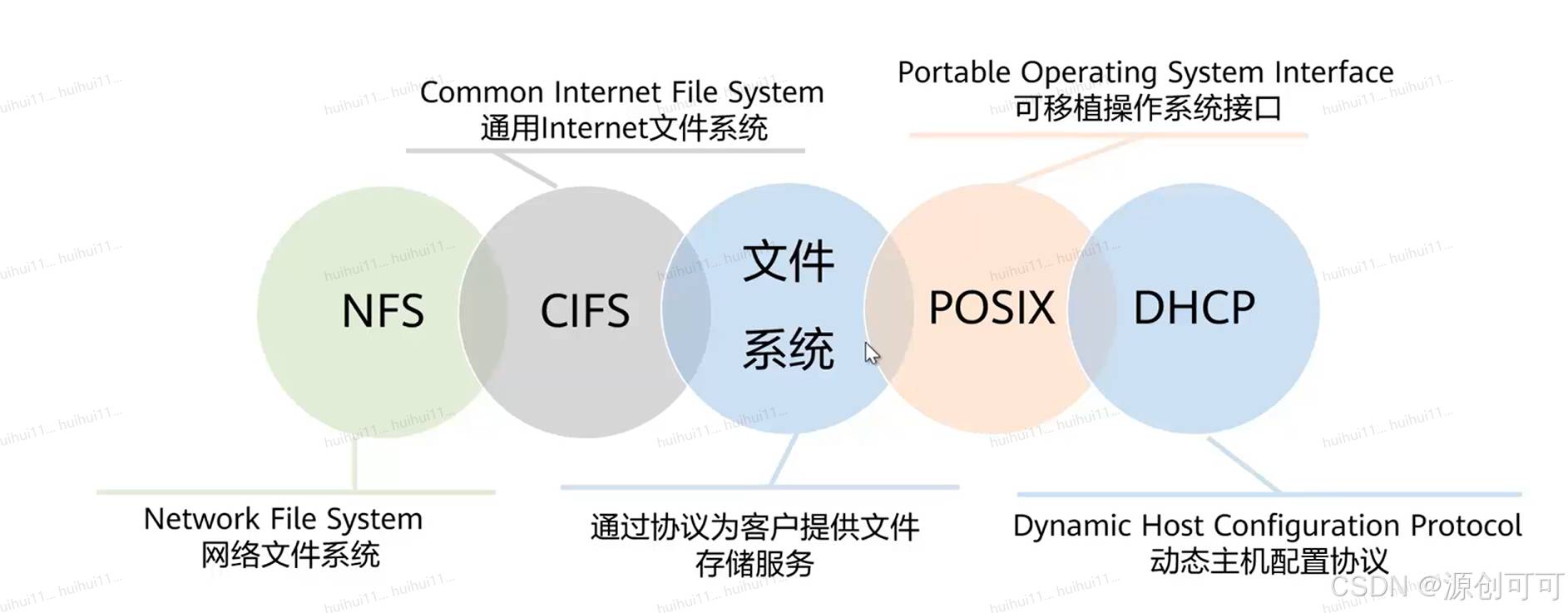
弹性文件服务(SFS)
其他云服务
华为云运维基础
云审计服务(CTS)
云监控服务(CES)
云日志服务(LTS)
大数据
大数据发展
HDFS和Zookeeper
HDFS分布式文件系统
Zookeeper分布式协调服务
Hive数据仓库软件
HBase分布式列式数据库
MapReduce分布式计算引擎和Yarn技术原理
Spark大数据计算引擎
Flink流批一体分布式实时处理引擎
Flume流式日志采集工具
Loader数据转换
Kafka分布式消息订阅系统
LDAP Kerberos
统一身份认证管理
目录服务及Ldap基本原理介绍
单点登陆及Kerberos基本原理介绍
华为大数据安全认证场层架构
分布式全文检索服务ElasticSearch
Redis内存数据库
人工智能
人工智能概览
机器学习概览
深度学习概览
人工智能开发框架
华为人工智能平台介绍
人工智能前沿应用场景
本文为速成内容,针对临时备考的学生写的,展示的是部分知识点,如需系统学习,请关注作者,后续会更新~
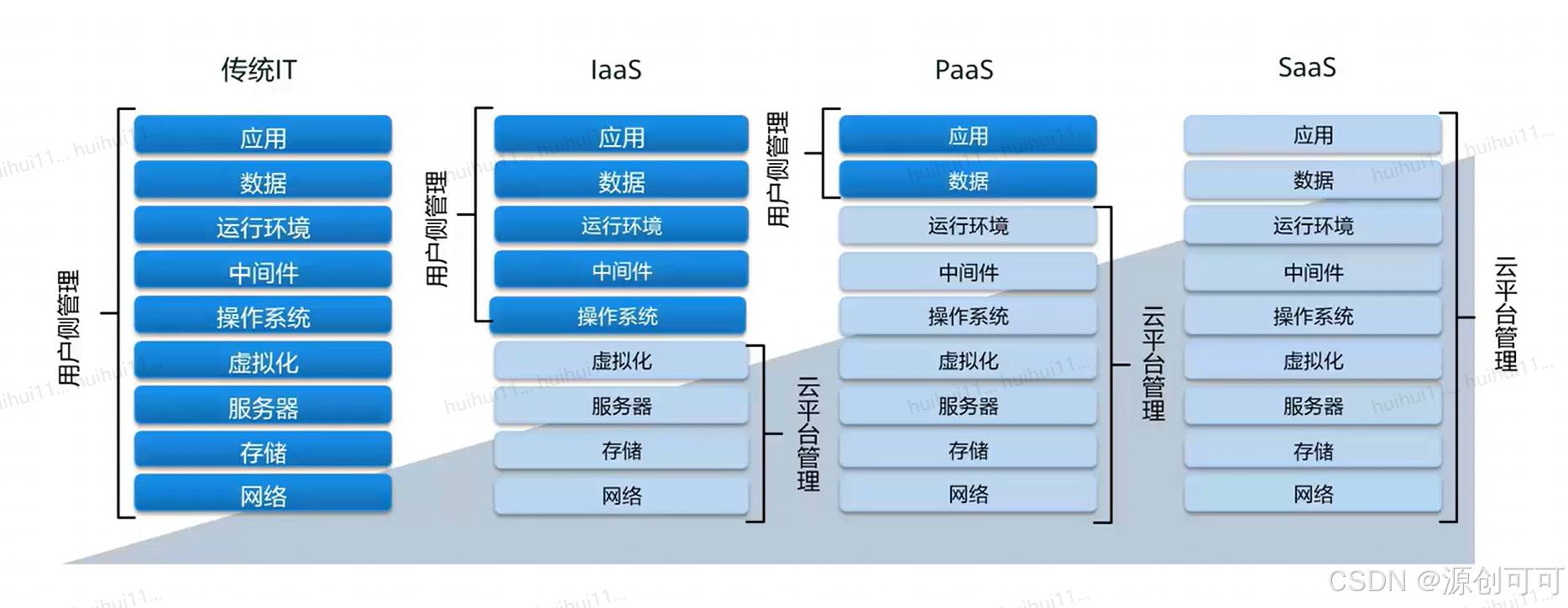
特点:
部署模式:
服务模式:
虚拟化
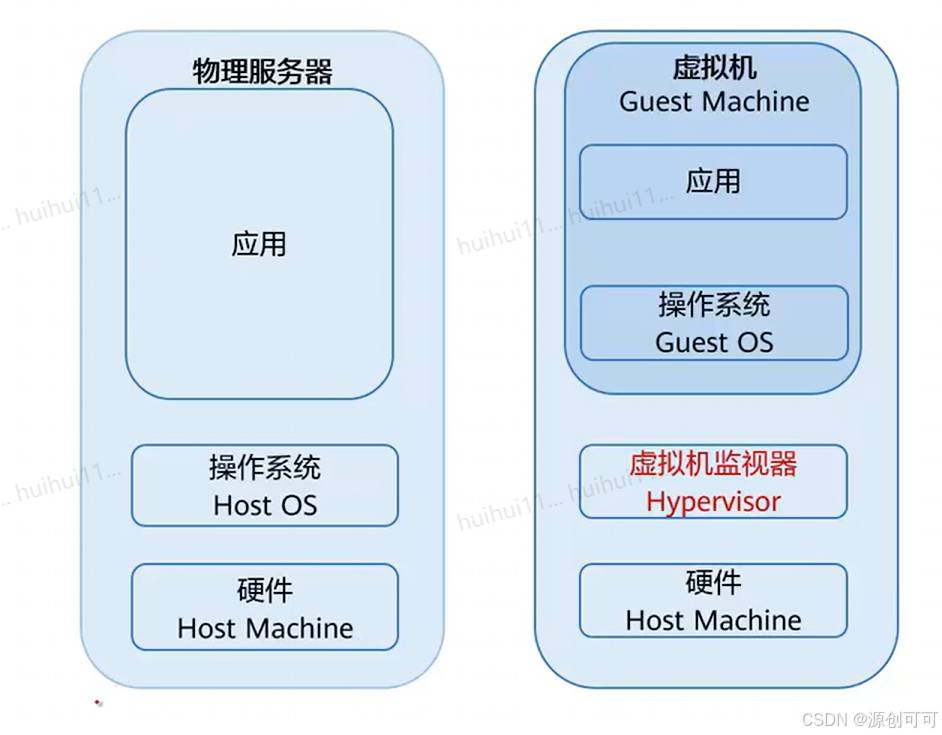
虚拟化技术可将单台物理服务器虚拟为多台虚拟机使用,多台虚拟机共享该物理服务器的硬件资
源。
虚拟机本质上是由磁盘文件和描述文件组成,封装在同一个文件夹中。虚拟化的本质就是将原先的物理设备进行逻辑化,转化成一个文件夹或文件,实现软硬件的解耦。
特点:
分区(按规格大小来分配资源)、隔离(一个虚拟机受攻击不会影响其他的虚拟机)、封装(虚拟机以文件形式存在)、独立(硬件独立,没有绑定关系,软硬件解耦)
Guest OS:虚拟机操作系统
Guest Machine:虚拟出来的虚拟机
Hypervisor:虚拟化软件层/虚拟机监视器
Host OS:运行在物理机之上的OS
Host Machine:物理机
计算在云计算中的服务形态:
容器
容器是一个标准化的单元,是一个轻量级、可移植的软件打包技术。它将软件代码及其
相关依赖打包,使应用程序可以在任何计算介质中运行。简单来讲,容器就像一个标准
化的盒子,能够装很多不同类型的东西,并且装完后能够塞进很多不同类型的柜子里。
容器与虚拟机区别
| 特性 | 容器 | 虚拟机 |
| 启动时间 | 秒级 | 分钟级 |
| 虚拟化类型 | 操作系统虚拟化 | 硬件虚拟化 |
| 操作系统依赖 | 所有容器共享主机操作系统 | 每个VM都在自己的OS中运行 |
| 安全性 | 进程级隔离,可能不太安全 | 完全隔离,因此更安全 |
| 隔离策略 | Namespace、CGroups | Hypervisor |
| 镜像大小 | KB-MB | GB-TB |
| 性能优势 | 本机性能 | 性能有限 |
| 系统支持量 | 单机(物理机)可支持上干个容器 | 一般几十个 |
容器在云计算中的服务形态:
云容器引擎CCE(容器实例的一种)属于华为云的laaS(基础设施即服务)层服务。IaaS层服务是指云服务提供商提供基础的计算、存储、网络等基础设施服务,用户可以在此基础之上构建自己的应用平台和数据库等服务。
云容器实例CCI(容器实例的一种)无服务容器引擎,我们不需要再去创建和管理服务集群,就可以直接运行容器
容器镜像服务SWR(为容器实例提供镜像)支持镜像全生命周期管理的一个服务,它可提供简单易用并安全可靠的镜像管理功能,可以帮助我们快速部署容器化服务时的镜像的所有需求。
传统网络的基本概念
广播和单播,路由,默认网关,VLAN
桥接和NAT的作用
桥接:源地址不会变
NAT:源地址会变
虚拟交换机的作用
在虚拟化环境中充当数据包转发和流量管理的中介
同桥接和NAT不同,前者是Liux操作系统自身的功能,而虚拟交换机是经过虚拟化技术
处理之后产生的网络模型。但同桥接和NAT一样,虚拟交换机也是为了解决虚拟机内部
流量如何从所在物理服务器的物理网口出去的问题。常见的虚拟交换机模型有OVS(标准虚拟交换机。只在服务器内部生效,每个服务器配置一个虚拟交换机)、EVS(增强型交换机。网络转发性能有一定增强)、Dvs(分布式虚拟交换机。华为用的就是这个,横跨多台物理服务器)
等。
网络在云计算中的服务形态:
虚拟私有云VPC(云上的私有网络环境)
NAT网关(网络地址转换服务)
弹性公网IP EIP(为ECS提供互联网访问的IP)
主流存储类型
块存储
块存储就是把裸的硬盘空间分配给服务器,服务器可以按需整理空间,完成分区、
格式化、挂载后直接用来存放数据。
文件存储
对象存储
弹性云服务器是由CPU、内存、操作系统、云硬盘组成的基础计算组件。弹性云服务器创建成功后,可以像使用自己的本地C或物理P服务器一样,在云上使用弹性云服务器。
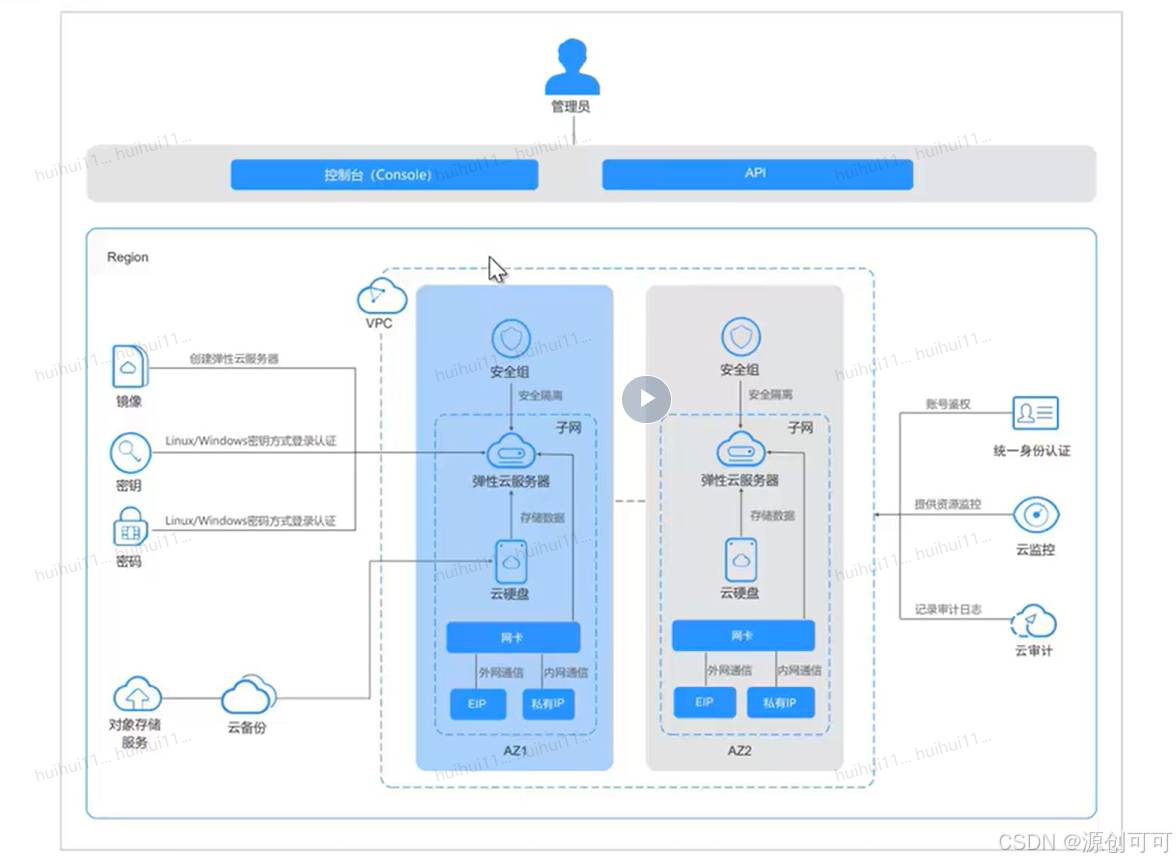
优势
适用场景:网站开发测试环境、电商、图形渲染、游戏动画
计费模式
裸金属服务器是一款兼具虚拟机弹性和物理机性能的计算类服务,为用户以及相关企业提供专属的云上物理服务器,为核心数据库、关键应用系统、高性能计算、大数据等业务提供卓越的计算性能以及数据安全。用户可灵活申请,按需使用。
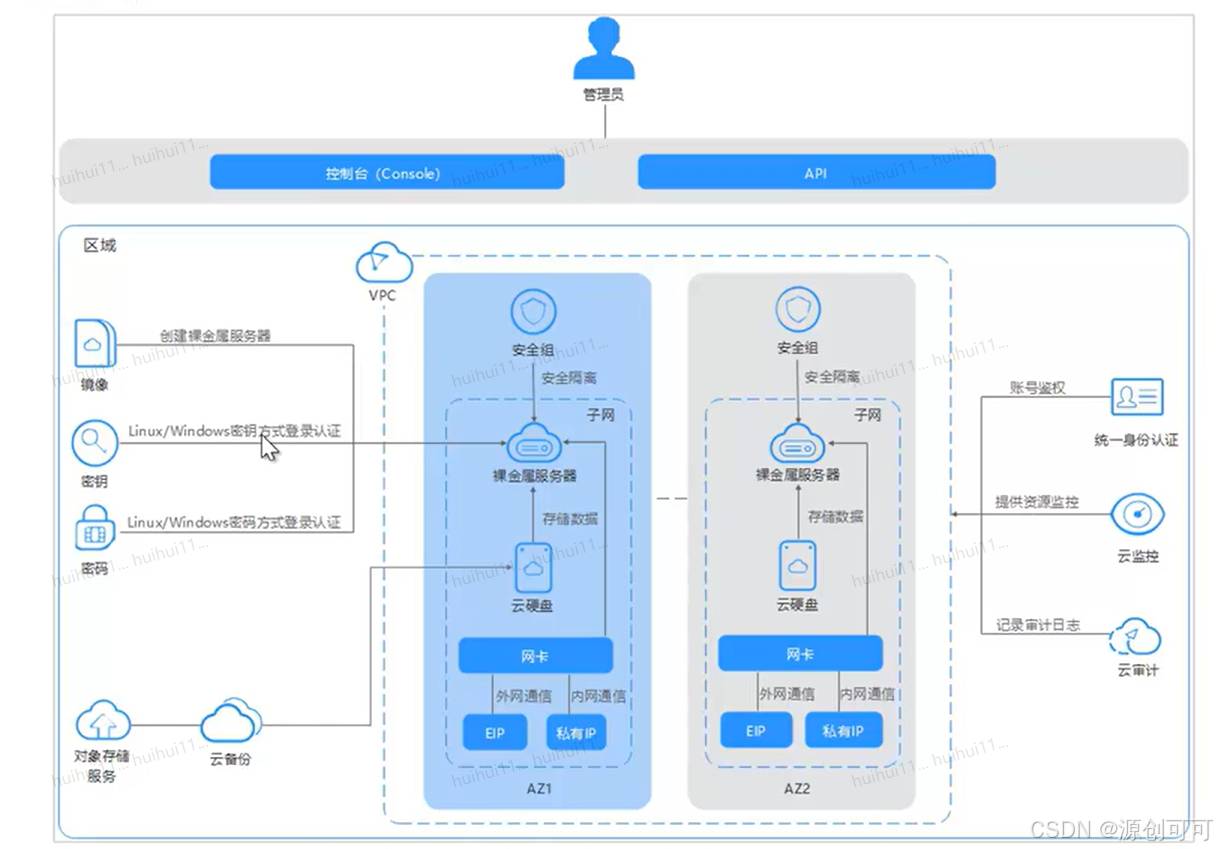
优势
适用场景:核心数据库、超算中心
ESC vs BMS
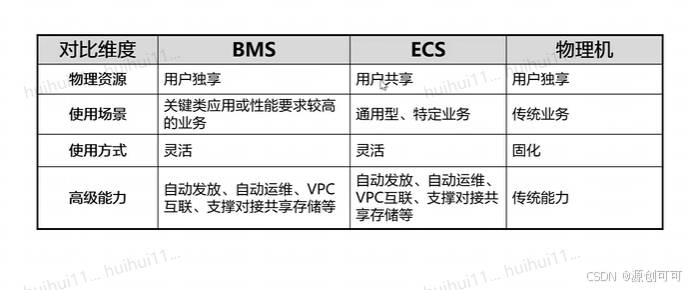
BMS网络类型
镜像服务提供镜像的生命周期管理能力。用户可以灵活地使用公共镜像、私有镜像或共享镜像申请弹性云服务器和裸金属服务器。同时,用户还能通过已有的云服务器或使用外部镜像文件创建私有镜像,实现业务上云或云上迁移。
优势
产品类型
应用场景:服务器上云或云上迁移、部署特定软件环境、服务器运行环境备份
删除复制镜像的源镜像,对复制后的镜像没有影响;
弹性伸缩是根据用户的业务需求,通过策略自动调整其业务资源的服务。用户可以根据业务需求自行定义伸缩配置和伸缩策略,降低人为反复调整资源以应对业务变化和高峰压力的工作量,帮助用户节约资源和人力成本。
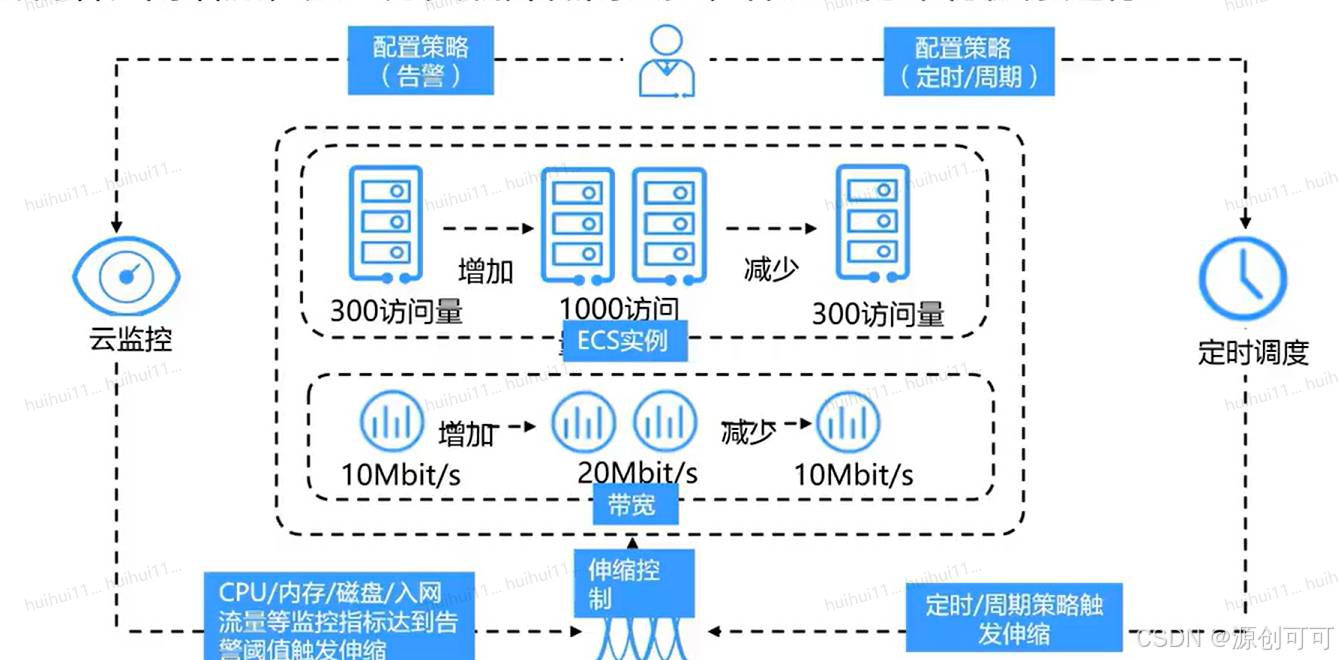
优势
适用场景:电商网站、存在明显波峰波谷的大流量网站
云容器引擎提供高度可扩展的、高性能的企业级Kubernetes集群,支持运行Docker容器。借助云容器引擎,用户可在华为云上轻松部署、管理和扩展容器化应用程序。
优势
应用场景:集群弹性伸缩、AI计算
概念
集群:容器运行所需云资源的集合,包含了若干台云服务器、负载均衡器
等云资源
实例(POd):由相关的一个或多个容器构成一个实例,这些容器共享相同的存储
和网络空间。
服务:由多个相同配置的实例(Pod)和访问这些实例(Pod)的规则组成的微服务。
容器:一个通过Docker镜像创建的运行实例,一个节点可运行多个容器。
镜像:一种模板,Docker镜像用于部署容器服务。
虚拟私有云是用户在华为云上申请的隔离的、私密的虚拟网络环境。用户可以自由配置VPC内的IP地址段、子网、安全组等子服务,也可以基于VPC申请弹性带宽或弹性IP给业务系统使用。
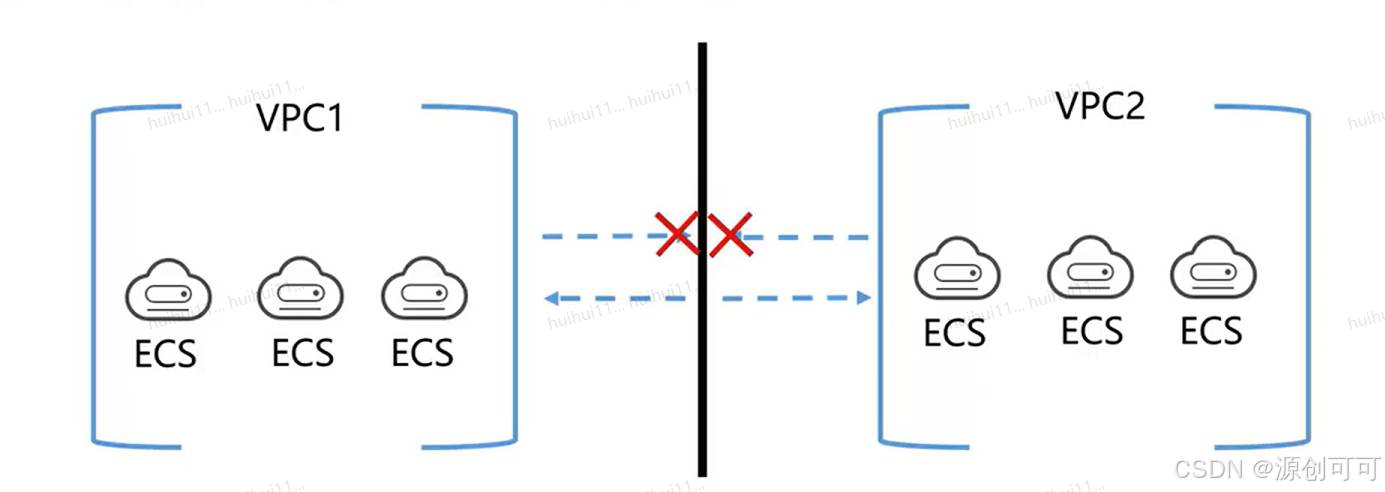
应用场景:云端专属网络、web应用或网站托管、云上VPC连接
弹性公网IP
弹性公网IP可以提供独立的公网IP资源,包括公网IP地址与公网出口带宽服务。可以与弹性云服务器、裸金属服务器、虚拟IP、弹性负载均衡、NAT网关等资源灵活地绑定及解绑。拥有多种灵活的计费方式,可以满足各神业务场景的需要。一个弹性公网IP只能绑定一个云资源使用。
安全组
安全组是一个逻辑上的分组,为同一VPC内具有相同安全保护需求并相互信任的弹性云服务器提供访问策略。安全组创建后,用户可以在安全组中定义各种访问规则,当弹性云服务器加入该安全组后,即受到这些访问规则的保护。
对等连接
对等连接是指两个VPC之间的网络连接。用户可以使用私有IP地址在两个VPC之间进行通信,就像两个VPC在同一个网络中一样。同一区域内,用户可以在自己的VPC之间创建对等连接,也可以在自己的VPC与其他帐户的VPC之间创建对等连接。不同区域间的VPC之间不能创建对等连接。
弹性负载均衡是将访问流量根据分配策略分发到后端多台服务器的流量分发控制服务。弹性负载均衡可以通过流量分发扩展应用系统对外的服务能力,同时通过消除单点故障提升应用系统的可用性。
应用场景:高访问量业务进行流量分发
配置流程
虚拟专用网络(VPN)
虚拟专用网络用于在远端用户和虚拟私有云之间建立一条安全加密的公网通信隧道。当远端用户需要访问VPC的业务资源时,可以通过VPN连通VPC。
优势
VPN由VPN网关和VPN连接组成
NAT网关能够为VPC内的计算实例提供网络地址转换服务,使多个计算实例共享弹性IP访问Internet。NAT网关可分为公网NAT网关和私网NAT网关。
SNAT(源地址转换) 将内部网络的源IP地址转换为外部网络的公共IP地址。
DNAT(目的地址转换)将外部访问的目标IP地址转换为内部网络的私有IP地址。
云硬盘可以为云服务器提供高可靠、高性能、规格丰富并且可弹性扩展的块存储服务,可满足不同场景的业务需求。用于分布式文件系统、开发测试、数据仓库以及高性能计算等场景。
性能指标:
对象存储服务是一个基于对象的海量存储服务,为用户提供海量、安全、高可靠、低成本的数据存储能力。
支持通过永久AK/SK 临时AK/SK 进行认证鉴权
Bucket桶 Object对象
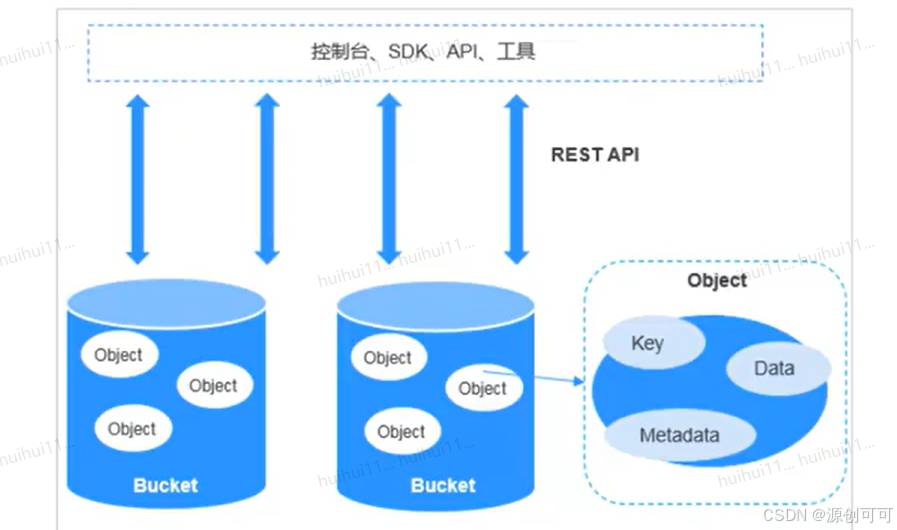
应用场景:大数据分析、企业云盘、备份归档
OBS对象
key Data Metadata
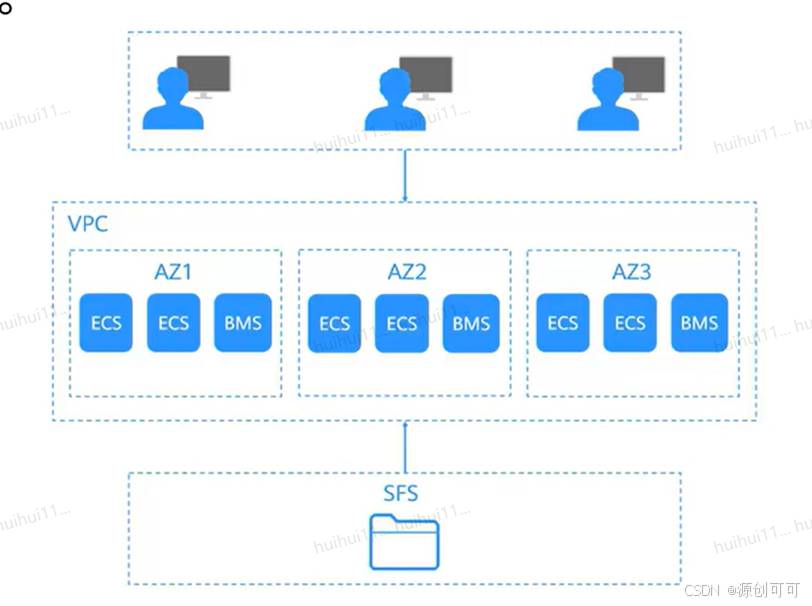
弹性文件服务可为用户提供按需扩展的高性能文件存储,可为云上多个弹性云服务器、容器、裸金属服务器提供共享访问。有自己独有的网络架构
应用场景:媒体处理、文件共享(百度网盘)
SFS vs OBS vs EVS
支持配置多个VPC,使得归属于不同VPC的云服务器也能共享访问同一个文件系统。
配置流程:
数据库类服务
安全类服务
HSS服务 主机安全服务,实时监控,防病毒、防攻击。
WAF服务 Web 应用防火墙,防护网站免受 SQL 注入、XSS 等攻击。部署模式:云模式、独享模式、ELB模式
DEW服务 数据加密服务,提供加密和密钥管理,确保数据安全。
IAM服务 身份与访问管理,控制用户权限,提升资源安全。
CND服务 内容分发网络,加速内容加载,提升用户访问体验。应用场景:网站加速、点播加速、全站加速
云审计服务主要是提供云账户下资源的操作记录,通过操作记录,用户可以实现安全分析、资源变更、合规审计、问题定位等功能。可以通过配置OBS对象存储服务,将操作记录实时同步保存至OBS,以便保存更长时间的操作记录。


云监控服务为用户提供一个针对弹性云服务器、带宽等资源的立体化监控平台。使用户可以全面了解华为云上的资源使用情况、业务的运行状况,并及时收到异常报警从而做出反应,保证业务顺畅运行。
主要功能
应用场景:电商业务解决方案、站点监控、事件监控
云日志服务用于收集来自主机和云服务的日志数据,通过海量日志数据的分析与处理,可以将云服务和应用程序的可用性和性能最大化,为用户提供一个实时、高效、安全的日志处理能力,可快速高效地进行实时决策分析、设备运维管理、用户业务趋势分析等。
优势:
第三次信息化浪潮的标志:云计算、大数据、物联网技术的普及
大数据4V:数据量大、数据类型繁多、处理速度快、价值密度低
命名空间包含目录、文件和块
HDFS使用的是传统的分级文件体系,因此,用户可以像使用普通文件系统一样创建、删除目录和文件,在目录间转移文件,重命名文件等。
HDFS只设置唯一一个名称节点,这样做虽然大大简化了系统设计,但也带来了些明显的局限性,具体如下:
命名空间的限制:名称节点是保存在内存中的,因此名称节点能够容纳的对象(文件、块)的个数会受到内存空间大小的限制。
性能的瓶颈:整个分布式文件系统的吞吐量,受限于单个名称节点的吞吐量。
隔离问题:由于集群中只有一个名称节点,只有一个命名空间,因此,无法对不同应用程序进
行隔离。
集群的可用性:一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用。
ZooKeepers集群由一组Server节点组成,这一组Server节点中只存在一个Leader的节点,其他节
都为Follower。
启动时选举出leader。
ZooKeeper使用自定义的原子消息协议,保证了整个系统中的节点数据的一致性。
Leader节点在接收到数据变更请求后,先写磁盘再写内存。
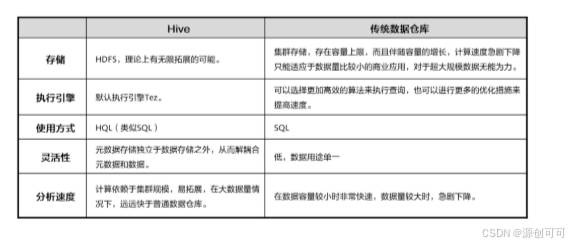
Apache Hive数据仓库软件有助于使用SQL读取,写入和管理驻留在分布式存储中的大型
数据集。可以将结构投影到已经存储的数据上。提供了命令行工具和JDBC驱动程序以将
用户连接到Hive。
Hive是基于Hadoop的数据仓库软件,可以查询和管理PB级别的分布式数据。
特性
应用场景
数据汇总、数据挖掘、非实时分析(日志分析,文本分析)、数据仓库
优点
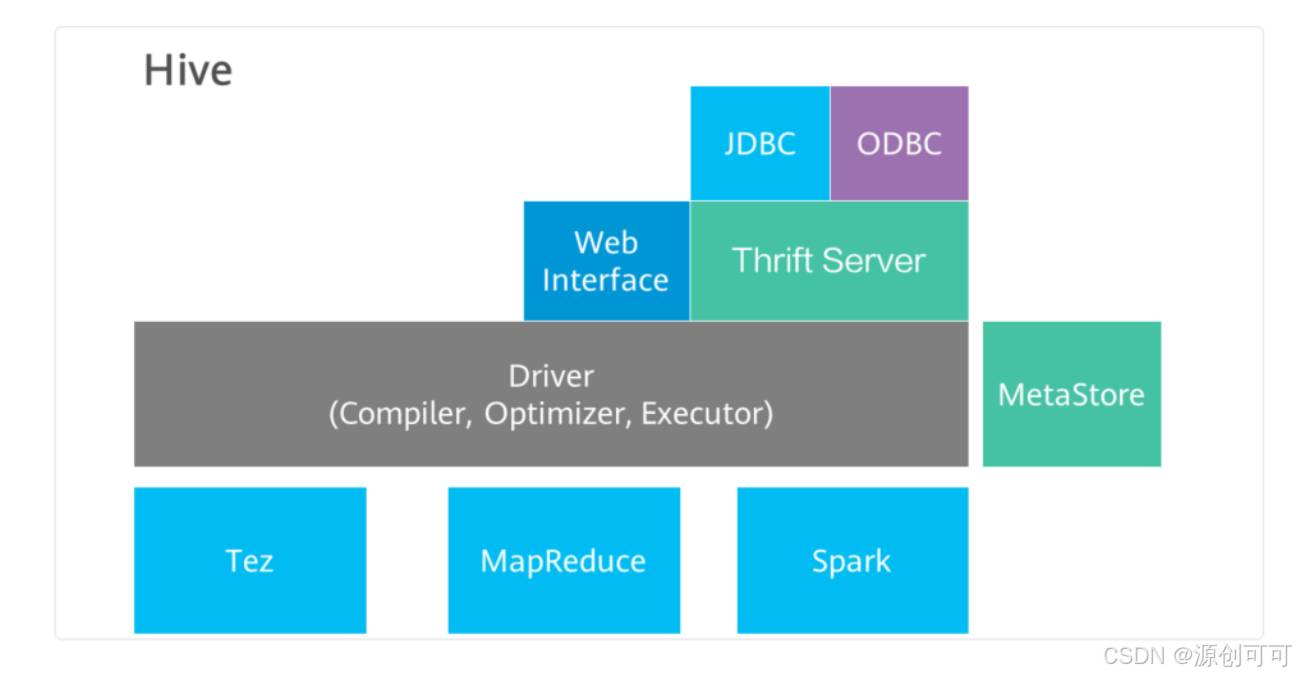
运行流程
Client提交HQL命令
Tez执行查询
YARN为集群中的应用程序分配资源,并为YARN队列中的Hive作业启用授权。
Hive根据表类型更新HDFS或Hive仓库中的数据。
Hive通过JDBC连接返回查询结果。
如果是非专业的同学可能难于记忆,可以这样理解:
客户端提交 HQL 查询,相当于顾客点餐;Tez 负责执行查询,就像厨师按照点单准备菜品;YARN 负责为任务分配资源,相当于总厨协调灶台和厨房资源;Hive 根据需求更新 HDFS 或 Hive 仓库的数据,就像厨房补充配料;最后通过 JDBC 返回查询结果,就像服务员将菜品端到顾客面前,个过程高效协作,满足查询需求。
使用方式

DDL数据定义语言 建表、修改表、删表、分区、数据类型
DML数据管理语言 数据导入 导出
DQL 数据查询语言 简单查询 复杂查询Group by,Order by,join
Hive本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce处理数据
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。(非关系型分布式数据库/列式数据库)
适合于存储大表数据(表的规模可以达到数十亿行以及数百万列),并且对大表数据的读。写访问可以达到实时级别。
利用Hadoop HDFS作为其文件存储系统,提供实时读写的分布式数据库系统。
利用ZooKeeper作为协同服务。
文件格式是HFile
三层结构
特点
只有一个索引一一行键
面向海量数据存储,可以达到TB和PB级别
不需要完全拥有传统关系型数据库所具备的ACID特性(A代表事务的原子性C代表事务的一致性I代表事务的独立性D代表事务的永久性)
高吞吐量
数据模型
简单来说,应用程序是以表的方式在HBase存储数据的。
表是由行和列构成的,所有的列是从属于某一个列族的。
行和列的交叉点称之为cell,cell是版本化的。cell的内容是不可分割的字节数组。
表的行键也是一段字节数组,所以任何东西都可以保存进去,不论是字符串或者数字。
HBase的表是按key排序的,排序方式是针对字节的。
所有的表都必须要有主键-key.
和传统关系型数据库区别
访问HBase表中的行的方式
架构介绍
主服务器HMaster负责管理和维护HBase表的分区信息,维护HRegionServer列表, 分配Region负载均衡。
HRegionServer负责存储和维护分配给自己的Region,处理来自客户端的读写请求。
客户端并不是直接从HMaster主服务器上读取数据,而是在获得Region的存储位 置信息后,直接从HRegionServer上读取数据。
客户端并不依赖HMaster,而是通过Zookeeper来获得Region位置信息,大多数客户端甚至从来不和HMaster通信,这种设计方式使得HMaster负载很小。
是不是会有很多小伙伴在架构这里有点懵,没有关系,给大家打个比方
HBase 的设计就像图书馆的借书流程:管理员(HMaster)负责记录书籍的分类信息和分配书架任务给工作人员(HRegionServer),而借书的人(客户端)通过“位置指引”(Zookeeper)找到书的位置后,直接去找负责对应书架的工作人员借书,而不是每次都去找管理员。这样减少了管理员的压力,提高了借书的效率,即使管理员暂时不在,也可以通过位置指引完成借书操作。
Region
客户端是通过三级寻址来定位Region
MapReduce
MapReduce 是一个分布式计算引擎,专注于处理大规模数据集。
MapReduce基于Google发布的MapReduce论文设计开发,基于分而治之的思想,用于
大规模数据集(大于1TB)的并行计算和离线计算。MapReduce是一个基于集群的高性能并行计算平台
工作流程
Map 阶段:
Shuffle 阶段:
Reduce 阶段:
每个Map任务分配一个缓存;MapReduce默认100MB缓存;
Yarn
YARN(Yet Another Resource Negotiator)是 Hadoop 生态系统中的核心组件之一,它是一个资源管理和任务调度系统,用来高效管理和分配计算集群中的资源 简称集群资源管理(另一种资源的协调者),它是一个通用资源管理系统
Yarn增强特性
Apache Spark是一种基于内存的快速、通用、可扩展的大数据计算引擎。
Spark是一站式解决方案,集批处理、实时流处理、交互式查询、图计算与机器学习于一体。
应用场景
批处理可用于ETL(抽取、转换、加载)。
机器学习可用于自动判断淘宝的买家评论是好评还是差评。
交互式分析可用于查询Hive数据仓库。
流处理可用于页面点击流分析,推荐系统、舆情分析等实时业务。
RDD
RDD(Resilient Distributed Datasets)即弹性分布式数据集,是一个只读的,可分
区的分布式数据集。
默认存储在内存,内存不足,溢写到磁盘
RDD数据以分区的形式在集群中存储
RDD具有血统机制(Lineage),发生数据丢失时,可快速进行数据恢复。
宽依赖,窄依赖
Spark SQL的执行引擎为Spark core,Hive默认执行引擎为MapReduce。
Spark SQL的执行速度是Hive的10-100倍。
Spark SQL不支持buckets,Hive支持。
联系
Spark SQL依赖Hive的元数据。
Spark SQL兼容绝大部分Hive的语法和函数。
Spark SQL可以使用Hive的自定义函数。
Apache Flink是为分布式、高性能的流处理应用程序打造的开源流处理框架。Flink不仅
能提供同时支持高吞吐和exactly-once语义的实时计算,还能提供批量数据处理。
Fink和Spark都可以同时支持流处理和批处理。
Flink与其他流计算引擎的最大区别,就是状态管理。Fink提供了内置的状态管理,可以把工作时状态存储在Flink内部,而不需要把它存储在外部系统。这样做的好处:降低了计算引擎对外部系统的依赖,使得部署、运维更加简单;对性能带来了极大的提升。
DataSet:Flink系统可对数据集进行转换(例如,过滤,映射,联接,分组),数据集可
从读取文件或从本地集合创建。结果通过接收器(Sink)返回,接收器可以将数据写入
(分布式)文件或标准输出(例如命令行终端)。
DataSet执行sort、filter、shuffle等操作时,并不需要进行反串行化。相反,由于DataSet是强类型的,它在执行这些操作时通常比RDD更高效。
Flink程序由Source、Transformation和Slink三部分组成,其中Source主要负责数据的读
取,支持HDFS、kafka和文本等;Transformation主要负责对数据的转换操作;Slink负
责最终数据的输出,支持HDFS、kafka和文本输出等。在各部分之间流转的数据称为流
(stream)
流处理中时间分类
例如,一条日志进入Fink的时间为2019-11-12 10:00:00.123,到达Window的系统时间为2019-11-12100001234,日志的内容如下:
2019-11-0218:37:15.624 INFO Fail over to0rm2
2019-11-0218:37:15.624是Event Time
2019-11-1210:00:00.123是Ingestion Time;
2019-11-1210:00:01.234是Processing Time;
乱序问题
例子:某App会记录用户的所有点击行为,并回传日志(在网络不好的情况下,先保存在本地,延后回传)。A用户在11:02对App进行操作,B用户在11:03对App进行操作,但是A用户的网络不太稳定,回传日志延迟了,导致我们在服务端先接受到B用户11:03的消息,然后再接受到A用户11:02的消息,消息乱序了
为什么需要Watermark?
对于无穷数据集,我们缺乏一种有效的方式来判断数据完整性,因此就有了Watermark,
它是建立在事件时间上的一个概念,用来刻画数据流的完整性。如果按照处理时间来衡
量事件,一切都是有序的、完美的,自然而然也就不需要Watermark了。换句话说事件
时间带来了乱序的问题,而Watermark就是用来解决乱序问题。所谓的乱序,其实就是
有事件延迟了,对于延迟的元素,我们不可花无限期的等下去,必须要有一种机制来保
证一个特定的时间后,必须触发Vindowi进行计算。这个特别的机制,就是Watermark,
它告诉了算子延迟到达的消息不应该再被接收。
Flink容错机制
Checkpoint机制
Flink如何保证exactly-once(端到端数据一致性)呢?它使用一种被称为“检查点(Checkpoint)”的特性
在出现故障时将系统重置回正确状态。Flink状态保存主要依靠Checkpoint机制,
Checkpoint:会定时制作分布式快照,对程序中的状态进行备份。
默认情况下Flink不开启检查点,用户需要在程序中通过调用enableCheckpointing(n)方
法配置和开启检查点,其中n为检查点执行的时间间隔,单位为毫秒。
exactly-once(Flink默认)Flink默认使用exactly-once模式,可以通过setCheckpointingMode(O方法来设定语义模式。
保证端到端数据一致性,数据要求高,不允许出现数据丢失和数据重复
at-least-once
时延和吞吐量要求非常高但对数据的一致性要求不高的场景。
Flume提供从本地文件(spooling directory source)、实时日志(taildir、exec)、REST消息、Thrift、Avro、Syslog、Kafka等数据源上收集数据的能力。
提供从固定目录下采集日志信息到目的地(HDFS,HBase,Kafka)能力。
提供实时采集日志信息(taildir)到目的地的能力。
Flume支持级联(多个Flume对接起来),合并数据的能力。
Flume支持按照用户定制采集数据的能力。
Source
驱动型source:是外部主动发送数据给Flume,驱动Flume接受数据。
轮询source:是Flume周期性主动去获取数据。
Source必须至少和一个channel(通道)关联。Channel位于Source(源)和Sink(出口)之间,Channel的作用类似队列,用于临时缓存进来的events,当Sink成功地将events发送到下一跳的channel或最终目的,events从Channel移除。(Source从外部数据源中接收数据 把 events 写入 Channel,Channel临时保存数据,Sink 从 Channel 中读取,负责将 Channel 中的数据写入目标存储系统)
Flume架构中Sink Runner的作用主要是通过它来驱动Sink Processor,Sink Processor驱动sink来从channel中取数据。
Flume支持将集群内的日志文件采集并归档到HDFS、HBase、Kafka上,供上层应用对数据分析、清洗数据使用。
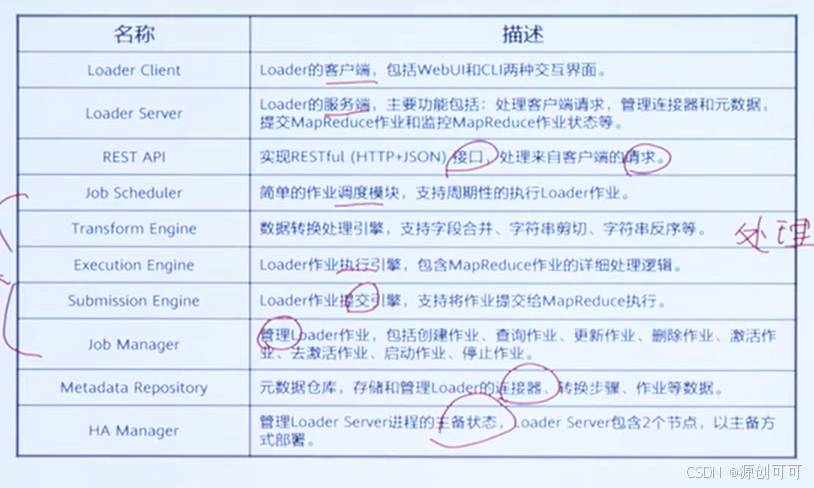
Loader是实现大数据平台与关系型数据库、文件系统之间交换数据和文件的数据加载工
具。提供可视化向导式的作业配置管理界面;提供定时调度任务,周期性执行Loader作
业;在界面中可指定多种不同的数据源、配置数据的清洗和转换步骤、配置集群存储系
统等。
作业用来描述将数据从数据源经过抽取、转换和加载至目的端的过程。
应用场景

特点
Loader Server采用主备双机作业通过MapReduce执行,支持失败重试。作业失败后,不会残留数据
模块架构
Kafka最初是由Linkedin公司开发,是一种分布式,分区的,多副本的,多订阅者,基于zookeeper协调的分布式日志系统
应用场景:日志收集系统和消息系统
分布式消息传递基于可靠的消息队列,在客户端应用和消息系统之间异步传递消息。有两
中主要的消息传递模式:点对点传递模式、发布-订阅模式。大部分的消息系统选用发布-
订阅模式。Kafka就是一种发布-订阅模式。
在点对点消息系统中,消息持久化到一个队列中。
特点
以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间
的访问性能。
高吞吐率。即使在廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
支持消息分区,及分布式消费,同时保证每个分区内消息顺序传输。
同时支持离线数据处理和实时数据处理。
Scale out:支持在线水平扩展
Broker:Kafka集群包含一个或多个服务实例,这些服务实例被称为Broker。
Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic,
Partition:Kafka将Topic分成一个或者多个Partition,每个Partition在物理上对应
一个文件夹,该文件夹下存储这个Partition的所有消息。
Producer:负责发布消息到Kafka Broker.
Consumer:消息消费者,从Kafka Broker读取消息的客户端
Consumer Group:每个Consumer属于一个特定的Consume.Group可为每个
Consumer定group name)
天气作为一个Topic,每天的温度消息就可以存储在“天气”这个存储消息的队列
为了提高Kafka的吞吐量,物理上把Topic分成一个或多个Partition(分区),每个Partition都是有
序且不可变的消息队列。每个Partition在物理上对应一个文件夹,该文件夹下存储这个
Partition的所有消息和索引文件。
每个consumer都属于一个consumer group,每条消息只能被consumer group中的一个Consumer消费,但可以被多个consumer group消费。即组间数据是共享的,组内数据是竞争的。
offset(偏移量)存储机制
Consumer在从broker读取消息后,可以选择commit,该操作会在Kakfa中保存该Consumer在该Partition中读取的消息的offset。该Consumer下一次再读该artition时会从下一条开始读取。通过这一特性可以保证同一消费者从Kafka中不会重复消费数据。
消费者group位移保存在_consumer_offsets的目录上:
计算公式:Math.abs(grouplD.hashCode()%50
kafka-logs目录,里面有多个目录,因为kafka默认会生成50个_consumer_offsets-n目
录
replica:
partition的副本,保障partition的高可用。
leader:
replica中的一个角色,producer和consumer只跟leader交互。
follower:
oreplica中的一个角色,从leader中复制数据。
controller:
kafka集群中的其中一个服务器,用来进行leader election以及各种failover。
日志的清理方式有两种:delete和compact。
目录服务及Ldap基本原理介绍
统一身份认证就类似于游乐园的通存规侧一样,游客可以通过一个通行证(秘钥)来畅玩授权过的游乐项目。
统一身份认证系统的主要功能特性
用户管理
用户认证
单点登录
分级管理
权限管理
会话管理
兼容多种操作系统
统一身份认证系统结构
统一身份认证系统管理模块
统一身份认证服务器
身份信息存储服务器
目录服务是一个为查询、浏览和搜索而优化的服务,其类似于文件目录一样,以树形结构进行数据存储和遍历。
Ldap是轻量目录访问协议
Ldap运行在TCP/IP或其他面向连接的传输服务之上。
Ldap同时是一个IETF标准跟踪协议,在轻量级目录访问协议(Ldap)技术规范路线图RFC4510中被指定。
LdapServer作为目录服务系统,实现了对大数据平台的集中账号管理
LdapServert作为目录服务系统是由目录数据库和一套访问协议组成的系统。
LdapServer基于OpenLDAP开源技术实现
LdapServerl以Berkeley DB作为财认的后数据库。
LdapServer是基于LDAP标准协议的一种具体开源实现。
LdapServer目录树本身就是一种树型结构数据库。传统关系型数据库是将数据一条条记录在表格中,目录树则是将数据存储在节点中,并且该种树形结构可以更好地对应于表格存储模式,其存储模式特点如下:
LdapServer集成设计
Kerberosi这一名词来源于希腊神话“三个头的狗”一一“地狱之门守护者”,后来沿用作为安全认证的概念,该系统设计上采用客户端/服务器结构有DES、AES等加密技术,并且能够进行相互认证,即客户端和服务器端均可对对方进行身份认证。
下面是帮助理解概念的例子
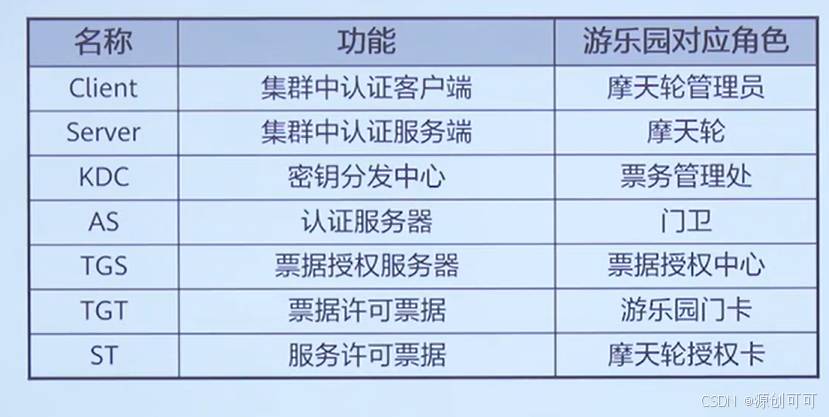
Kerberost作为认证服务器中心,向集群内所有服务以及客户的二次开发应用提供统一的认证服务。
Ldap作为用户数据存储中心,存储了集群内用户的信息,包含密码,附属信息等。
ElasticSearch并不是简单的搜索引擎,同时也提供了NoSQL的存储功能。
ElasticSearch是一个高性能,基于Lucene的全文检索服务,是一个分布式的Restful风格
的搜索和数据分析引擎,也可以作为NoSQL数据库使用。
对Lucene进行了扩展
原型环境和生产环境可无缝切换
能够水平扩展
支持结构化和非结构化数据
应用场景
用于日志搜索和分析、时空检索、时序检索、智能搜索等场景。
检索的数据类型复杂 检索条件多样化 边写边读
生态圈

系统架构

Cluster::代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。
EsNode:ElasticSearch节点,一个节点就是一个ElasticSearch实例。
EsMaster:主节点,可以临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。主节点不参与文档级别的变更或搜索,在流量增长时,该主节在流量增长时,该主节点不会成为集群的瓶颈。
shards:代表索引分片,ElasticSearch可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。
replicas:代表索引副本,ElasticSearch可以设置多个索引的副本,副本的作用一是提高系
统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高
Elasticsearch的查询效率,Elasticsearch会自动对搜索请求进行负载均衡。
recovery:代表数据恢复或叫数据重新分布,Elasticsearch在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
扩容场景:
物理资源消耗过大,即ElasticSearch的服务节点的CPU、内存占用率过高、磁盘空间不足
ElasticSearch单实例的索引数据太大,索引的数目达到10亿条或是数据大小达到1T
扩容方式:
增加EsNode实例
增加节点,在新节点增加EsNode实例
扩容后采用自动均衡策略
减容场景:
减容方式:
在CloudSearch Service管理界面上删除ElasticSearch实例
减容注意事项:
确保要删除的实例上的shard下的replica在其他实例存在
确保要别除的实例上的数据已经迁移到其他节点
Redis是一个基于网络的,高性能key-value内存数据库。
Redis跟memcached类似,不过数据可以持久化,而且支持的数据类型很丰富。
特点
应用场景
架构
无中心自组织的结构,节点之间使用Gossi协议来交换节点状态信息。
各节点维护Key->Server的映射关系。
Client可以向任意节点发起请求,节点不会转发请求,只是重定向Client。
如果在Client第一次请求和重定向请求之间,Cluster(集群)的拓扑发生改变,则第二次重定向请
将被再次重定向,直到找到正确的Server为止。
特性
每个数据库对外都是以一个从0开始的递增数字命名,不支持自定义的
Redis默认支持16个数据库,可以通过修改databases参数来修改这个默认值
Redis默认选择的是0号数据库
SELECT数字:可以切换数据库
多个数据库之间并不是完全隔离的,比如flushall命令范围是所有数据库。
flushall:清空Redis实例下所有数据库的数据
flushdb:清空当前数据库的数据
人工智能的东西涵盖比较多,这里是给临时备考的学生看的,只写了在做题中遇到的知识点,系统性的东西在后续更新。
人工智能的应用方向:计算机视觉 、自然语言处理、语音 处理、智慧城市。
人工智能的三大主要学派:符号主义、连接主义、行为主义。
当前人工智能的发展属于弱人工智能的层次。
人工智能、机器学习、深度学习是相互包含的关系。人工智能包含机器学习,而机器学习又包含深度学习。
按照某种指定的属性特征,划分成两个或多个类别,属于的问题是分类
数据清洗包括:缺失值处理、异常值处理、去除重复、修改格式错误...
随机森林训练子树时,随机选取一批特征进行训练。
集成学习的投票策略可以选择平均法、投票法、堆叠法、最大值法、最小值法
K-Means 是无监督学习算法
文本分类是有监督学习问题
回归模型适用场景:
比如房价预测、气温预测、股票价格预测等。
Conv2D:网络类算子 ControlDepend:控制依赖类算子Softmax:网络类算子
Softmax函数的功能是将一个K维的任意实数向量映射成另一个K维的实数向量。
Softmax输出向量中的每个元素取值都介于[0,1]之间。
Softmax函数经常用作多分类任务的输出层。
Softmax 的输出是一个概率分布,所有元素之和为 1。这是 Softmax 的核心性质。
利用算法自动提取特征。
GPU 的并行计算可以提高效率,但网络参数越多,计算量也会增加,这可能会降低速度。此外,过大的网络可能导致训练时间变长或计算资源不足。
深度学习模型的参数通常没有直接的物理意义,尤其是在深度网络的中间层,参数是经过训练优化出来的权重,主要用于表征抽象特征。
深度学习的一个主要缺点是特征的可解释性较差。相比传统机器学习方法,深度学习更像是一个“黑盒”,难以直接解释模型的特征提取和决策过程。
随机梯度下降(Stochastic Gradient Descent, SGD) 每次更新只使用一个样本,更新方向具有随机性,确实会引起损失函数波动甚至短暂的反向位移。这种不稳定性是 SGD 的固有特性,但也可以帮助模型跳出局部最小值。
批量梯度下降(Batch Gradient Descent, BGD) 是最稳定的梯度下降方法,因为它每次更新都使用所有的训练样本,确保更新方向是全局的。而它的缺点是对大规模数据集的计算代价非常高,训练时间较长。
小批量梯度下降(Mini-Batch Gradient Descent, MBGD) 确实是 SGD 和 BGD 的一种折中方法,每次更新使用一小部分样本(称为 mini-batch),既提高了效率,又减少了波动。但不能说它适合所有数据集,不同任务和数据集可能需要调整方法。
BGD 是最基础的梯度下降方法,每次计算梯度都基于整个训练集。
卷积神经网络(CNN)不仅可以用于处理图像数据,还可以用于处理文本数据。
对于卷积操作,输出图像的大小可以通过以下公式计算:
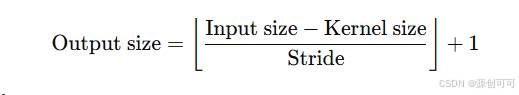
例如
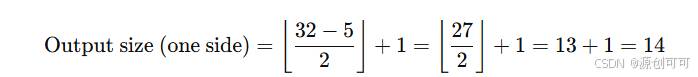
在卷积神经网络中,卷积核的尺寸、池化窗口的大小和步长是独立设计的参数,它们之间没有必须保持一致的要求。
Dropout 是一种正则化技术,用于防止神经网络过拟合。在训练过程中,Dropout 随机丢弃一部分神经元,但并 不是完全丢弃对应的参数
网络的基本单元是 mindspore.nn.Cell
Conv2D 是一个卷积算子,用于卷积操作。
SGD 是一个优化器
ControlDepend 是一个控制依赖算子
Softmax 是一个激活函数算子
MindSpore 支持动静态图的切换,并且 API 设计保持一致性,这是其主要特性之一。
MindInsight 是 MindSpore 的配套工具,用于可视化和调试,帮助用户优化模型性能和提升精度。
MindSpore 支持的数据类型包括 Int、UInt 和 Float。
在 MindSpore 中,使用装饰器 @ms_function 的作用是将 Python 函数转化为静态图(图模式)执行,以提高运行效率。
在昇腾AI芯片中,计算核心被称为AI Core。 AI Core负责执行矩阵、向量和标量等多种类型的计算任务。 其中,矩阵计算由AI Core内的**矩阵计算单元(Cube Unit)**负责。
ModelArts中训练平台支持的开发模式有
云上开发(Codelab)
云上开发(Notebook-+SDK)
本地开发(PyCharm+PyCharm ToolKit)
本地开发(IDE+SDK)
昇腾310处理器可适用于
Atlas200DKAI开发者套件
Atlas500智能小站
Atlas200Al加速模块
Atlas300Al加速卡
华为自动驾驶云服务的关键能力
为保证生成图像的通真程度,在开始训川练时需要一个精确度高的判别器。
在GAN训练中,判别器和生成器是交替训练的,通常在一个训练循环中,先更新判别器的参数,然后更新生成器的参数,而不是固定某一个模型。
强化学习由环境、动作和奖励组成,强化学习的目标是使得作出的一系列决策得到的总的奖励的期望最大化。
华为ict比赛马上要开始了,本文为速成内容,只讲了部分知识点。如果有小伙伴需要系统性学习后期会继续完善内容,有需要的宝宝点赞支持下吧~
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码